Python讀csv文件去掉一列后再寫入新的文件實例
下面小編就為大家分享一篇Python讀csv文件去掉一列后再寫入新的文件實例�����,具有很的參考價值���,希望對大家有所幫助�����。
用了兩種方式解決該問題�,都是網上現有的解決方案�����。
場景說明:
有一個數據文件��,以文本方式保存����,現在有三列user_id,plan_id,mobile_id����。目標是得到新文件只有mobile_id,plan_id���。
解決方案
方案一:用python的打開文件寫文件的方式直接擼一遍數據��,for循環內處理數據并寫入到新文件�。
代碼如下:
def readwrite1( input_file,output_file):
f = open(input_file, 'r')
out = open(output_file,'w')
print (f)
for line in f.readlines():
a = line.split(",")
x=a[0] + "," + a[1]+"\n"
out.writelines(x)
f.close()
out.close()
方案二:用 pandas 讀數據到 DataFrame 再做數據分割��,直接用 DataFrame 的寫入功能寫到新文件
代碼如下:
def readwrite2(input_file,output_file): date_1=pd.read_csv(input_file,header=0,sep=',') date_1[['mobile', 'plan_id']].to_csv(output_file, sep=',', header=True,index=False)
從代碼上看�����,pandas邏輯更清晰�����。
下面看下執行的效率吧��!
def getRunTimes( fun ,input_file,output_file):
begin_time=int(round(time.time() * 1000))
fun(input_file,output_file)
end_time=int(round(time.time() * 1000))
print("讀寫運行時間:",(end_time-begin_time),"ms")
getRunTimes(readwrite1,input_file,output_file) #直接擼數據
getRunTimes(readwrite2,input_file,output_file1) #使用dataframe讀寫數據
讀寫運行時間: 976 ms
讀寫運行時間: 777 ms
input_file 大概有27萬的數據���,dataframe的效率比for循環效率還是要快一點的���,如果數據量更大些����,效果是否更明顯呢�?
下面試下增加input_file記錄的數量試試���,有如下結果
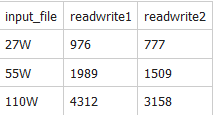
從上面測試結果來看,dataframe的效率提高大約30%左右���。
以上這篇Python讀csv文件去掉一列后再寫入新的文件實例就是小編分享給大家的全部內容了
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
