R語言深度學習不同模型對比分析案例
深度學習是機器學習最近的一個趨勢��,模擬高度非線性的數據表示�����。在過去的幾年中����,深度學習在各種應用中獲得了巨大的發展勢頭(Wikipedia
2016a)�����。其中包括圖像和語音識別���,無人駕駛汽車����,自然語言處理等等���。有趣的是���,深度學習的大部分數學概念已經被認識了幾十年����。然而�����,只有通過最近的一些發展����,深度學習的全部潛力才得以釋放(Nair
and Hinton����,2010; Srivastava et al����。��,2014)���。
以前�,由于梯度消失和過度配合問題�,很難訓練人工神經網絡?�,F在��,這兩個問題都可以通過使用不同的激活函數��,輟學正則化和大量的訓練數據來解決��。例如�,互聯網現在可以用來檢索大量的有標簽和無標簽的數據���。另外����,GPU和GPGPU的可用性使得計算更便宜和更快�。
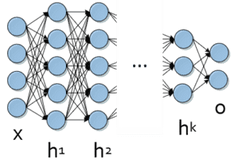
今天�����,深度學習對于幾乎所有需要機器學習的任務都是非常有效的���。但是����,它特別適合復雜的分層數據���。其潛在的人工神經網絡模型高度非線性表示; 這些通常由多層結合非線性轉換和定制架構組成���。圖1描述了一個深度神經網絡的典型表示�����。
圖1.深度神經網絡的模型
深度學習的成功帶來了各種編程語言的各種框架和庫�����。例子包括Caffee�,Theano��,Torch和Tensor Flow等等���。這篇博客文章的目的是為編程語言R提供不同深度學習軟件包的概述和比較�。我們比較不同數據集的性能和易用性�。
R學習套裝
R編程語言在統計人員和數據挖掘人員之間的易用性以及復雜的可視化和分析方面已經獲得了相當的普及����。隨著深度學習時代的到來��,對R的深度學習的支持不斷增長�,隨著越來越多的軟件包的推出��,本節提供以下軟件包提供的有關深度學習的概述:MXNetR����,darch����,deepnet����,H2O和deepr����。
首先�����,我們注意到���,從一個包到另一個包的底層學習算法有很大的不同����。同樣���,表1顯示了每個軟件包中可用方法/體系結構的列表���。
表1. R包中可用的深度學習方法列表��。
包神經網絡的可用體系結構
MXNetR前饋神經網絡�,卷積神經網絡(CNN)
達奇限制玻爾茲曼機���,深層信念網絡
DEEPNET前饋神經網絡�����,受限玻爾茲曼機器����,深層信念網絡�,堆棧自動編碼器
H2O前饋神經網絡����,深度自動編碼器
deepr從H2O和深網包中簡化一些功能
包“MXNetR”
MXNetR包是用C ++編寫的MXNet庫的接口�����。它包含前饋神經網絡和卷積神經網絡(CNN)(MXNetR
2016a)���。它也允許人們構建定制的模型�。該軟件包分為兩個版本:僅限CPU或GPU版本�。以前的CPU版本可以直接從R內部直接安裝�,而后者的GPU版本依賴于第三方庫(如cuDNN)�����,并需要從其源代碼(MXNetR
2016b)中構建庫���。
前饋神經網絡(多層感知器)可以在MXNetR中構建�,其函數調用如下:
mx.mlp(data, label, hidden_node=1, dropout=NULL, activation=”tanh”, out_activation=”softmax”, device=mx.ctx.default(),…)
參數如下:
data - 輸入矩陣
label - 培訓標簽
hidden_node - 包含每個隱藏層中隱藏節點數量的向量
dropout - [0,1)中包含從最后一個隱藏層到輸出層的丟失率的數字
activation - 包含激活函數名稱的單個字符串或向量���。有效值是{ 'relu'�,'sigmoid'�����,'softrelu'��,'tanh'}
out_activation - 包含輸出激活函數名稱的單個字符串��。有效值是{ 'rmse'�����,'sofrmax'�����,'logistic'}
device- 是否訓練mx.cpu(默認)或mx.gpu
... - 傳遞給其他參數 mx.model.FeedForward.create
函數mx.model.FeedForward.create在內部使用�,mx.mpl并采用以下參數:
symbol - 神經網絡的符號配置
y - 標簽數組
x - 培訓數據
ctx - 上下文�,即設備(CPU / GPU)或設備列表(多個CPU或GPU)
num.round - 訓練模型的迭代次數
optimizer- 字符串(默認是'sgd')
