信用卡通不過����?用數據分析技術����,帶你深度解析信用卡評分體系
隨著互聯網金融時代的到來��,信用評分體系顯得越發重要���,本文就解讀信用卡評分體系是如何建立的�。
客戶信息涉及到很多因素���,因此許多因素無法在機器學習模型中進行探討��,這里收集了大部分互聯網金融公司在信用卡申請時能獲取到的信息���。
目標
1. 使用機器學習構建信用卡評分模型���,獲得自變量分箱結果��;
2. 并由評分模型得出最優的cutoff值�,并對模型進行評價��;
3. 再由新的樣本集對評分卡進行測試�����,輸出預測結果�����。
數據
我使用了Kaggle的兩個數據集�。
Kaggle數據集鏈接:
https://www.kaggle.com/yuzijuan/credit-card-scoring/data
環境和工具:
Rstudio����,plyr�����,rJava��,smbinning�,prettyR
我首先對兩個數據集進行探索性分析��,剔除掉無法納入模型的變量��,例如ID�,取值為空的變量����,取值僅為一類的變量等�;再探索配偶收入變量問題時���,由于值絕大部分為0���,將該變量變為二分類變量���,取值為有收入與無收入���;針對異常值過大的變量�,采用蓋帽法��,用99分位點值代替極大異常值�����,有1分位點值代替極小異常值等等方法��,數據清洗完后����,再用smbinning包進行cart分箱�����,帶入評分卡模型���,獲得評分卡�����,最后將其運用到測試集上��。
開始
首先�,導入必要的庫和數據集����,進行探索性數據分析����,并剔除掉無法納入模型的變量����。
導入庫

導入數據

剔除無法納入模型的變量
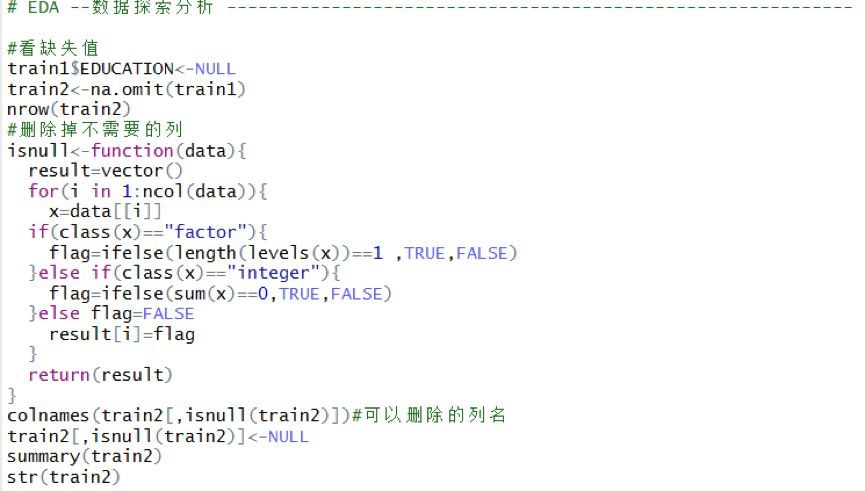
由于評分卡模型一般分數越高�����,表示信用越好���,故需要將信用好的類別得分記為1��,信用不好的類別得分記為0����。
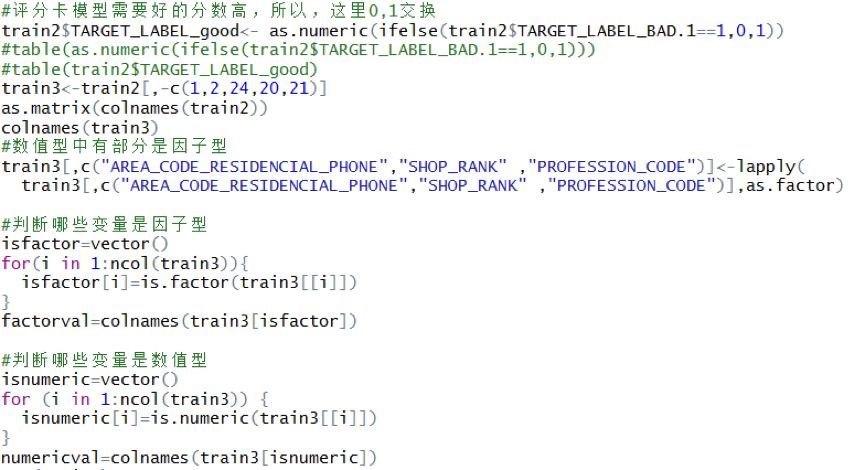
為更有效分箱����,獲取了因子型變量集factorval和數值型變量集numericval����,分別進行分箱處理���。
數值型變量分箱
為更有效進行數據處理����,對異常值可以進行蓋帽法處理���,代碼如下:

