一文簡述如何使用嵌套交叉驗證方法處理時序數據
本文討論了對時序數據使用傳統交叉驗證的一些缺陷���。具體來說���,我們解決了以下問題:
在不造成數據泄露的情況下���,對時序數據進行分割;
在獨立測試集上使用嵌套交叉驗證得到誤差的無偏估計;
對包含多個時序的數據集進行交叉驗證��。
本文主要針對缺乏如何對包含多個時間序列的數據使用交叉驗證的在線信息���。
本文有助于任何擁有時間序列數據�,尤其是多個獨立的時間序列數據的人�。這些方法是在醫療研究中被設計用于處理來自多個參與人員的醫療時序數據的��。
一�、交叉驗證
交叉驗證(CV)是一項很流行的技術��,用于調節超參數���,是一種具備魯棒性的模型性能評價技術��。兩種最常見的交叉驗證方式分別是 k 折交叉驗證和 hold-out 交叉驗證�。
由于文獻中術語的不同����,本文中我們將明確定義交叉驗證步驟�����。首先�,將數據集分割為兩個子集:訓練集和測試集����。如果有需要被調整的參數�����,我們將訓練集分為訓練子集和驗證集�����。模型在訓練子集上進行訓練�,在驗證集上將誤差最小化的參數將最終被選擇����。最后����,模型使用所選的參數在整個訓練集上進行訓練���,并且記錄測試集上的誤差����。
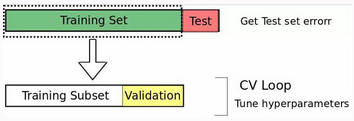
圖 1: hold-out 交叉驗證的例子
數據被分為訓練集和測試集�。然后訓練集進一步進行分割:一部分用來調整參數(訓練子集)�����,另一部分用來驗證模型(驗證集)�����。
為什么時序數據的交叉驗證會有所不同?
在處理時序數據時�����,不應該使用傳統的交叉驗證方法(如 k 折交叉驗證)�����,原因有2:
1. 時序依賴
為了避免數據泄露�����,要特別注意時間序列數據的分割��。為了準確地模擬「我們現在所處��、預測未來的真實預測環境」(Tashman
2000)�����,預測者必須保留用于擬合模型的事件之后發生的事件的數據�����。因此���,對于時間序列數據而言���,我們沒有使用 k 折交叉驗證�,而是使用
hold-out 交叉驗證���,其中一個數據子集(按照時間順序分割)被保留下來用于驗證模型性能�。例如�����,圖 1
中的測試集數據在時間順序上是位于訓練數據之后的�。類似地�����,驗證集也在訓練集之后�。
2. 任意選擇測試集
你可能注意到了�����,圖 1
中測試集的選擇是相當隨意的�����,這種選擇也意味著我們的測試集誤差是在獨立測試集上不太好的誤差估計����。為了解決這個問題�,我們使用了一種叫做嵌套交叉驗證(Nested
Cross-Validation)的方法�。嵌套交叉驗證包含一個用于誤差估計的外循環��,以及一個用于調參的內循環(如圖 2
所示)���。內循環所起的作用和之前談到的一樣:訓練集被分割成一個訓練子集和一個驗證集���,模型在訓練子集上訓練����,然后選擇在驗證集上能夠使誤差最小化的參數���。但是�,現在我們增加了一個外循環�,它將數據集分割成多個不同的訓練集和測試集�,為了計算模型誤差的魯棒估計�����,對每一次分割的誤差求平均值���。這樣做是有優勢的:
嵌套交叉驗證過程可以提供一個幾近無偏的真實誤差估計����。(Varma and Simon 2006)
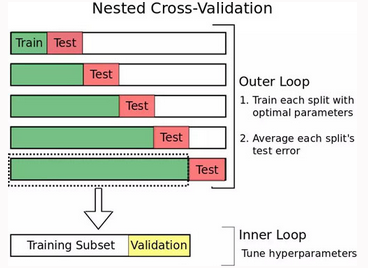
圖 2: 嵌套交叉驗證示例
二��、用于時間序列的嵌套交叉驗證
我們推薦兩種嵌套交叉驗證的方法�����,來處理僅具有一個時間序列的數據�����。我們也會處理來自一個病人/參與者的多天醫療數據:
預測后一半(Predict Second Half)
日前向鏈(Day Forward-Chaining)
1. 預測后一半
第一種方法「預測后一半」�,這是嵌套交叉驗證的「基本情況」�����,只有一次訓練/測試分割�。它的優勢是這種方法易于實現;然而�����,它仍然面臨著任意選擇測試集的局限性���。前一半數據(按照時間分割的)作為訓練集�,后一半數據成為測試集���。驗證集的大小可以根據給定問題的不同而變化(例如圖
3 中的例子用一天的數據作為驗證集)�����,但是保證驗證集的時間順序在訓練子集后面是非常重要的�����。

圖 3: 預測后一半嵌套交叉驗證方法
2. 日前向鏈(Day Forward-Chaining)
預測后一半嵌套交叉驗證方法的一個缺陷是 hold-out
