大數據會說話,簡明機器學習問題
從數據中學習究竟是什么���?科學家從數據中學習��,企業�、政府和慈善機構也一樣���。事實上���,無論是私人�����、公共的�����,還是慈善部門的領域����,幾乎沒有哪個領域不在部署數據驅動的模型����,以發掘和利用數據中的關系��。
我們置身于數據之中����,亞馬遜網站每天發生2.5萬次銷售/交付�����,10萬個基因幾乎同時測序��,超過100億張圖片存儲在網頁上����。而大約在幾個月之內����,英國的國家衛生局對6000萬份健康記錄進行了數字化處理���。我們所有人每天都在使用數據���,而且許多人在工作的付薪過程中都使用了數據�。營銷公司的分析師必須決定�����,他的受眾/聽眾選擇模型需要包含哪些因素��。本地衛生部門的研究人員測量季節性流感的發病率���。氣象學家運行氣候模型���,計算降水的可能性�、溫度的變化以及云層覆蓋的百分比�。
公共部門和某些公司需要將海量信息轉換為可操作的戰略性公共/商業決策���。從數據中學習提供了一系列實踐性的技術和工具�����,來幫助開發穩健的歸納模型�,用以從數據中提取可用的見解���。歸納的簡單含義是指觀點源于經驗數據��,而非根據理論第一的原則來推導�。
本文的首要目標是幫助你把大量數據轉化為可用的知識�����。為此�����,我們將借助理論來重塑數據科學挑戰的思考方式�����。但是�����,本文不是一本專門討論引理���、證明以及抽象理論細節的教科書�����。它為這樣的讀者而準備:他們希望獲得一個重要的����、成功的框架��,用來建立有用的預測分析模型�����,從而為他們工作的組織以及他們服務的客戶改善運營方式和提高盈利�����。同時務必了解�����,數據科學這項職業不適合那些缺乏好奇心或者技術能力的人�����,任何處理實證數據的職業也同樣不適合���。
在本文中�����,你會學到歸納推理與演繹推理的關鍵區別�����,確定學習問題的三大要素����,以及發現使用歸納模型的一個明確框架�����。
1.1 歸納推理和演繹推理的基礎
圖1.1圍繞著假設檢驗�����,展示了歸納法和演繹法之間的一個關鍵區別����。兩種方法都始于觀察有趣的現象���,但歸納方法更關心選擇最佳的預測模型�。而演繹方法更關心探索理論���,主要是結合數據來檢驗某個理論的假設����。根據經驗數據的“有分量的證據”�����,來判斷這個假設是接受還是拒絕����。
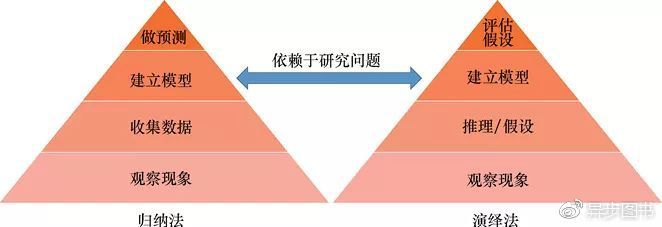
圖1.1 歸納和演繹
1.1.1 你曾遇到過這些事情嗎�����?
我想起在我聽過的理論經濟學課上����,教授曾嚴厲警告:“不能信任數據����?�!币苍S����,這種經歷并不僅僅出現在我的課堂上�。一位著名的計量經濟學教授曾解釋道1:“經濟學中有一種普遍觀點��,如果當前的經驗證據不可信�,或經濟現象無法預測�,那么主要是因為經濟太復雜����,而且產生的數據太混亂���,不適合建立統計模型����?��!被蛟S�����,你也有過類似經歷���。
但是�,當我離開課堂���,步入了經驗分析的真實世界���,居然很快發現��,只要給我足夠的數據和適合的工具���,使用數據驅動的歸納法會帶給我意義重大的結論���。
注意:在每個可以想到的領域——商業的����、工業的以及政府的����,成功的數據驅動的歸納模型都已經存在�����,或正在建立�����。數據決策的模型越來越多地用來制定決策��,如可以識別你的語音的智能手機��,又如實施外科手術的機器人2�����,再如核爆炸的檢測��。
1.1.2 釋放歸納的力量
無論你是否在這些領域中工作�,醫療診斷���、手寫體識別���、市場��、金融預測�、生物信息學�����、經濟學的領域����,還是在其他任何要求經驗分析的專業領域��,你常常會面對這樣的情況���,潛在的首要原則尚未發現���,或正在研究的系統過于復雜����,無法通過充分詳細的數學描述來提供有用的結果�。我發現�����,數據驅動的歸納方法在以上所有情況中都有用�,你也會認同這一點���。
注意:在科學之外��,演繹分析可能在經濟學學科中占據了頂峰地位��,其中大部分的焦點(甚至今天也一樣)都圍繞著檢驗和評估演繹理論的經濟學有效性�����。事實上�,經濟學家對理論進行客觀驗證的渴望催生了新的統計學子學科—計量經濟學��。
1.1.3 推斷的陰陽之道
盡管歸納和演繹的區別相當大��,但它們實際上也可以互補使用��。對于一個研究者來說���,計劃一個同時包含歸納元素和演繹元素的項目是非同尋常的����。
如果你曾經或長或短地從事過經驗建模領域的工作��,那你很可能發現這種情況:你計劃執行一個歸納或演繹的項目��,但沒想到隨著時間的推移�,你又發現了其他更適合的方法來闡明你的研究問題���。需要牢記的是���,歸納方法或演繹方法的使用�����,部分地依賴于你的數據分析目標����。
注意:演繹推理優越性的相對下降��,可以部分地由數據驅動模型的高度成功來解釋���。意大利學者馬特奧·帕爾多(Matteo
Pardo)和喬治·斯貝沃格里尼(Giorgio
Sberveglieri)在十多年前正確地觀察到6:“在當前�,從遵循首要原則的經典建模到開發數據建模�,發生了一種范式轉換�����?��!庇腥さ氖?,需要注意��,現在數據建模者的短缺是世界性的問題7���。
1.2 學習問題的三大要素
我們的討論始于學習問題的基礎�。例如��,有監督的分類問題��,其中我們得到的數據是實值的屬性—響應對(x��,y)��。三個元素組成了基本的學習問題����。

