python決策樹之CART分類回歸樹詳解
決策樹之CART(分類回歸樹)詳解���,具體內容如下
1��、CART分類回歸樹簡介
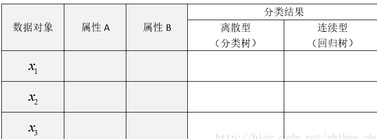
CART分類回歸樹是一種典型的二叉決策樹��,可以處理連續型變量和離散型變量��。如果待預測分類是離散型數據���,則CART生成分類決策樹��;如果待預測分類是連續型數據��,則CART生成回歸決策樹���。數據對象的條件屬性為離散型或連續型�,并不是區別分類樹與回歸樹的標準����,例如表1中�����,數據對象xi的屬性A�����、B為離散型或連續型���,并是不區別分類樹與回歸樹的標準�����。
表1
2���、CART分類回歸樹分裂屬性的選擇
2.1 CART分類樹——待預測分類為離散型數據
選擇具有最小Gain_GINI的屬性及其屬性值���,作為最優分裂屬性以及最優分裂屬性值�。Gain_GINI值越小�����,說明二分之后的子樣本的“純凈度”越高���,即說明選擇該屬性(值)作為分裂屬性(值)的效果越好���。
??對于樣本集S��,GINI計算如下:
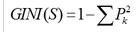
其中��,在樣本集S中�,Pk表示分類結果中第k個類別出現的頻率���。
對于含有N個樣本的樣本集S�,根據屬性A的第i個屬性值����,將數據集S劃分成兩部分���,則劃分成兩部分之后����,Gain_GINI計算如下:
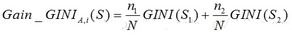
其中��,n1�、n2分別為樣本子集S1�、S2的樣本個數���。
對于屬性A����,分別計算任意屬性值將數據集劃分成兩部分之后的Gain_GINI����,選取其中的最小值�,作為屬性A得到的最優二分方案:
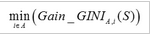
對于樣本集S����,計算所有屬性的最優二分方案�����,選取其中的最小值���,作為樣本集S的最優二分方案:

所得到的屬性A及其第i屬性值�,即為樣本集S的最優分裂屬性以及最優分裂屬性值�����。
2.2 CART回歸樹——待預測分類為連續型數據
區別于分類樹�����,回歸樹的待預測分類為連續型數據��。同時�,區別于分類樹選取Gain_GINI為評價分裂屬性的指標���,回歸樹選取Gain_σ為評價分裂屬性的指標��。選擇具有最小Gain_σ的屬性及其屬性值�����,作為最優分裂屬性以及最優分裂屬性值���。Gain_σ值越小���,說明二分之后的子樣本的“差異性”越小���,說明選擇該屬性(值)作為分裂屬性(值)的效果越好���。
針對含有連續型分類結果的樣本集S��,總方差計算如下:
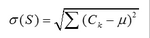
其中�����,μ表示樣本集S中分類結果的均值��,Ck表示第k個分類結果��。
對于含有N個樣本的樣本集S����,根據屬性A的第i個屬性值�����,將數據集S劃分成兩部分����,則劃分成兩部分之后�����,Gain_σ計算如下:
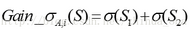
對于屬性A�,分別計算任意屬性值將數據集劃分成兩部分之后的Gain_σ�����,選取其中的最小值�,作為屬性A得到的最優二分方案:
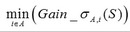
對于樣本集S��,計算所有屬性的最優二分方案����,選取其中的最小值�����,作為樣本集S的最優二分方案:

