1.AI人工智能 Artificial Intelligence
人工智能(Artificial Intelligence)�,英文縮寫為AI��。它是研究�、開發用于模擬�����、延伸和擴展人的智能的理論�����、方法�����、技術及應用系統的一門新的技術科學����。
人工智能是計算機科學的一個分支��,它企圖了解智能的實質����,并生產出一種新的能以人類智能相似的方式做出反應的智能機器���,該領域的研究包括機器人�����、語言識別�、圖像識別���、自然語言處理和專家系統等��。人工智能從誕生以來��,理論和技術日益成熟�,應用領域也不斷擴大�����,可以設想�,未來人工智能帶來的科技產品�,將會是人類智慧的“容器”�����。人工智能可以對人的意識�����、思維的信息過程的模擬���。人工智能不是人的智能��,但能像人那樣思考�、也可能超過人的智能����。
人工智能是一門極富挑戰性的科學���,從事這項工作的人必須懂得計算機知識�����,心理學和哲學���。人工智能是包括十分廣泛的科學�,它由不同的領域組成�,如機器學習���,計算機視覺等等�,總的說來�,人工智能研究的一個主要目標是使機器能夠勝任一些通常需要人類智能才能完成的復雜工作����。但不同的時代�����、不同的人對這種“復雜工作”的理解是不同的�。2017年12月��,人工智能入選“2017年度中國媒體十大流行語”��。
2.區塊鏈 blockchain

狹義來講���,區塊鏈是一種按照時間順序將數據區塊以順序相連的方式組合成的一 種鏈式數據結構��, 并以密碼學方式保證的不可篡改和不可偽造的分布式賬本�。廣義來講�,區塊鏈技術是利用塊鏈式數據結構來驗證與存儲數據��、利用分布式節點共識算法來生成和更新數據���、利用密碼學的方式保證數據傳輸和訪問的安全�����、利用由自動化腳本代碼組成的智能合約來編程和操作數據的一種全新的分布式基礎架構與計算范式�����。
3.圖靈測試 The Turing test
圖靈測試(The Turing test)由艾倫·麥席森·圖靈發明�����,指測試者與被測試者(一個人和一臺機器)隔開的情況下��,通過一些裝置(如鍵盤)向被測試者隨意提問��。
進行多次測試后�����,如果有超過30%的測試者不能確定出被測試者是人還是機器�,那么這臺機器就通過了測試����,并被認為具有人類智能��。圖靈測試一詞來源于計算機科學和密碼學的先驅阿蘭·麥席森·圖靈寫于1950年的一篇論文《計算機器與智能》�,其中30%是圖靈對2000年時的機器思考能力的一個預測�����,目前我們已遠遠落后于這個預測��。
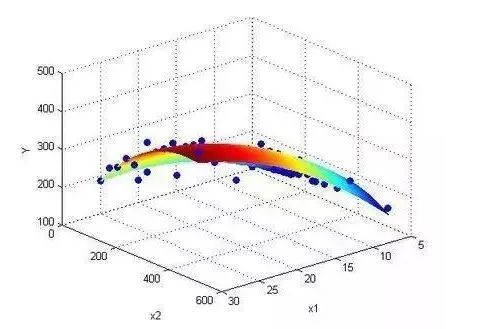
4.回歸分析 regression analysis
回歸分析(regression
