R語言使用層次聚類處理數據
凝聚層次聚類說明
層次聚類可以分成凝聚(agglomerative,自底向上)和分裂(divisive�,自頂向下)兩種方法來構建聚類層次����,但不管采用那種算法���,算法都需要距離的相似性度量來判斷對數據究竟是采取合并還是分裂處理��。
凝聚層次聚類操作
采用層次聚類����,將客戶數據集分成不同的組�����,從github上下載數據:
https://github.com/ywchiu/ml_R_cookbook/tree/master/CH9下載
customer.csv文件
customer = read.csv("d:/R-TT/example/customer.csv")
head(customer,10)
ID Visit.Time Average.Expense Sex Age
1 1 3 5.7 0 10
2 2 5 14.5 0 27
3 3 16 33.5 0 32
4 4 5 15.9 0 30
5 5 16 24.9 0 23
6 6 3 12.0 0 15
7 7 12 28.5 0 33
8 8 14 18.8 0 27
9 9 6 23.8 0 16
10 10 3 5.3 0 11
檢查數據集結構:
str(customer)
'data.frame': 60 obs. of 5 variables:
$ ID : int 1 2 3 4 5 6 7 8 9 10 ...
$ Visit.Time : int 3 5 16 5 16 3 12 14 6 3 ...
$ Average.Expense: num 5.7 14.5 33.5 15.9 24.9 12 28.5 18.8 23.8 5.3 ...
$ Sex : int 0 0 0 0 0 0 0 0 0 0 ...
$ Age : int 10 27 32 30 23 15 33 27 16 11 ...
對客戶數據進行歸一化處理:
數據標準化(歸一化)處理是數據挖掘的一項基礎工作����,不同評價指標往往具有不同的量綱和量綱單位��,這樣的情況會影響到數據分析的結果�,為了消除指標之間的量綱影響����,需要進行數據標準化處理���,以解決數據指標之間的可比性��。原始數據經過數據標準化處理后�����,各指標處于同一數量級��,適合進行綜合對比評價�。以下是兩種常用的歸一化方法:
一�����、min-max標準化(Min-Max Normalization)
也稱為離差標準化�,是對原始數據的線性變換����,使結果值映射到[0 - 1]之間�。轉換函數如下:
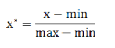
其中max為樣本數據的最大值�,min為樣本數據的最小值�����。這種方法有個缺陷就是當有新數據加入時���,可能導致max和min的變化�,需要重新定義�。
二���、Z-score標準化方法
這種方法給予原始數據的均值(mean)和標準差(standard deviation)進行數據的標準化����。經過處理的數據符合標準正態分布�����,即均值為0���,標準差為1�,轉化函數為:
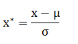
其中為所有樣本數據的均值�����,為所有樣本數據的標準差�。
此處采用方法二
customer = scale(customer[,-1])
customer
Visit.Time Average.Expense Sex Age
[1,] -1.20219054 -1.35237652 -1.4566845 -1.23134396
[2,] -0.75693479 -0.30460718 -1.4566845 0.59951732
[3,] 1.69197187 1.95762206 -1.4566845 1.13800594
[4,] -0.75693479 -0.13791661 -1.4566845 0.92261049
[5,] 1.69197187 0.93366567 -1.4566845 0.16872643
[6,] -1.20219054 -0.60226893 -1.4566845 -0.69285535
[7,] 0.80146036 1.36229858 -1.4566845 1.24570366
[8,] 1.24671612 0.20737101 -1.4566845 0.59951732
[9,] -0.53430691 0.80269450 -1.4566845 -0.58515763
[10,] -1.20219054 -1.40000240 -1.4566845 -1.12364624
使用自底向上的聚類方法處理數據集:
hc = hclust(dist(customer,method = "euclidean"),method = "ward.D2")
> hc
Call:
hclust(d = dist(customer, method = "euclidean"), method = "ward.D2")
Cluster method : ward.D2
Distance : euclidean
Number of objects: 60
最后�����,調用plot函數繪制聚類樹圖
plot(hc,hang = -0.01,cex =0.7)
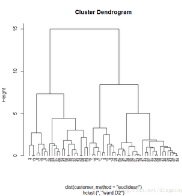
使用離差平方和繪制聚類樹圖
還可以使用最短距離法(single)來生成層次聚類并比較以下兩者生成的聚類樹圖的差異:
hc2 = hclust(dist(customer),method = "single")
plot(hc2,hang = -0.01,cex = 0.7)
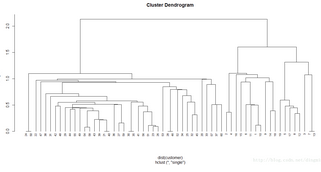
使用最短距離法繪制聚類樹圖
凝聚層次聚類原理
層次聚類是一種通過迭代來嘗試建立層次聚類的方法�,通?���?梢圆捎靡韵聝煞N方式完成:
凝聚層次聚類
這是一個自底向上的聚類方法����。算法開始時��,每個觀測樣例都被劃分到單獨的簇中��,算法計算得出每個簇之間的相似度(距離)����,并將兩個相似度最高的簇合成一個簇�,然后反復迭代�����,直到所有的數據都被劃分到一個簇中��。
分裂層次聚類
這是一種自頂向下的聚類算法�,算法開始時���,每個觀測樣例都被劃分同一個簇中����,然后算法開始將簇分裂成兩個相異度最大的小簇�,并反復迭代�,直到每個觀測值屬于單獨一個簇���。
在執行層次聚類操作之前�����,我們需要確定兩個簇之間的相似度到底有多大���,通常我們會使用一些距離計算公式:
最短距離法(single linkage)�����,計算每個簇之間的最短距離:
dist(c1,c2) = min dist(a,b)
最長距離法(complete linkage),計算每個簇中兩點之間的最長距離:
dist(c1,c2) = max dist(a,b)
平均距離法(average linkage),計算每個簇中兩點之間的平均距離:
最小方差法(ward),計算簇中每個點到合并后的簇中心的距離差的平方和�����。
調用plot函數繪制聚類圖����,樣例的hang值小于0,因此聚類樹將從底部顯示標簽���,并使用cex將坐標軸上的標簽字體大小縮小為正常的70%�����,此外��,為了比較最小方差法和最短距離法在層次聚類上的差異�����,我們還繪制了使用最短距離法得到的聚類樹圖��。
分裂層次聚類
調用diana函數執行分裂層次聚類
library(cluster)
dv = diana(customer,metric = "euclidean")
調用summary函數輸出模型特征信
summary(dv)
如果想構建水平聚類樹
library(magrittr)
dend = customer %>% dist %>% hclust %>% as.dendrogram
dend %>% plot(horiz = TRUE,main = "Horizontal Dendrogram")
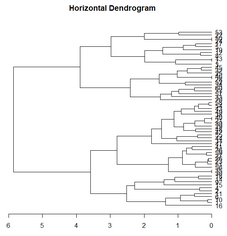
水平聚類樹
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
