機器學習幾個重要概念
統計學習的算法可以分為以下幾個類別:監督學習��、非監督學習����、半監督學習以及強化學習�����。
監督學習的輸入數據都有對應的類標簽或是一個輸出值�����,其任務是學習一個模型��,使模型能夠對任意給定的輸入����,對其相應的輸出做出一個好的預測�����。
非監督學習就是沒有對應的類標簽或是輸出值����。學習中并沒有任何標準來告訴你�,某個概念是否正確���,需要學習器自身形成和評價概念����。就是自動地從數據中挖掘出結構信息或是抽取出一些規則�����。近年來����,非監督學習被認為是解決一些重要問題的突破口所在��。因為科學的產生就是人類中無監督學習的最佳案例����。
半監督學習就是介于監督學習和非監督學習之間��。這在最近的研究領域也是被大家所熱烈探討的�����,因為對于現實數據來說���,有標簽的數據總是少量的��,往往都需要人工來進行標注����。而無標簽數據是能夠大量獲得的�。
增強學習強調如何基于環境而行動��,以取得最大化的預期利益��。其靈感來源于心理學中的行為主義理論�����,即有機體如何在環境給予的獎勵或懲罰的刺激下�,逐步形成對刺激的預期�����,產生能獲得最大利益的習慣性行為��。強化學習和標準的監督式學習之間的區別在于����,它并不需要出現正確的輸入/輸出對��,也不需要精確校正次優化的行為����。(以上內容摘自維基百科)這在機器人���、無人機領域中應用的還是非常廣泛的�。
在線學習與離線學習
對于機器學習算法的分類�,站在不同的角度就能有不同的分類方法�����。在具體的應用中還有一種常用的分類方法是:在線學習與離線學習����。
在線學習���,是在獲取到新的數據后就能夠輸入到模型中進行學習���。這需要學習算法能夠在處于任何狀態時都能進行參數的更新���。而且需要算法對噪聲數據有很好的魯棒性����。
離線學習就正好與在線學習相反�����,當數據有更新時��,需要將其與原來的數據一起對模型的參數進行重新地訓練����。這時�,整個訓練的過程能夠被很好的控制�,因為所有的數據都是已知的���,能夠對數據進行細致的預處理過程�。
生成模型與判別模型
這種分類方式是針對于監督學習來進行分類的�。這個在我騰訊面試的時候還被問到過這個問題�。
生成模型
生成方法由數據學習聯合概率分布P(X,Y)
����,然后求出條件概率分布P(Y|X)
作為預測的模型����,即生成模型:
模型表示了給定輸入X產生輸出Y的生成關系�����。典型的生成模型有:樸素貝葉斯方法和隱馬爾可夫模型����。
生成模型能夠還原出聯合概率分布P(X,Y)
���;生成模型的收斂速度快����,當樣本容量增加的時候����,學到的模型可以更快地收斂于真實模型����;當存在隱變量時��,仍可以使用生成學習方法�����,此時判別方法就不能用����。
判別模型
判別方法由數據直接學習決策函數f(x)
或者條件概率分布P(Y|X)
作為預測的模型��,即判別模型�。典型的判別模型包括:k近鄰法����、感知機��、決策樹��、logistic回歸模型�、最大熵模型���、支持向量機����、提升方法和條件隨機場��。
判別模型直接面對預測�����,往往學習的準確率越高�?����?梢詫祿M行各種程度上的抽象����、定義特征并使用特征����,因此可以簡化學習問題���。
算法的歸納偏好
機器學習算法在學習過程中對某種類型假設的偏好稱為『歸納偏好』�����。這個『假設』包含了一個算法方方面面的內容�。
任何一個有效的機器學習算法必有其歸納的偏好��,否則它將被假設空間中看似在訓練集上『等效』的假設所迷惑��,而無法產生確定的學習結果����。例如在分類問題中�,如果隨機抽選訓練集上等效的假設(可以認為所有的正反例并沒有區別)�,那么它的分類結果其實是不確定的����,這要根據它所選取的樣本來決定����,這樣的學習顯然是沒有意義的��。
歸納偏好對應了學習算法本身所做出的關于『什么樣的模型更好』的假設�。在具體的問題中�,這個假設是否成立�,即算法的歸納偏好是否與問題本身匹配�,大多數時候直接決定了算法能否取得好的性能����。
『奧卡姆剃刀』就是一個常用的原則���,『若有多個假設與觀察一致����,則選擇最簡單的那個』��。對于一些以簡潔為美的人來說是再正確不過了���。在一些工程技術中有一些問題也確實是這樣���,一個較為簡單的方法所取得的效果雖然不是最好����,但是它的代價與其效果之比已然是最優�。
對于一個線性回歸問題�����,如下圖所示:
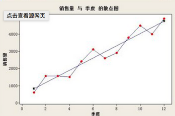
根據『奧卡姆剃刀』原則��,你肯定會選擇中間那條經過回歸處理之后的直線作為之后預測的標準�。在一些場景下���,這樣選擇自然是正確的����。如果再給你更多的數據點����,你發現這些點正好是在穿過所有紅色點的曲線之上�����,你還會選擇那條回歸的直線嗎�����?這就牽扯出一個非常有意思的定理��,『沒有免費的午餐』���。