所得到的屬性A及其第i屬性值����,即為樣本集S的最優分裂屬性以及最優分裂屬性值���。
3���、CART分類回歸樹的剪枝
由于決策樹的建立完全是依賴于訓練樣本�,因此該決策樹對訓練樣本能夠產生完美的擬合效果���。但這樣的決策樹對于測試樣本來說過于龐大而復雜����,可能產生較高的分類錯誤率���。這種現象就稱為過擬合�����。因此需要將復雜的決策樹進行簡化�����,即去掉一些節點解決過擬合問題��,這個過程稱為剪枝��。
剪枝方法分為預剪枝和后剪枝兩大類����。預剪枝是在構建決策樹的過程中����,提前終止決策樹的生長�,從而避免過多的節點產生����。預剪枝方法雖然簡單但實用性不強���,因為很難精確的判斷何時終止樹的生長���。后剪枝是在決策樹構建完成之后����,對那些置信度不達標的節點子樹用葉子結點代替���,該葉子結點的類標號用該節點子樹中頻率最高的類標記��。后剪枝方法又分為兩種��,一類是把訓練數據集分成樹的生長集和剪枝集�����;另一類算法則是使用同一數據集進行決策樹生長和剪枝����。常見的后剪枝方法有CCP(Cost
Complexity Pruning)��、REP(Reduced Error Pruning)�、PEP(Pessimistic Error
Pruning)�����、MEP(Minimum Error Pruning)��。其中���,悲觀錯誤剪枝法PEP(Pessimistic Error
Pruning)在“決策樹之C4.5算法詳解”中有詳細介紹�����,感興趣的小童鞋可以了解學習��。這里我們詳細介紹CART分類回歸樹中應用最廣泛的剪枝算法——代價復雜性剪枝法CCP(Cost Complexity Pruning)����。
代價復雜性剪枝法CCP(Cost Complexity Pruning)主要包含兩個步驟:(1)從原始決策樹T0開始生成一個子樹序列{T0,T1,...,Tn}�����,其中��,Ti+1從Ti產生�����,Tn為根節點��。(2)從第1步產生的子樹序列中���,根據樹的真實誤差估計選擇最佳決策樹�����。
CCP剪枝法步驟(1)
生成子樹序列{T0,T1,...,Tn}的基本思想是從T0開始�����,裁剪Ti中關于訓練數據集誤差增加最小的分枝來得到Ti+1�����。實際上����,當1棵樹T在節點t處剪枝時��,它的誤差增加直觀上認為是R(t)?R(Tt)��,其中�,R(t)為在節點t的子樹被裁剪后節點t的誤差�,R(Tt)為在節點t的子樹沒被裁剪時子樹Tt的誤差���。然而��,剪枝后�����,T的葉子數減少了L(Tt)?1�����,其中����,L(Tt)為子樹Tt的葉子數���,也就是說���,T的復雜性減少了���。因此���,考慮樹的復雜性因素���,樹分枝被裁剪后誤差增加率由下式決定:
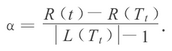
其中��,R(t)表示節點t的子樹被裁剪后節點t的誤差���,R(t)=r(t)?p(t)���,r(t)是節點t的誤差率�,p(t)是節點t上的樣本個數與訓練集中樣本個數的比例����。R(Tt)表示節點t的子樹沒被裁剪時子樹Tt的誤差����,即子樹Tt上所有葉子節點的誤差之和���。
Ti+1就是選擇Ti中具有最小α值所對應的剪枝樹����。
例如:圖1中ti表示決策樹中第i個節點��,A���、B表示訓練集中的兩個類別�����,A�����、B之后的數據表示落入該節點分別屬于A類�����、B類的樣本個數�����。
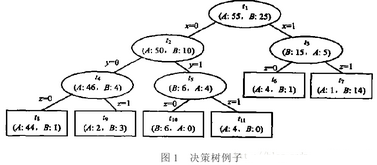
圖1���,決策樹中訓練樣本總個數為80���。對于節點t4�,其中��,A類樣本46個�,B類樣本4個�����,根據大多數原則�,則節點t4中樣本為A類����,故節點t4的子樹(t8�����、t9)被裁剪之后t4的誤差為:450?5080=480��。節點t4的子樹(t8����、t9)被裁剪之前t4的誤差為:145?4580+25?580=380���。故α(t4)=480?3802?1=0.0125����。類似過程��,依次得到所有節點的誤差增加率��,如表2:
表2

從表2可以看出��,在原始樹T0行�,4個非葉節點中t4的α值最小���,因此����,裁剪T0的t4節點的分枝得到T1�;在T1行�,雖然t2和t3的α值相同���,但裁剪t2的分枝可以得到更小的決策樹��,因此���,T2是裁剪T1中的t2分枝得到的����。
CCP剪枝法步驟(2)
如何根據第1步產生的子樹序列{T0,T1,...,Tn}��,選擇出1棵最佳決策樹是CCP剪枝法步驟(2)的關鍵�。通常采用的方法有兩種����,一種是V番交叉驗證(V-fold cross-validation)���,另一種是基于獨立剪枝數據集���。此處不在過分贅述����,感興趣的小童鞋���,可以閱讀參考文獻[1][2][3]等�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