initializer - 參數的初始化方案
eval.data - 過程中使用的驗證集
eval.metric - 評估結果的功能
epoch.end.callback - 迭代結束時回調
batch.end.callback - 當一個小批量迭代結束時回調
array.batch.size - 用于陣列訓練的批量大小
array.layout-可以是{ 'auto'���,'colmajor'�,'rowmajor'}
kvstore - 多個設備的同步方案
示例調用:
model <- mx.mlp(train.x, train.y, hidden_node=c(128,64), out_node=2,
activation="relu", out_activation="softmax",num.round=100,
array.batch.size=15, learning.rate=0.07, momentum=0.9, device=mx.cpu())
之后要使用訓練好的模型��,我們只需要調用predict()指定model第一個參數和testset第二個參數的函數:
preds = predict(model, testset)
這個函數mx.mlp()本質上代表了使用MXNet的'Symbol'系統定義一個神經網絡的更靈活但更長的過程�。以前的網絡符號定義的等價物將是:
data <- mx.symbol.Variable("data") fc1 <-
mx.symbol.FullyConnected(data, num_hidden=128) act1 <-
mx.symbol.Activation(fc1, name="relu1", act_type="relu")
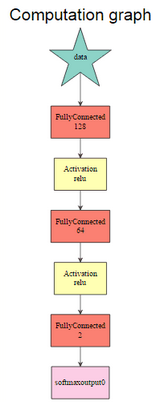
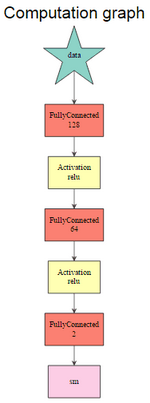
當網絡架構最終被創建時�����,MXNetR提供了一種簡單的方法來使用以下函數調用來圖形化地檢查它:
graph.viz(model$symbol$as.json())
graph.viz(model2$symbol$as.json())
這里�,參數是由符號表示的訓練模型��。第一個網絡由mx.mlp()第二個網絡構建����,第二個網絡使用符號系統�����。
該定義從輸入到輸出逐層進行�,同時還為每個層分別允許不同數量的神經元和特定的激活函數����。其他選項可通過mx.symbol以下方式獲得:mx.symbol.Convolution��,將卷積應用于輸入���,然后添加偏差��。它可以創建卷積神經網絡����。相反mx.symbol.Deconvolution���,通常在分割網絡中使用mx.symbol.UpSampling�����,以便重建圖像的按像素分類��。CNN中使用的另一種類型的層是mx.symbol.Pooling; 這實質上通過選擇具有最高響應的信號來減少數據�����。該層mx.symbol.Flatten需要將卷積層和池層鏈接到完全連接的網絡�����。另外�����,mx.symbol.Dropout可以用來應付過度配合的問題��。它將輸入的參數previous_layer和浮點值fraction作為下降的參數��。
正如我們所看到的����,MXNetR可用于快速設計標準多層感知器的功能���,mx.mlp()或用于更廣泛的關于符號表示的實驗�。
LeNet網絡示例:
data <- mx.symbol.Variable('data')
總而言之�,MXNetR軟件包非常靈活��,同時支持多個CPU和多個GPU�。它具有構建標準前饋網絡的捷徑��,同時也提供了靈活的功能來構建更復雜的定制網絡�,如CNN LeNet����。
包“darch”
darch軟件包(darch 2015)實施深層架構的訓練����,如深層信念網絡�,它由分層預訓練的限制玻爾茲曼機器組成����。該套件還需要反向傳播進行微調�,并且在最新版本中���,可以選擇預培訓��。
深層信仰網絡的培訓是通過darch()功能進行的�����。
示例調用:
darch <- darch(train.x, train.y, rbm.numEpochs = 0,
rbm.batchSize = 100, rbm.trainOutputLayer =
F, layers = c(784,100,10), darch.batchSize
= 100, darch.learnRate = 2,
darch.retainData = F, darch.numEpochs = 20
)
這個函數帶有幾個最重要的參數�,如下所示:
x - 輸入數據
y - 目標數據