analysis)是確定兩種或兩種以上變量間相互依賴的定量關系的一種統計分析方法��。運用十分廣泛��,回歸分析按照涉及的變量的多少���,分為一元回歸和多元回歸分析�����;按照因變量的多少����,可分為簡單回歸分析和多重回歸分析����;按照自變量和因變量之間的關系類型�����,可分為線性回歸分析和非線性回歸分析���。如果在回歸分析中�����,只包括一個自變量和一個因變量��,且二者的關系可用一條直線近似表示��,這種回歸分析稱為一元線性回歸分析����。如果回歸分析中包括兩個或兩個以上的自變量���,且自變量之間存在線性相關�����,則稱為多重線性回歸分析���。
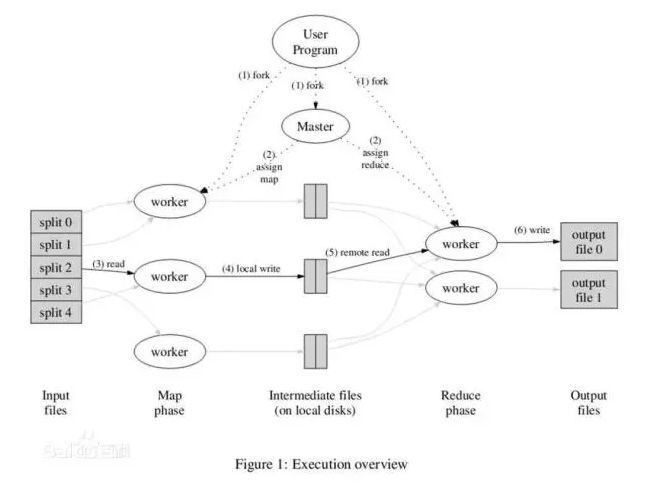
5.MapReduce
MapReduce是一種編程模型���,用于大規模數據集(大于1TB)的并行運算��。概念"Map(映射)"和"Reduce(歸約)"�,是它們的主要思想�,都是從函數式編程語言里借來的��,還有從矢量編程語言里借來的特性�。它極大地方便了編程人員在不會分布式并行編程的情況下��,將自己的程序運行在分布式系統上�。 當前的軟件實現是指定一個Map(映射)函數���,用來把一組鍵值對映射成一組新的鍵值對����,指定并發的Reduce(歸約)函數���,用來保證所有映射的鍵值對中的每一個共享相同的鍵組����。
6.貪心算法
貪心算法(又稱貪婪算法)是指�����,在對問題求解時�����,總是做出在當前看來是最好的選擇�����。也就是說�����,不從整體最優上加以考慮��,他所做出的是在某種意義上的局部最優解�。
貪心算法不是對所有問題都能得到整體最優解����,關鍵是貪心策略的選擇����,選擇的貪心策略必須具備無后效性���,即某個狀態以前的過程不會影響以后的狀態�,只與當前狀態有關�。
貪心算法的基本思路是從問題的某一個初始解出發一步一步地進行��,根據某個優化測度���,每一步都要確保能獲得局部最優解���。每一步只考慮一個數據����,他的選取應該滿足局部優化的條件���。若下一個數據和部分最優解連在一起不再是可行解時�,就不把該數據添加到部分解中�,直到把所有數據枚舉完����,或者不能再添加算法停止 ����。
7.數據挖掘
數據挖掘(英語:Data mining)��,又譯為資料探勘�、數據采礦���。它是數據庫知識發現(英語:Knowledge-Discovery in Databases��,簡稱:KDD)中的一個步驟����。數據挖掘一般是指從大量的數據中通過算法搜索隱藏于其中信息的過程����。數據挖掘通常與計算機科學有關����,并通過統計�����、在線分析處理����、情報檢索���、機器學習����、專家系統(依靠過去的經驗法則)和模式識別等諸多方法來實現上述目標�。
8.數據可視化
數據可視化�����,是關于數據視覺表現形式的科學技術研究����。其中�,這種數據的視覺表現形式被定義為��,一種以某種概要形式抽提出來的信息�����,包括相應信息單位的各種屬性和變量�����。
它是一個處于不斷演變之中的概念����,其邊界在不斷地擴大���。主要指的是技術上較為高級的技術方法�,而這些技術方法允許利用圖形���、圖像處理�����、計算機視覺以及用戶界面����,通過表達�����、建模以及對立體�、表面����、屬性以及動畫的顯示��,對數據加以可視化解釋���。與立體建模之類的特殊技術方法相比��,數據可視化所涵蓋的技術方法要廣泛得多���。
