深入理解python多進程編程
1���、python多進程編程背景
python中的多進程最大的好處就是充分利用多核cpu的資源��,不像python中的多線程�����,受制于GIL的限制�����,從而只能進行cpu分配���,在python的多進程中���,適合于所有的場合���,基本上能用多線程的��,那么基本上就能用多進程��。
在進行多進程編程的時候�,其實和多線程差不多�,在多線程的包threading中��,存在一個線程類Thread���,在其中有三種方法來創建一個線程�����,啟動線程����,其實在多進程編程中�,存在一個進程類Process�,也可以使用那集中方法來使用�����;在多線程中���,內存中的數據是可以直接共享的��,例如list等�,但是在多進程中���,內存數據是不能共享的�,從而需要用單獨的數據結構來處理共享的數據�;在多線程中��,數據共享�,要保證數據的正確性����,從而必須要有所�����,但是在多進程中���,鎖的考慮應該很少���,因為進程是不共享內存信息的���,進程之間的交互數據必須要通過特殊的數據結構����,在多進程中�,主要的內容如下圖:
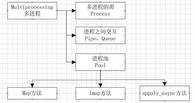
2��、多進程的類Process
多進程的類Process和多線程的類Thread差不多的方法����,兩者的接口基本相同��,具體看以下的代碼:
frommultiprocessingimportProcess
importos
importtime
deffunc(name):
print'start a process'
time.sleep(3)
print'the process parent id :',os.getppid()
print'the process id is :',os.getpid()
if__name__=='__main__':
processes=[]
foriinrange(2):
p=Process(target=func,args=(i,))
processes.append(p)
foriinprocesses:
i.start()
print'start all process'
foriinprocesses:
i.join()
#pass
print'all sub process is done!'
在上面例子中可以看到���,多進程和多線程的API接口是一樣一樣的��,顯示創建進程��,然后進行start開始運行����,然后join等待進程結束�。
在需要執行的函數中�,打印出了進程的id和pid��,從而可以看到父進程和子進程的id號���,在linu中����,進程主要是使用fork出來的�����,在創建進程的時候可以查詢到父進程和子進程的id號�,而在多線程中是無法找到線程的id����,執行效果如下:
startallprocess
start a process
start a process
the process parentid:8036
the process parentid:8036
the processidis:8037
the processidis:8038
allsub processisdone!
在操作系統中查詢的id的時候��,最好用pstree���,清晰:
├─sshd(1508)─┬─sshd(2259)───bash(2261)───python(7520)─┬─python(7521)
│ │ ├─python(7522)
│ │ ├─python(7523)
│ │ ├─python(7524)
│ │ ├─python(7525)
│ │ ├─python(7526)
│ │ ├─python(7527)
│ │ ├─python(7528)
│ │ ├─python(7529)
│ │ ├─python(7530)
│ │ ├─python(7531)
│ │ └─python(7532)
在進行運行的時候��,可以看到����,如果沒有join語句���,那么主進程是不會等待子進程結束的����,是一直會執行下去�����,然后再等待子進程的執行���。
在多進程的時候�,說����,我怎么得到多進程的返回值呢�?然后寫了下面的代碼:
importmultiprocessing
classMyProcess(multiprocessing.Process):
def__init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name=name
self.func=func
self.args=args
self.res=''
defrun(self):
self.res=self.func(*self.args)
printself.name
printself.res
return(self.res,'kel')
deffunc(name):
print'start process...'
returnname.upper()
if__name__=='__main__':
processes=[]
result=[]
foriinrange(3):
p=MyProcess('process',func,('kel',))
processes.append(p)
foriinprocesses:
i.start()
foriinprocesses:
i.join()
foriinprocesses:
result.append(i.res)
foriinresult:
printi
嘗試從結果中返回值���,從而在主進程中得到子進程的返回值����,然而�����,���,���,并沒有結果��,后來一想����,在進程中��,進程之間是不共享內存的
����,那么使用list來存放數據顯然是不可行的����,進程之間的交互必須依賴于特殊的數據結構��,從而以上的代碼僅僅是執行進程�����,不能得到進程的返回值�����,但是以上代碼修改為線程��,那么是可以得到返回值的��。
3�、進程間的交互Queue
進程間交互的時候�����,首先就可以使用在多線程里面一樣的Queue結構�,但是在多進程中�,必須使用multiprocessing里的Queue���,代碼如下:
importmultiprocessing
classMyProcess(multiprocessing.Process):
def__init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name=name
self.func=func
self.args=args
self.res=''
defrun(self):
self.res=self.func(*self.args)
deffunc(name,q):
print'start process...'