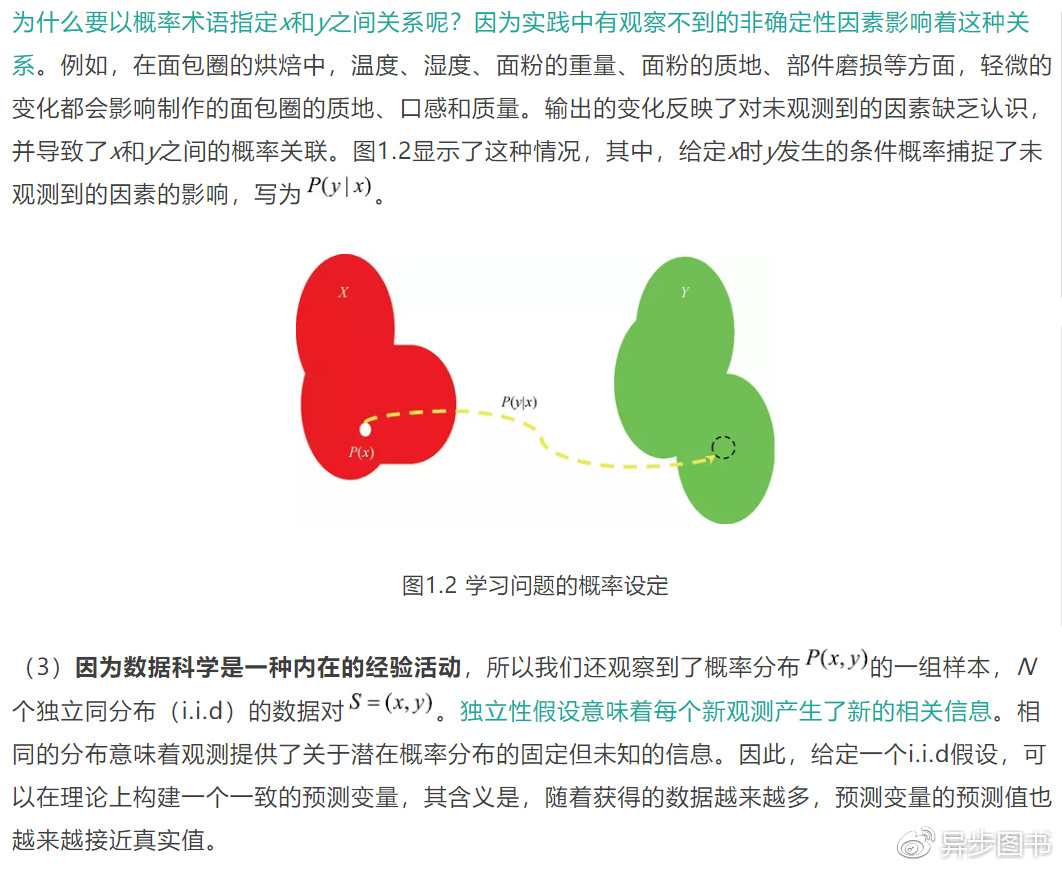
1.3 從數據中學習的目標

注意:
歸納偏置是數據科學實踐中的一個關鍵要素�,正如倫敦經濟學院的Jonathan
Baxter的解釋8:“在機器學習中�����,可能最重要的事情就是學習機器假設空間的預先偏置��,它要足夠小���,以保證合理訓練集的好的一般化(預測能力)��,也要足夠大��,這樣它才能包含學習問題好的解決答案�����?!?
1.3.1 闡明選擇標準

1.3.2 學習任務的選擇
現在����,我們的學習框架已經準備就緒�����,可以把注意力轉向我們作為數據科學家需要執行的真實任務���。相當幸運�����,結果發現從數據中學習可以恰好分成3種基本類型的工作:
(1)類別決策邊界的分類或估計�。例如��,流水線上按大小和顏色分類的雞蛋�。
(2)未知連續函數的回歸或估計����。例如�,預測本地音樂節創造的票房平均價值�����。
(3)概率密度的估計����。例如�,估計愛爾蘭沿海河流中白斑狗魚的密度�。
本文將自始至終主要討論分類的問題�,因為這是數據科學家面對的最頻繁的任務�。但是��,我們得出的經驗教訓適用于所有3種類型的任務�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