這個定理所描述的是��,對于任意兩個學習算法A和B�����,它們在任意分布數據上的誤差其實是相等的�。仔細想想的話確實是那么回事���。這個定理有一個重要的前提:所有問題出現的機會相同或是所有問題都是同等重要的�����。
這時候你肯定會有疑問���,既然所有的學習算法的期望性能都和隨機猜測差不多�,那學習的過程豈不是并沒有什么用���。注意到一點�,上面所說的相等是在所有數據的分布之下��,但是我們所處理的問題的數據往往是某一特定分布的�。
欠擬合與過擬合
當目標函數給定時�����,基于目標函數的模型訓練誤差和模型測試誤差就自然成為學習方法的評估標準��。注意�,學習方法具體采用的目標函數未必是評估時所使用的標準���。關于評估標準這一問題會在之后的博客中提到����。
假設學習到的模型是Y=f^(x)
�,訓練誤差是模型關于訓練數據數據集的平均損失:
其中N是訓練樣本容量���。
測試誤差是模型關于測試數據集的平均損失:
其中N’是測試樣本容量��。
通常將學習方法對未知數據的預測能力稱為泛化能力����。顯然�����,我們希望得到泛化誤差小的學習器���。然而����,事先我們并不知道新樣本是什么樣的��,實際能做的是努力使在訓練集上的誤差最小化����。
如果一味追求提高對訓練數據的預測能力����,所選模型的復雜度往往會比真模型要高���。這種現象稱為過擬合���。過擬合是指學習時選擇的模型包含參數過多��,以致于出現這一模型對已知數據預測的很好�����,但對未知數據預測得很差的現象����。與過擬合相對的是欠擬合��,這是指對訓練樣本的一般性質尚未學好���。
欠擬合比較容易克服�����,一般只需要增加訓練的次數��。而過擬合是機器學習面臨的關鍵障礙���,各類學習算法都必然帶有一些針對過擬合的措施����;然而必須認識到��,過擬合是無法徹底避免的��,我們所能做的只是緩解����。這是因為�����,機器學習面臨的問題一般是NP難甚至是更難的�,而有效的學習算法必然是在多項式時間內完成的���。若可以徹底避免過擬合�����,這就意味著我們構造性地證明了『NP
= P』���,那么你就可以獲得圖靈獎了���。只要相信『P != NP』��,過擬合就無法避免��。
關于過擬合與欠擬合圖形化的解釋�����,下面那張圖中有具體說明���。
方差與偏差
偏差方差-分解試圖對學習算法的期望泛化誤差進行分解�。推導的過程這里就不寫了��,直接給出公式����。
這個式子表示的是泛化誤差可以分解為偏差�、方差與噪聲之和���。偏差度量了學習算法的期望預測與真實結果的偏離程度��,即刻畫了學習算法本身的擬合能力���。為什么一個算法會有偏差呢�����,下面這句話給出了答案:
Biases are introduced by the generalizations made in the model
including the configuration of the model and the selection of the
algorithm to generate the model.
我個人的理解是��,因為對于算法的選擇乃至于調整參數方法的選擇導致了算法是有偏差的����。因為算法的選擇中就蘊含著偏好��。
方差度量了同樣大小的訓練集的變動所導致的學習性能的變化����,即刻畫了數據擾動所造成的影響��;噪聲則表達了在當前任務上任何學習算法所能到達的期望泛化誤差的下界�,即刻畫了問題本身的難度�����。
泛化能力是由學習算法的能力���、數據的充分性以及學習任務本身的難度所共同決定的�����。給定學習任務��,為了取得好的泛化性能��,則需使偏差較小����,即能充分擬合數據�,并且使方差較小�����,即使得數據擾動產生的影響小�。
但偏差與方差是不能同時達到最優的��,這稱為偏差方差窘境��。
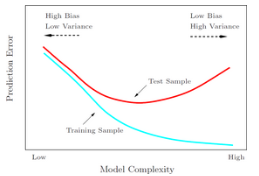
這個圖所表達的含義相信不用過多地解釋了吧��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情��;

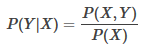
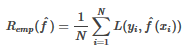
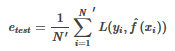
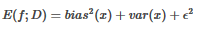










 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