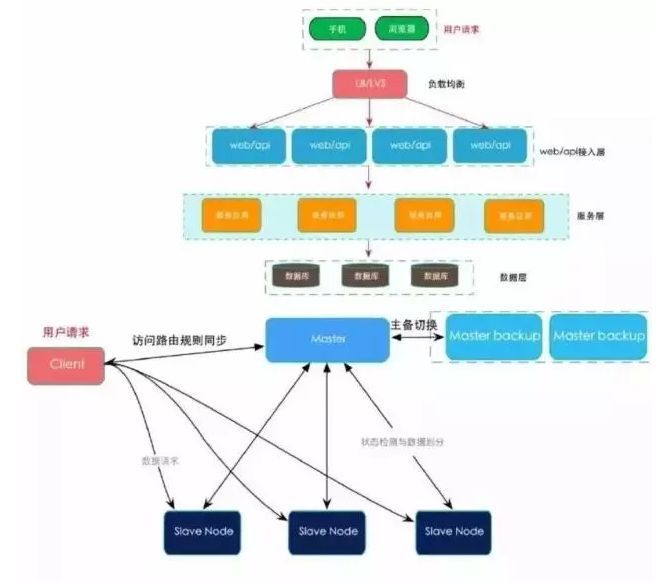
9.分布式計算 Distributed computing
在計算機科學中����,分布式計算(英語:Distributed computing���,又譯為分散式計算)這個研究領域��,主要研究分散系統(Distributed system)如何進行計算����。分散系統是一組電子計算機(computer)�����,通過計算機網絡相互鏈接與通信后形成的系統�����。把需要進行大量計算的工程數據分區成小塊��,由多臺計算機分別計算���,在上傳運算結果后��,將結果統一合并得出數據結論的科學���。
10.分布式架構
分布式架構是 分布式計算技術的應用和工具��,目前成熟的技術包括J2EE, CORBA和.NET(DCOM)���,這些技術牽扯的內容非常廣��,相關的書籍也非常多��,本文不介紹這些技術的內容����,也沒有涉及這些技術的細節����,只是從各種分布式系統平臺產生的背景和在軟件開發中應用的情況來探討它們的主要異同��。
11.Hadoop
Hadoop是一個由Apache基金會所開發的分布式系統基礎架構����。
用戶可以在不了解分布式底層細節的情況下����,開發分布式程序�。充分利用集群的威力進行高速運算和存儲�����。
Hadoop實現了一個分布式文件系統(Hadoop Distributed File System)�����,簡稱HDFS���。HDFS有高容錯性的特點�,并且設計用來部署在低廉的(low-cost)硬件上�����;而且它提供高吞吐量(high throughput)來訪問應用程序的數據����,適合那些有著超大數據集(large data set)的應用程序��。HDFS放寬了(relax)POSIX的要求���,可以以流的形式訪問(streaming access)文件系統中的數據�����。
Hadoop的框架最核心的設計就是:HDFS和MapReduce�。HDFS為海量的數據提供了存儲�,則MapReduce為海量的數據提供了計算����。
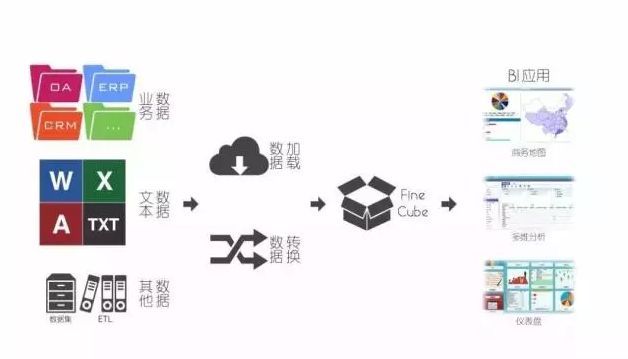
12.BI 商業智能
BI(Business Intelligence)即商務智能���,它是一套完整的解決方案��,用來將企業中現有的數據進行有效的整合�,快速準確的提供報表并提出決策依據���,幫助企業做出明智的業務經營決策�。
商業智能的概念最早在1996年提出����。當時將商業智能定義為一類由數據倉庫(或數據集市)�、查詢報表��、數據分析���、數據挖掘�、數據備份和恢復等部分組成的�、以幫助企業決策為目的技術及其應用�。而這些數據可能來自企業的CRM���、SCM等業務系統��。
商業智能能夠輔助的業務經營決策��,既可以是操作層的��,也可以是戰術層和戰略層的決策����。為了將數據轉化為知識��,需要利用數據倉庫���、聯機分析處理(OLAP)工具和數據挖掘等技術���。因此�,從技術層面上講���,商業智能不是什么新技術�����,它只是數據倉庫���、OLAP和數據挖掘等技術的綜合運用�。
