幾個常用機器學習算法 - 決策樹算法
1 決策樹算法(Decision Tree)是從訓練數據集中歸納出一組分類規則的過程�。
實際操作中����,與訓練數據集不相矛盾的決策樹可能有多個����,也可能一個都沒有����;理想情況是找到一個與訓練數據矛盾較小的決策樹��,同時也具有良好的泛化能力�。
2 決策樹結構:
有向邊
節點
-內部節點: 數據的特征
-葉節點:數據的類別
決策樹準則:每個實例都被一條路徑覆蓋�����,且僅被一條路徑覆蓋
3 決策樹算法過程
特征選擇
決策樹生成過程就是劃分數據集的過程����,合適地選取特征能幫助我們將數據集從無序數據組織為有序����;
有很多方法可以劃分數據集��,決策樹算法根據信息論來度量信息�;
信息論中有很多概念��,不同的決策樹生成算法使用不同的信息論概念來進行特征選擇����。
決策樹生成
有諸如ID3, C4.5, CART等算法用于生成決策樹�;
ID3和CART4.5的差別在于用于特征選擇的度量的不同
-ID3使用信息增益進行特征選擇
-C4.5使用信息增益比進行特征選擇
-以上兩個算法流程:迭代的尋找當前特征中最好的特征進行數據劃分����,直到所有特征用盡或者劃分后的數據的熵足夠小��。
ID3核心思想:信息增益越大說明該特征對于減少樣本的不確定性程度的能力越大�����,也就代表這個特征越好�����。
C4.5核心思想:某些情況(比如按照身份證號��、信用卡號�、學號對數據進行分類)構造的樹層數太淺而分支又太多����,而這樣的情況對數據的分類又往往沒有意義����,所以引入信息增益比來對分支過多的情況進行適當“懲罰”���。具體情景解釋可見這篇博客
CART我還沒了解過�����,暫不介紹
4 決策樹生成算法得到的樹對訓練數據的分類很準確����,但對未知數據的分類卻沒那么準確�,容易過擬合�;因為決策樹考慮的特征太多���,構建得太復雜�����。
所以我們需要對決策樹進行剪枝:從已生成的樹上裁掉一些子樹或葉節點�����,并將其根節點或父節點作為新的葉節點����,以此簡化樹����。
剪枝算法很多����,這里引入一種簡單的:極小化決策樹整體的損失函數���。
設樹 T 的葉節點個數為 |T|, t 是樹 T 的葉節點�����,該葉節點有Nt
個樣本點����,其中 k 類的樣本點有Ntk個���, k = 1,2,…,k, Ht(T)是葉節點 t 上的經驗熵��,α≥0
為參數��,決策樹的損失函數可定義如下
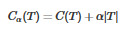
而經驗熵為
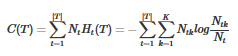
其中���,為了簡潔����,令
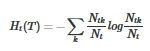
所以��,上面的損失函數可以記為
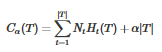
各個符號定義如下:
C(T) 表示模型對訓練數據的預測誤差��,即擬合程度
|T| 表示模型復雜度
α
控制以上兩者之間的平衡
當α
確定時�,樹越大����,與訓練數據的擬合就越好�,C(T)越小��,但是樹的復雜度也會上升�����,|T| 上升��;而樹越小���,樹的復雜度就越低��,|T| 越小��,但往往和訓練數據的擬合程度不好�,C(T) 又會上升
較大的α
使得生成較簡單的樹��,較小的α使得生成較復雜的樹����,當α=0
�����,就完全不考慮樹的復雜度了��,相當于不進行剪枝操作
決策樹生成只考慮提高信息增益來更好擬合訓練數據���,但決策樹剪枝則通過優化損失函數來減少樹的復雜度�;可以說決策樹生成學習的是局部模型��,而決策樹剪枝學習的是整體模型
剪枝算法流程
計算每個節點的經驗熵
遞歸地從樹的葉節點向上回縮:設一組葉節點
回縮到父節點前后的整體樹分別是TB
和TA����,其對應的損失函數值分別是Cα(TB)和Cα(TA)
����,如果
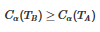
那么將父節點變為新的葉節點�,即剪枝
重復執行步驟2�,直到不能再繼續為止���,得到損失函數最小的子樹Tα
5
代碼部分����,先挖個坑�。��。��。過段時間回來填
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