以年齡數值型變量舉例說明��,首先查看數據分布情況�,由于是因變量為二分類����,自變量為數值型�����,用t檢驗來檢驗兩分布是否有顯著性差別���,有顯著性差別才能進行分箱��,否則分箱結果無意義���。
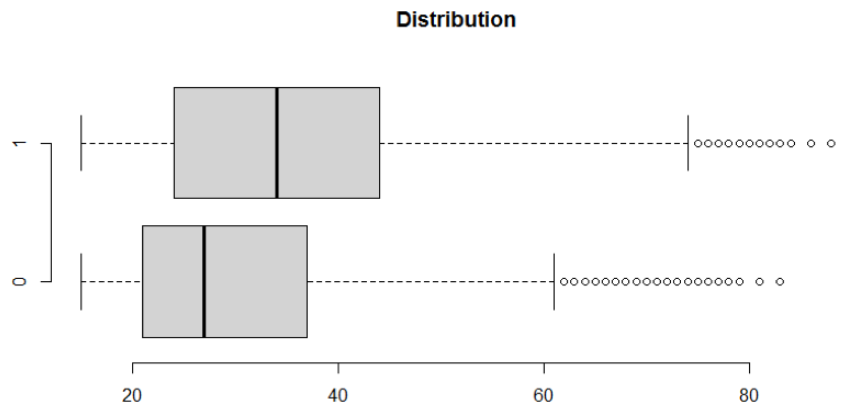
分布情況如上圖所示��,可以對其進行蓋帽法后再t檢驗和分箱處理����。t檢驗的原假設為兩分類組的均值相等��,結果表明原假設被拒絕��,認為兩分布具有顯著性差別�����,可以進行分箱����。

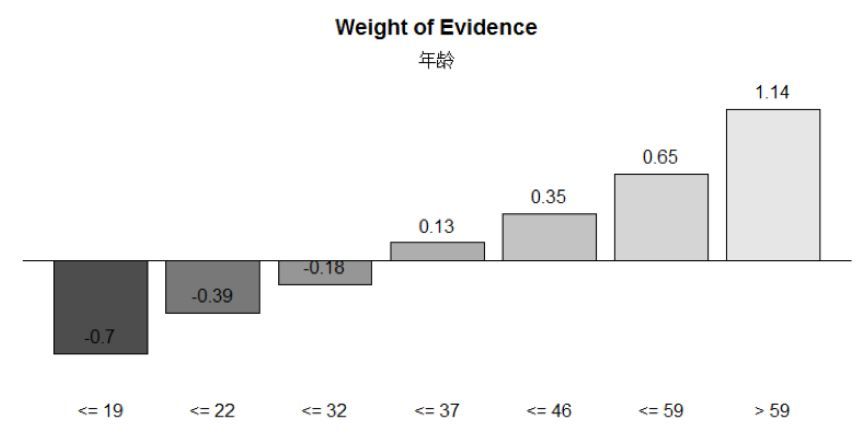
用的是smbinning包���,這個包中采用的是CART回歸樹進行屬性劃分��,數值型用函數smbinning()����,由樹的結果可知���,劃分點為19�,22��,32�����,37�,46�����、59六個值��,劃分為7個屬性區間��。