把商業智能看成一種解決方案應該比較恰當���。商業智能的關鍵是從許多來自不同的企業運作系統的數據中提取出有用的數據并進行清理���,以保證數據的正確性�,然后經過抽?���。‥xtraction)����、轉換(Transformation)和裝載(Load)���,即ETL過程�����,合并到一個企業級的數據倉庫里��,從而得到企業數據的一個全局視圖���,在此基礎上利用合適的查詢和分析工具����、數據挖掘工具�����、OLAP工具等對其進行分析和處理(這時信息變為輔助決策的知識)�����,最后將知識呈現給管理者����,為管理者的決策過程提供數據支持���。商業智能產品及解決方案大致可分為數據倉庫產品�����、數據抽取產品����、OLAP產品�、展示產品��、和集成以上幾種產品的針對某個應用的整體解決方案等���。
13.非關系型數據庫 NoSQL
非關系型數據庫����,又被稱為NoSQL(Not Only SQL )���,意為不僅僅是SQL( Stmuctured QueryLanguage����,結構化查詢語言)���,據維基百科介紹����,NoSQL最早出現于1998 年���,是由Carlo Storzzi最早開發的個輕量�����、開源����、不兼容SQL 功能的關系型數據庫�����,2009 年��,在一次分布式開源數據庫的討論會上���,再次提出了NOSQL 的概念�,此時NOSQL主要是指I非關系型����、分布式�����、不提供ACID (數據庫事務處理的四個本要素)的數據庫設計模式�����。同年��,在業特蘭大舉行的“NO:SQL(east)”討論會上����,對NOSQL 最普遍的定義是“非關聯型的”�,強調Key-Value 存儲和文檔數據庫的優點�����,而不是單純地反對RDBMS�����,至此��,NoSQL 開始正式出現在世人面前�����。
14.結構化數據
結構化數據�����,簡單來說就是數據庫�����。結合到典型場景中更容易理解�����,比如企業ERP����、財務系統����;醫療HIS數據庫��;教育一卡通�����;政府行政審批�����;其他核心數據庫等��。
基本包括高速存儲應用需求�、數據備份需求����、數據共享需求以及數據容災需求�。
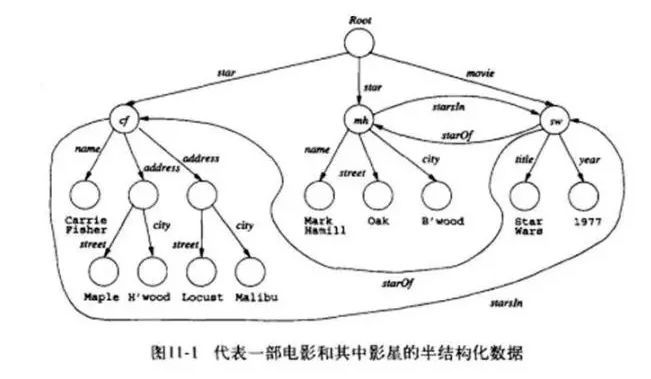
15.半結構化數據
和普通純文本相比�����,半結構化數據具有一定的結構性��,但和具有嚴格理論模型的關系數據庫的數據相比��。OEM(Object exchange Model)是一種典型的半結構化數據模型���。
在做一個信息系統設計時肯定會涉及到數據的存儲�����,一般我們都會將系統信息保存在某個指定的關系數據庫中����。我們會將數據按業務分類����,并設計相應的表�����,然后將對應的信息保存到相應的表中��。比如我們做一個業務系統��,要保存員工基本信息:工號�����、姓名��、性別�、出生日期等等��;我們就會建立一個對應的staff表��。
16.非結構化數據