layers - 包含一個整數的矢量����,用于每個圖層中的神經元數量(包括輸入和輸出圖層)
rbm.batchSize - 預培訓批量大小
rbm.trainOutputLayer - 在訓練前使用的布爾值�。如果屬實�,RBM的輸出層也會被訓練
rbm.numCD - 執行對比分歧的完整步數
rbm.numEpochs - 預培訓的時期數量
darch.batchSize - 微調批量大小
darch.fineTuneFunction - 微調功能
darch.dropoutInput - 網絡輸入丟失率
darch.dropoutHidden - 隱藏層上的丟失率
darch.layerFunctionDefault-為DBN默認激活功能��,可用的選項包括{ 'sigmoidUnitDerivative'���,'binSigmoidUnit'���,'linearUnitDerivative'��,'linearUnit'��,'maxoutUnitDerivative'�����,'sigmoidUnit'�����,'softmaxUnitDerivative'����,'softmaxUnit'��,'tanSigmoidUnitDerivative'�,'tanSigmoidUnit'}
darch.stopErr - 如果錯誤小于或等于閾值��,則停止訓練
darch.numEpochs - 微調的時代數量
darch.retainData - 布爾型���,指示在培訓之后將訓練數據存儲在darch實例中的天氣
根據以前的參數�,我們可以訓練我們的模型產生一個對象darch�����。稍后我們可以將其應用于測試數據集test.x來進行預測���。在這種情況下�����,一個附加參數type指定預測的輸出類型�����。例如���,可以‘raw’給出‘bin’二進制向量和‘class’類標簽的概率��。最后�,在調用時predict()進行如下預測:
predictions <- predict(darch, test.x, type="bin")
總的來說���,darch的基本用法很簡單��。它只需要一個功能來訓練網絡�����。但另一方面�,這套教材只限于深層的信仰網絡��,這通常需要更廣泛的訓練���。
包“deepnet ”
deepnet (deepnet
2015)是一個相對較小�����,但相當強大的軟件包�,有多種架構可供選擇���。它可以使用函數來訓練一個前饋網絡����,也可以用nn.train()深度信念網絡來初始化權重dbn.dnn.train()���。這個功能在內部rbm.train()用來訓練一個受限制的波爾茲曼機器(也可以單獨使用)����。此外����,深網也可以處理堆疊的自動編碼器sae.dnn.train()���。
示例調用(for nn.train()):
nn.train(x, y, initW=NULL, initB=NULL, hidden=c(50,20),
activationfun="sigm", learningrate=0.8, momentum=0.5,
learningrate_scale=1, output="sigm", numepochs=3, batchsize=100,
hidden_dropout=0, visible_dropout=0)
人們可以設置原來的權initW重initB���,否則隨機生成�����。另外���,hidden控制的在隱藏層單元的數量��,而activationfun指定的隱藏層的激活功能(可以是‘sigm’�,‘linear’或‘tanh’)��,以及輸出層的(可以是‘sigm’�����,‘linear’�����,‘softmax’)���。
作為一種選擇���,下面的例子訓練一個神經網絡���,其中權重是由深層信念網絡(via dbn.dnn.train())初始化的�����。差別主要在于訓練受限玻爾茲曼機的對比散度算法��。它是通過cd給定學習算法內的吉布斯采樣的迭代次數來設置的����。
dbn.dnn.train(x, y, hidden=c(1), activationfun="sigm", learningrate=0.8,
momentum=0.5, learningrate_scale=1, output="sigm", numepochs=3,
batchsize=100, hidden_dropout=0, visible_dropout=0, cd=1)
同樣����,也可以從堆棧自動編碼器初始化權重�����。output這個例子不是使用參數�,而是sae_output和以前一樣使用����。