AGE的IV值為0.2004��,對AGE的WOE值畫圖���,得到分布呈現單調趨勢���,表明分箱結果良好����,可以納入模型�。
用AGE進行分箱的代碼如下:

類推其他連續變量����。通過調用numericalval可知共有7個數值型變量�,由于兩個數值型變量取值過于集中�,后續將作為分類變量處理��,故得到5個變量的IV值����。

因子型變量分箱
以性別分類變量舉例說明����,首先對性別變量中的異常值進行處理��,這種類別變量一般將異常值歸為多數這類���。查看分布情況可知女性的守信情況似乎比男性好一些��。性別變量的WOE值區分得也很明顯�����。

在進行分箱之前同數值型變量一樣��,要檢驗兩分布是否有顯著性差別�����,由于因變量和自變量均為分類變量�����,故用卡方檢驗��。原假設為兩分布之間無顯著性差別���,卡方檢驗結果表明拒絕原假設�,認為兩樣本有顯著性差別�,可以進行分箱�����。
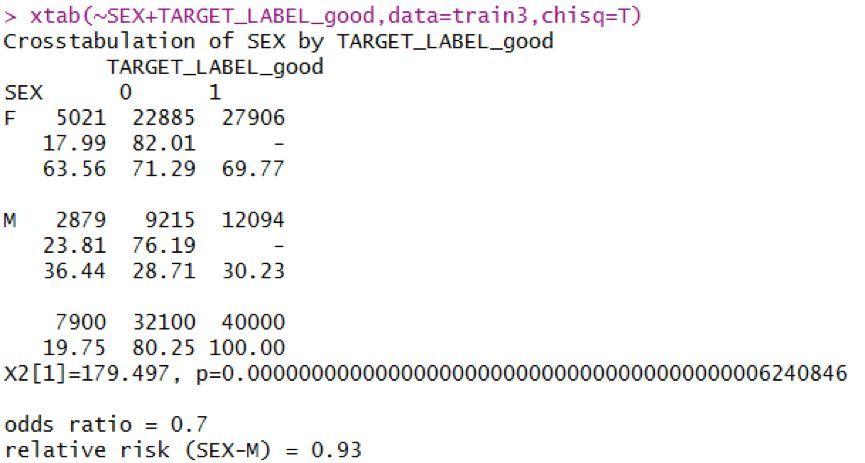
分類變量分箱也采用的是smbinning包�,不過smbinning包中就是用原分類值進行屬性劃分����,未對劃分屬性處理�����,分類變量用的函數是smbinning.factor()�,最后得到SEX的IV值為0.0274�。具體執行代碼如下:

再以配偶收入舉例說明���,這個變量原本是數值型變量����,由于取值過于集中到0�,故將該變量轉化為分類型變量再處理���,處理方式是將取值為0的作為無收入����,將取值大于0的作為有收入����。