非結構化數據庫是指其字段長度可變����,并且每個字段的記錄又可以由可重復或不可重復的子字段構成的數據庫����,用它不僅可以處理結構化數據(如數字�����、符號等信息)而且更適合處理非結構化數據(全文文本�、圖象�、聲音����、影視�����、超媒體等信息)����。
17.數據清洗
數據清洗從名字上也看的出就是把“臟”的“洗掉”����,指發現并糾正數據文件中可識別的錯誤的最后一道程序�,包括檢查數據一致性��,處理無效值和缺失值等�。因為數據倉庫中的數據是面向某一主題的數據的集合�����,這些數據從多個業務系統中抽取而來而且包含歷史數據�,這樣就避免不了有的數據是錯誤數據���、有的數據相互之間有沖突��,這些錯誤的或有沖突的數據顯然是我們不想要的�����,稱為“臟數據”��。我們要按照一定的規則把“臟數據”“洗掉”��,這就是數據清洗�����。而數據清洗的任務是過濾那些不符合要求的數據�,將過濾的結果交給業務主管部門�,確認是否過濾掉還是由業務單位修正之后再進行抽取����。不符合要求的數據主要是有不完整的數據�、錯誤的數據�����、重復的數據三大類�。數據清洗是與問卷審核不同�,錄入后的數據清理一般是由計算機而不是人工完成���。
18.算法 Algorithm
算法(Algorithm)是指解題方案的準確而完整的描述�,是一系列解決問題的清晰指令�,算法代表著用系統的方法描述解決問題的策略機制���。也就是說�,能夠對一定規范的輸入�,在有限時間內獲得所要求的輸出����。如果一個算法有缺陷�����,或不適合于某個問題���,執行這個算法將不會解決這個問題�。不同的算法可能用不同的時間�����、空間或效率來完成同樣的任務��。一個算法的優劣可以用空間復雜度與時間復雜度來衡量���。
19.深度學習 Deep Learning
深度學習的概念源于人工神經網絡的研究���。含多隱層的多層感知器就是一種深度學習結構��。深度學習通過組合低層特征形成更加抽象的高層表示屬性類別或特征�����,以發現數據的分布式特征表示���。
深度學習的概念由Hinton等人于2006年提出���?����;谏钚哦染W(DBN)提出非監督貪心逐層訓練算法��,為解決深層結構相關的優化難題帶來希望���,隨后提出多層自動編碼器深層結構���。此外Lecun等人提出的卷積神經網絡是第一個真正多層結構學習算法��,它利用空間相對關系減少參數數目以提高訓練性能���。
深度學習是機器學習研究中的一個新的領域���,其動機在于建立��、模擬人腦進行分析學習的神經網絡�����,它模仿人腦的機制來解釋數據���,例如圖像�,聲音和文本�����。
20.人工神經網絡 Artificial Neural Networks
人工神經網絡(Artificial Neural Networks�����,簡寫為ANNs)也簡稱為神經網絡(NNs)或稱作連接模型(Connection Model)��,它是一種模仿動物神經網絡行為特征���,進行分布式并行信息處理的算法數學模型��。這種網絡依靠系統的復雜程度��,通過調整內部大量節點之間相互連接的關系��,從而達到處理信息的目的����。
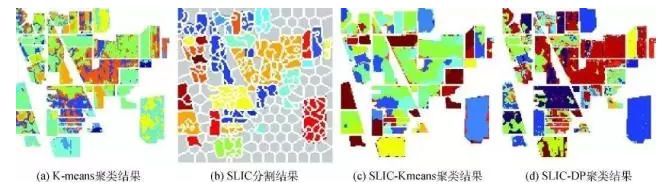