sae.dnn.train(x, y, hidden=c(1), activationfun="sigm", learningrate=0.8,
momentum=0.5, learningrate_scale=1, output="sigm", sae_output="linear",
numepochs=3, batchsize=100, hidden_dropout=0, visible_dropout=0)
最后�,我們可以使用訓練有素的網絡來預測結果nn.predict()�����。隨后�,我們可以借助nn.test()錯誤率將預測轉化為錯誤率����。第一次調用需要一個神經網絡和相應的觀察值作為輸入��。第二個電話在進行預測時還需要正確的標簽和閾值(默認值為0.5)����。
predictions = nn.predict(nn, test.x) error_rate = nn.test(nn, test.x, test.y, t=0.5)
總而言之��,深網代表了一個輕量級的包���,其中包含了一系列有限的參數����。但是���,它提供了多種體系結構��。
包裝“H2O”
H2O是一個開源軟件平臺�,可以利用分布式計算機系統(H2O 2015)����。其核心以Java編碼���,需要最新版本的JVM和JDK��,可以在https://www.java.com/en/download/上找到��。該軟件包為許多語言提供接口�����,最初設計用作基于云的平臺(Candel
et al�����。2015)�����。因此���,通過調用h2o.init()以下命令啟動H2O :
h2o.init(nthreads = -1)
該參數nthreads指定將使用多少個核心進行計算�����。值-1表示H2O將嘗試使用系統上所有可用的內核����,但默認為2.此例程也可以使用參數��,ip并且portH2O安裝在不同的機器上��。默認情況下�,它將IP地址127.0.0.1與端口54321一起使用��。因此����,可以在瀏覽器中定位地址“localhost:54321”以訪問基于Web的界面�。一旦您使用當前的H2O實例完成工作��,您需要通過以下方式斷開連接:
h2o.shutdown()
示例調用:
所有培訓操作h2o.deeplearning()如下:
model <- h2o.deeplearning( x=x, y=y, training_frame=train,
validation_frame=test, distribution="multinomial",
activation="RectifierWithDropout", hidden=c(32,32,32),
input_dropout_ratio=0.2, sparse=TRUE, l1=1e-5, epochs=100)
用于在H2O中傳遞數據的接口與其他包略有不同:x是包含具有訓練數據的列的名稱的向量����,并且y是具有所有名稱的變量的名稱�����。接下來的兩個參數�,training_frame并且validation_frame��,是H2O幀的對象�。它們可以通過調用來創建h2o.uploadFile()����,它將目錄路徑作為參數���,并將csv文件加載到環境中����。特定數據類的使用是由分布式環境激發的��,因為數據應該在整個集群中可用�����。所述參數distribution是一個字符串����,并且可以采取的值‘bernoulli’�����,‘multinomial’�����,‘poisson’��,‘gamma’��,‘tweedie’�����,‘laplace’��,‘huber’或‘gaussian’���,而‘AUTO’根據數據自動選擇一個參數�。以下參數指定activation功能(可能的值是‘Tanh’��,‘TanhWithDropout’�,‘Rectifier’����,‘RectifierWithDropout’�,‘Maxout’或‘MaxoutWithDropout’)��。該參數sparse是表示高度零的布爾值�,這使得H2
=可以更有效地處理它�。其余的參數是直觀的����,與其他軟件包差別不大����。然而����,還有更多的微調可用�,但可能沒有必要更改它們����,因為它們帶有推薦的預定義值����。
最后����,我們可以使用h2o.predict()以下簽名進行預測:
predictions <- h2o.predict(model, newdata=test_data)
H2O提供的另一個強大工具是優化超參數的網格搜索�?��?梢詾槊總€參數指定一組值�,然后找到最佳組合值h2o.grid()����。
超參數優化