得到混淆矩陣可以看出�����,有收入的似乎比無收入的守信情況好一些��,WOE圖的區別也較為明顯����。
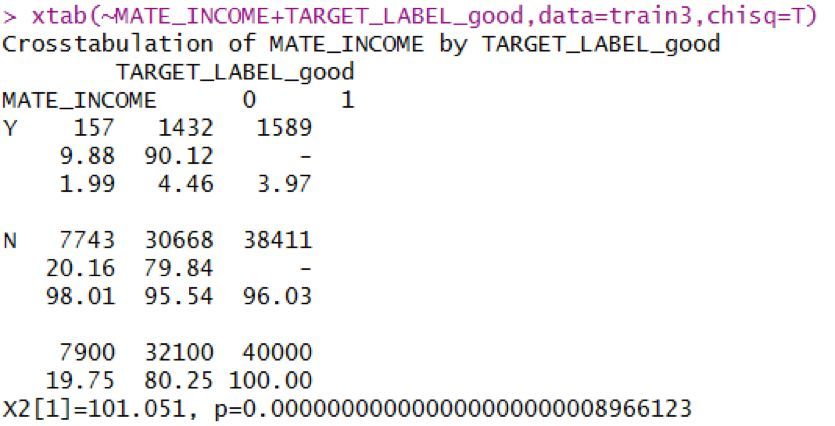
通過卡方檢驗也可以看出�,是否有收入對信用好否有顯著性影響�,可以進行分箱操作���。最后分箱得到IV值為0.0206�。具體代碼如下:
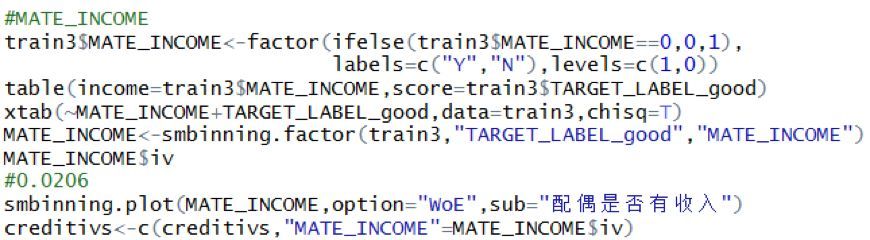
類推到其他因子型變量����,計算出得到所有變量的IV值����,存入creditivs中����。
建立評分卡
得到所有可分箱變量的IV值�����,一般認為IV值大于等于0.02的對構建評分卡具有一定的幫助����,故以0.02為分界點得到滿足條件的變量�。最后納入評分卡模型的變量分別是年齡���、工作時長(月)��、個人收入�、性別�����、婚姻狀態����、是否有自用手機�、配偶是否有收入��。
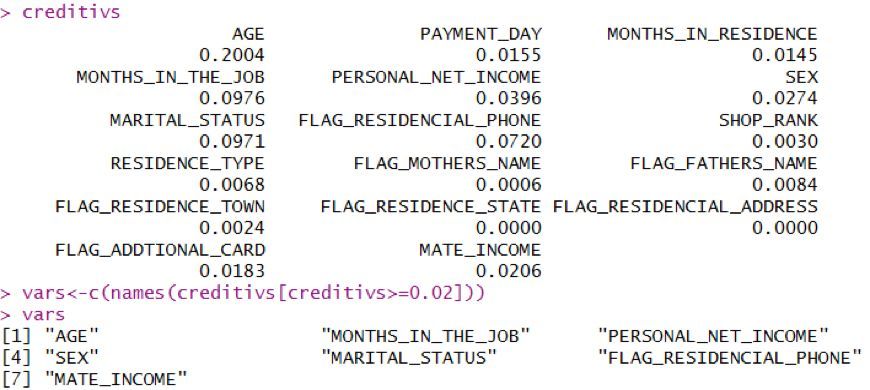