測試集的任意選擇會導致在獨立測試集上預測誤差的有偏估計�����。為了生成對模型預測誤差的更好估計��,一個常用的方法就是進行多次訓練/測試分割�,然后計算這些分割上的誤差平均值�。我們使用日前向鏈技術是一種基于前向鏈(Forward-Chaining)的方法(在文獻中也被稱為
rolling-origin evaluation(Tashman�����,2000)和 rolling-origin-recalibration
evaluation(Bergmeir &
Benitez����,2012))�。利用這種方法���,我們將每天的數據作為測試集����,并將以前的所有數據分配到訓練集中��。例如���,如果數據集有五天�����,那么我們將生成三個不同的訓練和測試分割����,如圖
4
所示����。請注意���,在本示例中���,我們有三次拆分�����,而不是五次拆分���,因為我們需要確保至少有一天的訓練和驗證數據可用��。該方法產生許多不同的訓練/測試分割�����,并且對每個分割上的誤差求平均��,以計算模型誤差的魯棒估計����。
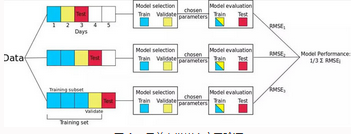
圖 4: 日前向鏈嵌套交叉驗證
注意�����,在這個例子中我們使用「日」前向鏈�����,但是也可以在每個數據點上進行迭代����,而不是按天迭代(但這明顯意味著更多的拆分)���。
三�����、多時序嵌套交叉驗證
現在有兩種分割單個時間序列的方法�����,接下來我們將討論如何處理具有多個不同時間序列的數據集����。同樣�����,我們使用兩種方法:
1. 常規(regular)
「常規」嵌套交叉驗證(regular nested
cross-validation)的訓練集/驗證集/測試集分割基本思路和之前的描述是一樣的��。唯一的變化是現在的分割包含了來自數據集中不同參與者的數據�。如果有兩個參與者
A 和 B�����,那么訓練集將包含來自參與者 A 的前半天的數據和來自參與者 B 的前半天的數據��。同樣����,測試集將包含每個參與者的后半天數據�����。
2. 群體知情(Population-Informed)
對于「群體知情嵌套交叉驗證」方法而言�,我們利用了不同參與者數據之間的獨立性�����。這使得我們打破嚴格的時間順序�,至少在個人數據之間(在個人數據內打破嚴格時序仍然是必要的)�。由于這種獨立性�����,我們可以稍微修改常規嵌套交叉驗證算法?����,F在����,測試集和驗證集僅包含來自一個參與者(例如參與者
A)的數據����,并且數據集中所有其他參與者的所有數據都被允許存在于訓練集中����。圖 5
描述了這種方法是如何適用于群體知情的日前向鏈嵌套交叉驗證的�����。該圖顯示�����,參與者 A 第 18
天的數據是測試集(紅色)�����,之前三天是驗證集(黃色)��,訓練集(綠色)包含參與者 A 的所有先前數據以及其他參與者(本例中為 B�、C���、D 和
E)的所有數據��。需要強調的一點是����,由于其他參與者的時間序列的獨立性����,使用這些參與者的「未來」觀測不會造成數據泄漏�。
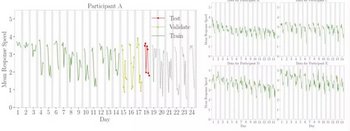
圖 5: 群體知情日前向鏈(Population-Informed Day Forward-Chaining)交叉驗證示例
其中除了對參與者 A 的日前向鏈方法(左圖)���,我們也允許其他參與者的數據存在于訓練集中(右圖)�����。請注意����,灰色線條表示參與者睡眠的時間�����。
最后����,我們總結了不同嵌套交叉驗證方法的優缺點��,特別是獨立測試集誤差估計的計算時間和偏差�����。分割的次數假定數據集包含 p 個參與者���,以及每個參與者共有 d 天的數據�����。
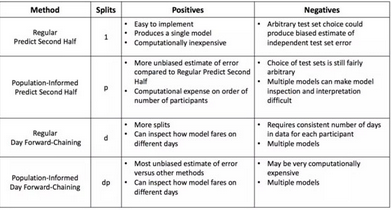
四�、總結
我們首先回顧了交叉驗證�,并列舉了使用嵌套交叉驗證的基本原理�。然后討論了如何在不造成數據泄漏的情況下分割單個時間序列數據���,具體提出了兩種方法:預測后一半嵌套交叉驗證和日前向鏈嵌套交叉驗證�。接著我們討論了如何處理多個獨立的時間序列�,兩種方法:常規嵌套交叉驗證和群體知情嵌套交叉驗證�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