H2 =包將訓練四種不同的模型���,兩種架構和不同的L1正則化權重����。因此�,可以很容易地嘗試一些超參數的組合�����,看看哪一個更好:
深度自動編碼器
H2O也可以利用深度自動編碼器����。為了訓練這樣的模型��,使用相同的功能h2o.deeplearning()����,但是這組參數略有不同
在這里���,我們只使用訓練數據��,沒有測試集和標簽��。我們需要深度自動編碼器而不是前饋網絡的事實由autoencoder參數指定�����。和以前一樣�����,我們可以選擇多少隱藏單元應該在不同的層次�。如果我們使用一個整數值����,我們將得到一個天真的自動編碼器�。
訓練結束后���,我們可以研究重建誤差����。我們通過特定的h2o.anomaly()函數來計算它���。
總的來說�����,H2O是一個非常用戶友好的軟件包��,可以用來訓練前饋網絡或深度自動編碼器�����。它支持分布式計算并提供一個Web界面����。
包“更深”
deepr (deepr
2015)包本身并沒有實現任何深度學習算法���,而是將其任務轉交給H20����。該包最初是在CRAN尚未提供H2O包的時候設計的����。由于情況不再是這樣��,我們會將其排除在比較之外����。我們也注意到它的功能train_rbm()使用深層的實現rbm來訓練帶有一些附加輸出的模型�。
軟件包的比較
本節將比較不同指標的上述軟件包�����。其中包括易用性����,靈活性��,易于安裝����,支持并行計算和協助選擇超參數����。另外����,我們測量了三個常見數據集“Iris”�����,“MNIST”和“森林覆蓋類型”的表現��。我們希望我們的比較幫助實踐者和研究人員選擇他們喜歡的深度學習包����。
安裝
通過CRAN安裝軟件包通常非常簡單和流暢���。但是��,一些軟件包依賴于第三方庫����。例如����,H2O需要最新版本的Java以及Java Development
Kit��。darch和MXNetR軟件包允許使用GPU���。為此����,darch依賴于R軟件包gpuools���,它僅在Linux和MacOS系統上受支持���。默認情況下��,MXNetR不支持GPU�����,因為它依賴于cuDNN���,由于許可限制��,cuDNN不能包含在軟件包中�����。因此���,MXNetR的GPU版本需要Rtools和一個支持C
++ 11的現代編譯器���,以使用CUDA SDK和cuDNN從源代碼編譯MXNet�。
靈活性
就靈活性而言����,MXNetR很可能位列榜首�����。它允許人們嘗試不同的體系結構�����,因為它定義了網絡的分層方法���,更不用說豐富多樣的參數了�����。在我們看來��,我們認為H2O和darch都是第二名����。H20主要針對前饋網絡和深度自動編碼器���,而darch則側重于受限制的玻爾茲曼機器和深度信念網絡�。這兩個軟件包提供了廣泛的調整參數��。最后但并非最不重要的一點�����,deepnet是一個相當輕量級的軟件包����,但是當想要使用不同的體系結構時��,它可能是有益的�����。然而���,我們并不推薦將其用于龐大數據集的日常使用�,因為其當前版本缺乏GPU支持����,而相對較小的一組參數不允許最大限度地進行微調�����。
使用方便
H2O和MXNetR的速度和易用性突出�����。MXNetR幾乎不需要準備數據來開始訓練�����,而H2O通過使用as.h2o()將數據轉換為H2OFrame對象的函數提供了非常直觀的包裝�。這兩個包提供了額外的工具來檢查模型����。深網以單熱編碼矩陣的形式獲取標簽�����。這通常需要一些預處理��,因為大多數數據集都具有矢量格式的類���。但是����,它沒有報告關于培訓期間進展的非常詳細的信息�����。該軟件包還缺少用于檢查模型的附加工具�����。darch���,另一方面�����,有一個非常好的和詳細的輸出�����。
總的來說���,我們將H2O或者MXNetR看作是這個類別的贏家��,因為兩者都很快并且在訓練期間提供反饋�����。這使得人們可以快速調整參數并提高預測性能����。
并行
深度學習在處理大量數據集時很常見�。因此�,當軟件包允許一定程度的并行化時�����,它可以是巨大的幫助����。表2比較了并行化的支持�。它只顯示文件中明確說明的信息�。
參數的選擇
另一個關鍵的方面是超參數的選擇����。H2O軟件包使用全自動的每神經元自適應學習速率來快速收斂���。它還可以選擇使用n-fold交叉驗證���,并提供h2o.grid()網格搜索功能�����,以優化超參數和模型選擇���。