q.put(name.upper())
if__name__=='__main__':
processes=[]
q=multiprocessing.Queue()
foriinrange(3):
p=MyProcess('process',func,('kel',q))
processes.append(p)
foriinprocesses:
i.start()
foriinprocesses:
i.join()
whileq.qsize() >0:
printq.get()
其實這個是上面例子的改進��,在其中��,并沒有使用什么其他的代碼���,主要就是使用Queue來保存數據�����,從而可以達到進程間交換數據的目的�����。
在進行使用Queue的時候���,其實用的是socket���,感覺���,因為在其中使用的還是發送send����,然后是接收recv�����。
在進行數據交互的時候����,其實是父進程和所有的子進程進行數據交互���,所有的子進程之間基本是沒有交互的��,除非���,但是���,也是可以的����,例如��,每個進程去Queue中取數據�����,但是這個時候應該是要考慮鎖��,不然可能會造成數據混亂���。
4�、 進程之間交互Pipe
在進程之間交互數據的時候還可以使用Pipe�����,代碼如下:
importmultiprocessing
classMyProcess(multiprocessing.Process):
def__init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name=name
self.func=func
self.args=args
self.res=''
defrun(self):
self.res=self.func(*self.args)
deffunc(name,q):
print'start process...'
child_conn.send(name.upper())
if__name__=='__main__':
processes=[]
parent_conn,child_conn=multiprocessing.Pipe()
foriinrange(3):
p=MyProcess('process',func,('kel',child_conn))
processes.append(p)
foriinprocesses:
i.start()
foriinprocesses:
i.join()
foriinprocesses:
printparent_conn.recv()
在以上代碼中���,主要是使用Pipe中返回的兩個socket來進行傳輸和接收數據����,在父進程中�,使用的是parent_conn�����,在子進程中使用的是child_conn�����,從而子進程發送數據的方法send����,而在父進程中進行接收方法recv
最好的地方在于���,明確的知道收發的次數����,但是如果某個出現異常����,那么估計pipe不能使用了�����。
5���、進程池pool
其實在使用多進程的時候�����,感覺使用pool是最方便的�,在多線程中是不存在pool的���。
在使用pool的時候��,可以限制每次的進程數�����,也就是剩余的進程是在排隊����,而只有在設定的數量的進程在運行���,在默認的情況下�����,進程是cpu的個數���,也就是根據multiprocessing.cpu_count()得出的結果�����。
在poo中�����,有兩個方法����,一個是map一個是imap�����,其實這兩方法超級方便�,在執行結束之后���,可以得到每個進程的返回結果�����,但是缺點就是每次的時候�,只能有一個參數��,也就是在執行的函數中�����,最多是只有一個參數的�,否則�,需要使用組合參數的方法�,代碼如下所示:
importmultiprocessing
deffunc(name):
print'start process'
returnname.upper()
if__name__=='__main__':
p=multiprocessing.Pool(5)
printp.map(func,['kel','smile'])
foriinp.imap(func,['kel','smile']):
printi
在使用map的時候�����,直接返回的一個是一個list����,從而這個list也就是函數執行的結果�����,而在imap中��,返回的是一個由結果組成的迭代器���,如果需要使用多個參數的話�,那么估計需要*args�����,從而使用參數args���。
在使用apply.async的時候����,可以直接使用多個參數���,如下所示:
importmultiprocessing
importtime
deffunc(name):
print'start process'
time.sleep(2)
returnname.upper()
if__name__=='__main__':
results=[]
p=multiprocessing.Pool(5)
foriinrange(7):
res=p.apply_async(func,args=('kel',))
results.append(res)
foriinresults:
printi.get(2.1)
在進行得到各個結果的時候�,注意使用了一個list來進行append����,要不然在得到結果get的時候會阻塞進程����,從而將多進程編程了單進程��,從而使用了一個list來存放相關的結果��,在進行得到get數據的時候���,可以設置超時時間��,也就是get(timeout=5)���,這種設置���。
總結:
在進行多進程編程的時候����,注意進程之間的交互�����,在執行函數之后��,如何得到執行函數的結果���,可以使用特殊的數據結構�����,例如Queue或者Pipe或者其他��,在使用pool的時候����,可以直接得到結果����,map和imap都是直接得到一個list和可迭代對象���,而apply_async得到的結果需要用一個list裝起來�����,然后得到每個結果�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
