基于R做聚類分析
一 數據集
setwd("C://Users//admin//Desktop//DATA") #設置路徑
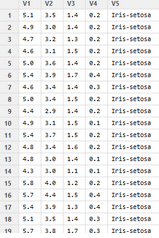
Iris=read.table("Iris.txt")
names(Iris)=c("v1","v2","v3","v4","label") #設置變量名
var=Iris$label #將標簽賦予var
var=as.character(var) #將var轉換為字符型
二 K-Medoids聚類
K-中心點算法與K-均值算法在原理上十分接近��,主要區別在于在選取每個類別的中心點時��,K-中心點算法在類別內選取到其余樣本距離之和最小的樣本為中心����。
K-中心點算法在R中的軟件包為Cluster主要函數為pam ().
install.packages("cluster")
library(cluster)
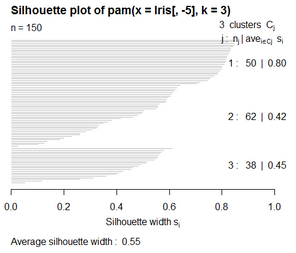
kc=pam(Iris[,-5],3) print(kc)
kc=pam(Iris[,-1],3,cluster.only=TRUE) print(kc)
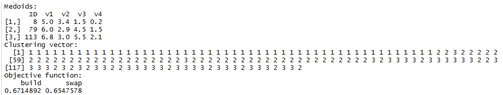
Medoids:該項指明聚類完成時聚類完成的各類別的中心點分別是哪幾個樣本點����,它們的變量取值為多少��。
Objective function:該項給出了build和swap兩個過程中目標方程的值����。其中����,build過程用于在未指定初始中心點情況下�����,對于最優初始中心點的尋找��;而swap過程則用于在初始中心點的基礎上���,對目標方程尋找其能達到局部最優類別劃分狀態�����。
三 EM聚類
library(mclust)
fit_em=Mclust(Iris[,-5])
summary(fit_em)
fit_em=mclustBIC(Iris[,-5]) # 第二個聚類函數
BICsum=summary(fit_em,data=Iris[,-5])

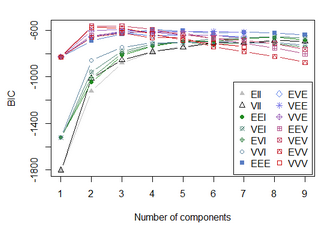
這里有聚類結果可視化展示�,不過對于高維數據�,打算再研究一下�����。 
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