MXNetR在每次迭代后顯示訓練的準確性��。darch在每個紀元后顯示錯誤�����。兩者都允許在不等待收斂的情況下手動嘗試不同的超參數���,因為如果精度沒有提高�,訓練階段可以提前終止�。相比之下�����,深網不會顯示任何信息�,直到訓練完成�����,這使得調整超參數非常具有挑戰性����。
性能和運行時間
我們準備了一個非常簡單的性能比較�����,以便為讀者提供有關效率的信息��。所有后續測量都是在CPU Intel Core i7和GPU NVidia
GeForce
750M(Windows操作系統)的系統上進行的�。比較是在三個數據集上進行的:“MNIST” (LeCun等人2012)�����,“Iris” (Fisher
1936)和“森林覆蓋類型” (Blackard和Dean 1998)�。詳情見附錄����。
作為基準���,我們使用H2O包中實現的隨機森林算法�。隨機森林是通過構建多個決策樹(維基百科2016b)來工作的集合學習方法��。有趣的是�,它已經證明了它能夠在不進行參數調整的情況下在很大程度上實現高性能����。
結果
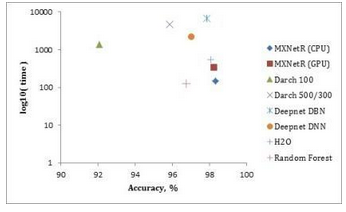
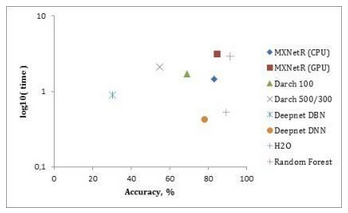
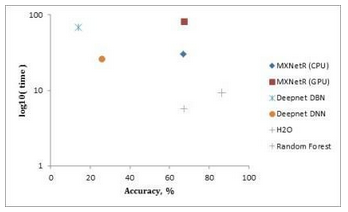
測量結果在表3中給出���,并且在圖2��,圖3和圖4中分別針對“MNIST”����,“虹膜”和“森林覆蓋類型”數據集可視化����。
'MNIST'數據集�。根據表3和圖2�,MXNetR和H2O在“MNIST”數據集上實現了運行時間和預測性能之間的優越折衷���。darch和deepnet需要相對較長的時間來訓練網絡��,同時達到較低的精度���。
'虹膜'數據集���。在這里�����,我們再次看到MXNetR和H2O表現最好���。從圖3可以看出�,深網具有最低的準確性���,可能是因為它是如此小的數據集�����,在訓練前誤導���。正因為如此��,darch 100和darch 500/300通過反向傳播訓練����,省略了訓練前的階段��。這由表中的*符號標記�。
“森林覆蓋類型”數據集����。H2O和MXNetR顯示的準確率大約為67%�����,但是這還是比其他軟件包好��。我們注意到darch 100和darch 500/300的培訓沒有收斂�,因此這些模型被排除在這個比較之外�。
我們希望��,即使是這種簡單的性能比較�,也可以為從業人員在選擇自己喜歡的R包時提供有價值的見解
注意:從圖3和圖4可以看出���,隨機森林比深度學習包能夠表現得更好�。這有幾個有效的原因�。首先�����,數據集太小����,因為深度學習通常需要大數據或使用數據增強才能正常工作��。其次�,這些數據集中的數據由手工特征組成��,這就否定了深層架構從原始數據中學習這些特征的優勢����,因此傳統方法可能就足夠了����。最后����,我們選擇非常相似的(也可能不是最高效的)體系結構來比較不同的實現�。
表3. R中不同深度學習包的準確性和運行時間的比較
*僅使用反向傳播訓練的模型(不進行預訓練)�����。
型號/數據集MNIST鳶尾花森林覆蓋類型
準確性 (%)運行時間(秒)準確性 (%)運行時間(秒)準確性 (%)運行時間(秒)
圖2.比較“MNIST”數據集的運行時間和準確度����。
圖3.“虹膜”數據集的運行時間和精度比較
圖4.“森林覆蓋類型”數據集的運行時間和準確度的比較����。
結論
作為本文的一部分����,我們在R中比較了五種不同的軟件包���,以便進行深入的學習:(1)當前版本的deepnet可能代表可用體系結構中差異最大的軟件包���。但是��,由于它的實施����,它可能不是最快也不是用戶最友好的選擇����。此外�,它可能不提供與其他一些軟件包一樣多的調整參數�。(2)H2O和MXNetR相反��,提供了非常人性化的體驗�����。兩者還提供額外信息的輸出��,快速進行訓練并取得體面的結果���。H2O可能更適合集群環境�����,數據科學家可以在簡單的流水線中使用它來進行數據挖掘和勘探�。當靈活性和原型更受關注時�����,MXNetR可能是最合適的選擇���。它提供了一個直觀的符號工具��,用于從頭構建自定義網絡體系結構���。此外�,通過利用多CPU
/ GPU功能����,它可以在個人電腦上運行�。(3)darch提供了一個有限但是有針對性的功能��,重點是深度信念網絡�。
總而言之����,我們看到R對深度學習的支持正在順利進行�����。最初����,R提供的功能落后于其他編程語言����。但是�����,這不再是這種情況���。有了H20和MXnetR��,R用戶就可以在指尖上使用兩個強大的工具�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