21.數據聚類 Cluster analysis
數據聚類 (英語 : Cluster analysis) 是對于靜態數據分析的一門技術���,在許多領域受到廣泛應用�,包括機器學習���,數據挖掘���,模式識別��,圖像分析以及生物信息�。聚類是把相似的對象通過靜態分類的方法分成不同的組別或者更多的子集(subset)�,這樣讓在同一個子集中的成員對象都有相似的一些屬性���,常見的包括在坐標系中更加短的空間距離等�����。
22.隨機森林 Random forest
在機器學習中���,隨機森林是一個包含多個決策樹的分類器��, 并且其輸出的類別是由個別樹輸出的類別的眾數而定����。 Leo Breiman和Adele Cutler發展出推論出隨機森林的算法����。 而 “Random Forests” 是他們的商標����。 這個術語是1995年由貝爾實驗室的Tin Kam Ho所提出的隨機決策森林(random decision forests)而來的�����。這個方法則是結合 Breimans 的 “Bootstrap aggregating” 想法和 Ho 的”random subspace method”” 以建造決策樹的集合����。
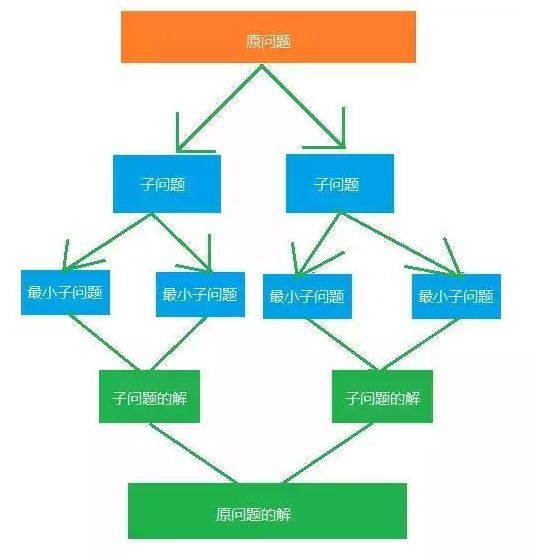
23.分治法 Divide and Conquer
在計算機科學中��,分治法是一種很重要的算法�。字面上的解釋是“分而治之”�����,就是把一個復雜的問題分成兩個或更多的相同或相似的子問題��,再把子問題分成更小的子問題……直到最后子問題可以簡單的直接求解���,原問題的解即子問題的解的合并��。這個技巧是很多高效算法的基礎�,如排序算法(快速排序�,歸并排序)�,傅立葉變換(快速傅立葉變換)����。
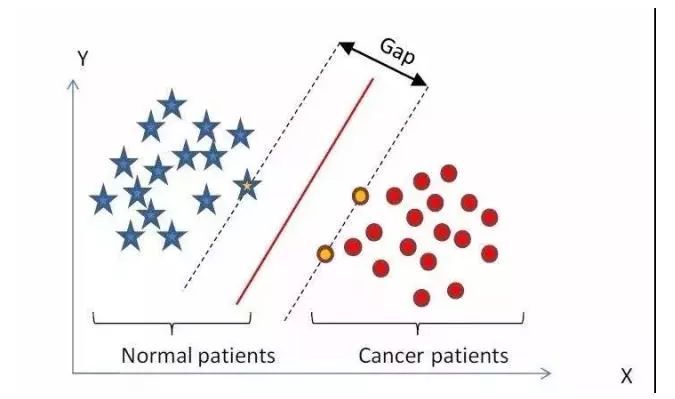
24.支持向量機 Support Vector Machine
在機器學習領域�,支持向量機SVM(Support Vector Machine)是一個有監督的學習模型����,通常用來進行模式識別����、分類�、以及回歸分析�����。
SVM的主要思想可以概括為兩點:⑴它是針對線性可分情況進行分析����,對于線性不可分的情況��,通過使用非線性映射算法將低維輸入空間線性不可分的樣本轉化為高維特征空間使其線性可分�����,從而 使得高維特征空間采用線性算法對樣本的非線性特征進行線性分析成為可能���;
25. 熵 entropy
熵(entropy)指的是體系的混亂的程度�,它在控制論�、概率論�、數論�����、天體物理���、生命科學等領域都有重要應用����,在不同的學科中也有引申出的更為具體的定義���,是各領域十分重要的參量��。熵的概念由魯道夫·克勞修斯(Rudolf Clausius)于1850年提出����,并應用在熱力學中�。1948年���,克勞德·艾爾伍德·香農(Claude Elwood Shannon)第一次將熵的概念引入信息論中����。
26.辛普森悖論 Simpson’s Paradox
