使用R語言進行協整關系檢驗
協整檢驗是為了檢驗非平穩序列的因果關系����,協整檢驗是解決偽回歸為問題的重要方法���。首先回歸偽回歸例子:
偽回歸Spurious regression 偽回歸方程的擬合優度���、顯著性水平等指標都很好�,但是其殘差序列是一個非平穩序列���,擬合一個偽回歸:
#調用相關R包
library(lmtest)
library(tseries)
#模擬序列
set.seed(123456)
e1 = rnorm(500)
e2 = rnorm(500)
trd = 1:500
y1 = 0.8 * trd + cumsum(e1)
y2 = 0.6 * trd + cumsum(e2)
sr.reg = lm(y1 ~ y2)
#提取回歸殘差
error = residuals(sr.reg)
#作殘差散點圖
plot(error, main = "Plot
of error")
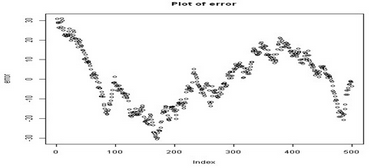
#對殘差進行單位根檢驗
adf.test(error)
## Dickey-Fuller = -2.548, Lag order = 7, p-value = 0.3463
## alternative hypothesis: stationary
#偽回歸結果�����,相關參數都顯著
summary(sr.reg)
## Residuals:
## Min 1Q Median 3Q Max
## -30.654 -11.526 0.359 11.142 31.006
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -29.32697 1.36716 -21.4 <2e-16 ***
## y2 1.44079 0.00752 191.6 <2e-16 ***
## Residual standard error: 13.7 on 498 degrees of freedom
## Multiple R-squared: 0.987, Adjusted R-squared: 0.987
## F-statistic: 3.67e+04 on 1 and 498 DF, p-value: <2e-16
dwtest(sr.reg)
## DW = 0.0172, p-value < 2.2e-16
恩格爾-格蘭杰檢驗Engle-Granger 第一步:建立兩變量(y1,y2)的回歸方程�����, 第二部:對該回歸方程的殘差(resid)進行單位根檢驗其中���,原假設兩變量不存在協整關系���,備擇假設是兩變量存在協整關系��。利用最小二乘法對回歸方程進行估計�����,從回歸方程中提取殘差進行檢驗����。
set.seed(123456)
e1 = rnorm(100)
e2 = rnorm(100)
y1 = cumsum(e1)
y2 = 0.6 * y1 + e2
# (偽)回歸模型
lr.reg = lm(y2 ~ y1)
error = residuals(lr.reg)
adf.test(error)
## Dickey-Fuller = -3.988, Lag order = 4, p-value = 0.01262
## alternative hypothesis: stationary
error.lagged = error[-c(99, 100)]
# 建立誤差修正模型ECM.REG
dy1 = diff(y1)
dy2 = diff(y2)
diff.dat = data.frame(embed(cbind(dy1,
dy2), 2)) #emed表示嵌入時間序列dy1,dy2到diff.dat
colnames(diff.dat) = c("dy1", "dy2", "dy1.1", "dy2.1")
ecm.reg = lm(dy2 ~ error.lagged + dy1.1 + dy2.1,
data =diff.dat)
summary(ecm.reg)
## Residuals:
## Min 1Q Median 3Q Max
## -2.959 -0.544 0.137 0.711 2.307
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.0034 0.1036 0.03 0.97
## error.lagged -0.9688 0.1585 -6.11 2.2e-08 ***
## dy1.1 0.8086 0.1120 7.22 1.4e-10 ***
## dy2.1 -1.0589 0.1084 -9.77 5.6e-16 ***
## Residual standard error: 1.03 on 94 degrees of freedom
## Multiple R-squared: 0.546, Adjusted R-squared: 0.532
## F-statistic: 37.7 on 3 and 94 DF, p-value: 4.24e-16
par(mfrow = c(2, 2))
plot(ecm.reg)
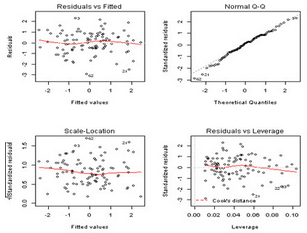
Johansen-Juselius(JJ)協整檢驗法���,該方法是一種用向量自回歸(VAR)模型進行檢驗的方法��,適用于對多重一階單整I(1)序列進行協整檢驗�����。JJ檢驗有兩種:特征值軌跡檢驗和最大特征值檢驗�。我們可以調用urca包中的ca.jo命令完成這兩種檢驗�。其語法:
ca.jo(x, type = c("eigen",
"trace"), ecdet = c("none", "const", "trend"), K = 2,spec=c("longrun",
"transitory"), season = NULL, dumvar = NULL)
其中:x為矩陣形式數據框��;type用來設置檢驗方法���;ecdet用于設置模型形式:none表示不帶截距項�,const表示帶常數截距項�����,trend表示帶趨勢項����。K表示自回歸序列的滯后階數���;spec表示向量誤差修正模型反映的序列間的長期或短期關系���;season表示季節效應�;dumvar表示啞變量設置���。
set.seed(12345)
e1=rnorm(250,0,0.5)
e2=rnorm(250,0,0.5)
e3=rnorm(250,0,0.5)
#模擬沒有移動平均的向量自回歸序列���;
u1.ar1=arima.sim(model=list(ar=0.75), innov=e1, n=250)
u2.ar1=arima.sim(model=list(ar=0.3), innov=e2, n=250)
y3=cumsum(e3)
y1=0.8*y3+u1.ar1
y2=-0.3*y3+u2.ar1
#合并y1,y2,y3構成進行JJ檢驗的數據庫���;
y.mat=data.frame(y1, y2, y3)
#調用urca包中cajo命令對向量自回歸序列進行JJ協整檢驗
vecm=ca.jo(y.mat)
jo.results=summary(vecm)#cajorls命令可以得到限制協整階數的向量誤差修正模型的最小二乘法回歸結果
vecm.r2=cajorls(vecm, r=2);vecm.r2
## Call:lm(formula = substitute(form1), data = data.mat)
## Coefficients:
## y1.d y2.d y3.d
## ect1 -0.33129 0.06461 0.01268
## ect2 0.09447 -0.70938 -0.00916
## constant 0.16837 -0.02702 0.02526
## y1.dl1 -0.22768 0.02701 0.06816
## y2.dl1 0.14445 -0.71561 0.04049
## y3.dl1 0.12347 -0.29083 -0.07525
## $beta
## ect1 ect2
## y1.l2 1.000e+00 0.0000
## y2.l2 -3.402e-18 1.0000
## y3.l2 -7.329e-01 0.2952
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
