數據挖掘之KNN分類
分類算法有很多���,貝葉斯��、決策樹��、支持向量積����、KNN等���,神經網絡也可以用于分類�。這篇文章主要介紹一下KNN分類算法��。
1���、介紹
KNN是k
nearest neighbor
的簡稱���,即k最鄰近��,就是找k個最近的實例投票決定新實例的類標����。KNN是一種基于實例的學習算法���,它不同于貝葉斯����、決策樹等算法����,KNN不需要訓練����,當有新的實例出現時�,直接在訓練數據集中找k個最近的實例�,把這個新的實例分配給這k個訓練實例中實例數最多類����。KNN也成為懶惰學習����,它不需要訓練過程�����,在類標邊界比較整齊的情況下分類的準確率很高���。KNN算法需要人為決定K的取值����,即找幾個最近的實例���,k值不同��,分類結果的結果也會不同���。
2��、舉例
看如下圖的訓練數據集的分布��,該數據集分為3類(在圖中以三種不同的顏色表示)�,現在出現一個待分類的新實例(圖中綠色圓點)�,假設我們的K=3����,即找3個最近的實例���,這里的定義的距離為歐氏距離��,這樣找據該待分類實例最近的三個實例就是以綠點為中心畫圓�,確定一個最小的半徑�,使這個圓包含K個點�����。
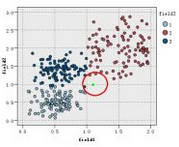
如圖所示�,可以看到紅圈包含的三個點中����,類別2中有三個�,類別3有一個����,而類別1一個也沒有���,根據少數服從多數的原理投票����,這個綠色的新實例應屬于2類�����。
3��、K值的選取�。
之前說過����,K值的選取��,將會影響分類的結果�����,那么K值該取多少合理����。我們繼續上面提到的分類過程�����,現在我們把K設置為為7����,如下圖所示:
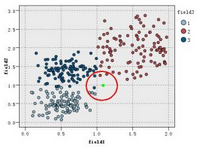
可以看到當k=7時�����,最近的7個點中1類有三個����,2類和3類都有兩個��,這時綠色的新實例應該分給1類�,這與K=5時的分類結果不同�����。
K值的選取沒有一個絕對的標準�����,但可以想象�,K取太大并不能提高正確率����,而且求K個最近的鄰居是一個O(K*N)復雜度的算法�,k太大���,算法效率會更低�����。
雖然說K值的選取�,會影響結果�,有人會認為這個算法不穩定�����,其實不然�����,這種影響并不是很大�,因為只有這種影響只是在類別邊界上產生影響�,而在類中心附近的實例影響很小��,看下圖����,對于這樣的一個新實例����,k=3,k=5,k=11結果都是一樣的�。
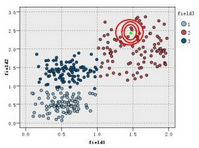
最后還有注意�����,在數據集不均衡的情況下��,可能需要按各類的比例決定投票����,這樣小類的正確率才不會過低���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