辛普森悖論亦有人譯為辛普森詭論���,為英國統計學家E.H.辛普森(E.H.Simpson)于1951年提出的悖論���,即在某個條件下的兩組數據���,分別討論時都會滿足某種性質����,可是一旦合并考慮����,卻可能導致相反的結論���。
當人們嘗試探究兩種變量是否具有相關性的時候�����,比如新生錄取率與性別��,報酬與性別等�����,會分別對之進行分組研究���。辛普森悖論是在這種研究中��,在某些前提下有時會產生的一種現象��。即在分組比較中都占優勢的一方�����,會在總評中反而是失勢的一方��。該現象于20世紀初就有人討論�����,但一直到1951年E.H.辛普森在他發表的論文中���,該現象才算正式被描述解釋��。后來就以他的名字命名該悖論��。
為了避免辛普森悖論的出現���,就需要斟酌各分組的權重����,并乘以一定的系數去消除以分組數據基數差異而造成的影響�����。同時必需了解清楚情況��,是否存在潛在因素����,綜合考慮���。
27.樸素貝葉斯模型 Naive Bayesian Model�����,NBM
貝葉斯分類是一系列分類算法的總稱�,這類算法均以貝葉斯定理為基礎�,故統稱為貝葉斯分類�����。樸素貝葉斯算法(Naive Bayesian) 是其中應用最為廣泛的分類算法之一�。
樸素貝葉斯分類器基于一個簡單的假定:給定目標值時屬性之間相互條件獨立���。
通過以上定理和“樸素”的假定���,我們知道:P( Category | Document) = P ( Document | Category ) * P( Category) / P(Document)�����。
28.數據科學家 Data scientist
數據科學家是指能采用科學方法��、運用數據挖掘工具對復雜多量的數字���、符號�����、文字���、網址��、音頻或視頻等信息進行數字化重現與認識����,并能尋找新的數據洞察的工程師或專家(不同于統計學家或分析師)�����。一個優秀的數據科學家需要具備的素質有:懂數據采集����、懂數學算法��、懂數學軟件���、懂數據分析��、懂預測分析����、懂市場應用�����、懂決策分析等��。
29.并行處理 Parallel Processing
并行處理是計算機系統中能同時執行兩個或更多個處理機的一種計算方法����。處理機可同時工作于同一程序的不同方面�����。并行處理的主要目的是節省大型和復雜問題的解決時間���。為使用并行處理��,首先需要對程序進行并行化處理��,也就是說將工作各部分分配到不同處理機中�����。而主要問題是并行是一個相互依靠性問題����,而不能自動實現����。此外���,并行也不能保證加速���。但是一個在 n 個處理機上執行的程序速度可能會是在單一處理機上執行的速度的 n 倍�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情����;




























 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