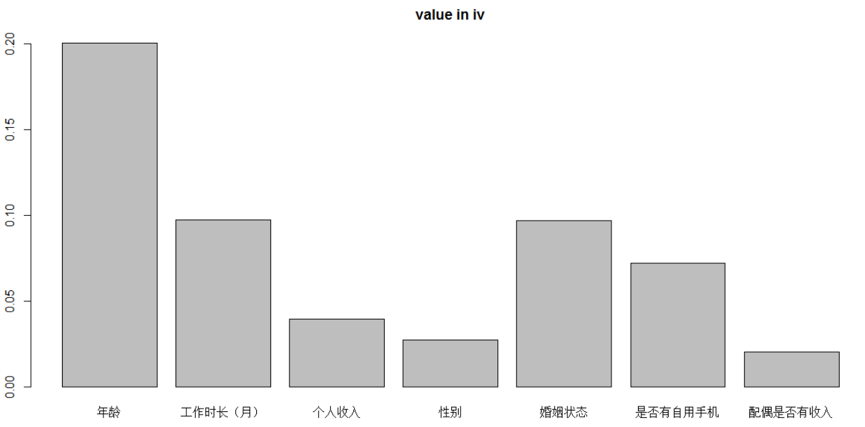
最后7個自變量的IV值的分布情況如下��,可以看到年齡�、婚姻狀態�、工作時長��、是否有自用手機這幾個變量的IV值較大��,表明這幾個變量對預測結果影響較大�����。
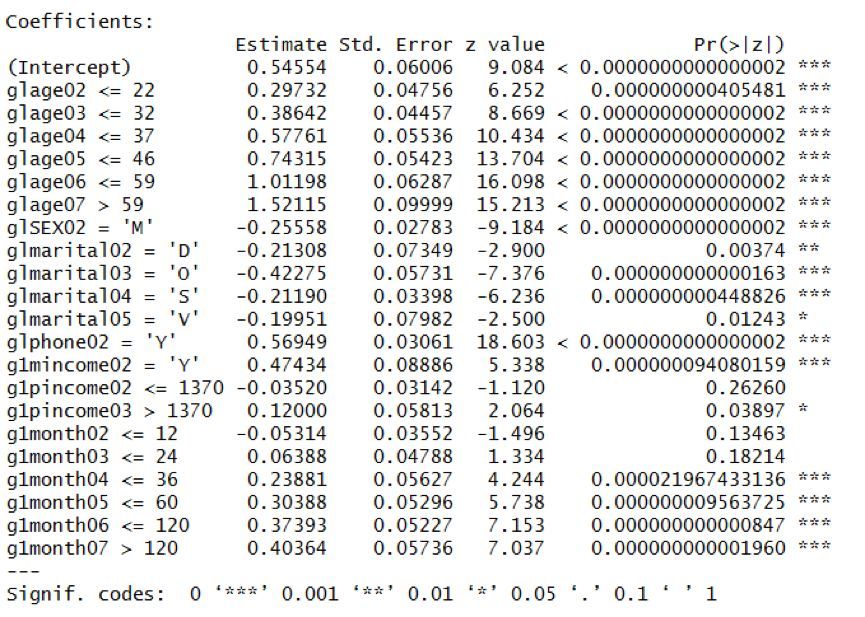
數值型分箱變量用函數smbinning.gen()����,因子型變量用函數smbinning.factor.gen()���,可以生成分箱后的結果�,分箱后生成的新列并因變量得到data2數據集���,通過邏輯回歸����,建立評分卡模型����。通過邏輯回歸結果可以看出分箱后的變量都較為顯著�����,表示分箱結果優良��。
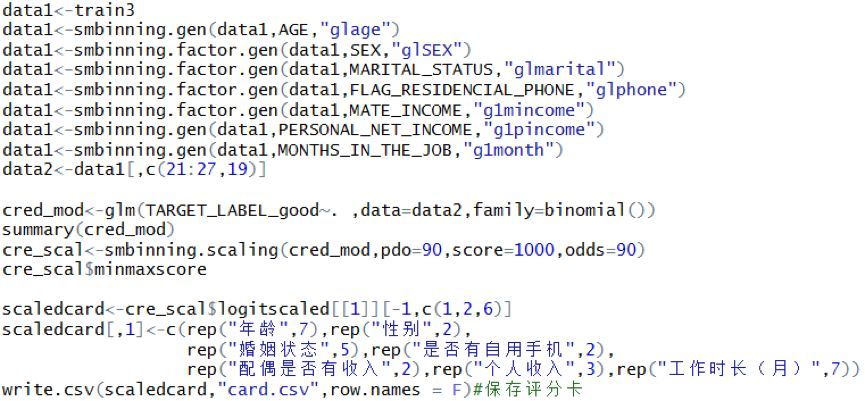
生成評分卡是用函數smbinning.scaling()���,通過調節pdo,score,odds三個參數���,使得評分卡最大值與最小值位于一個較好的范圍��。這里評分卡的區間為(389,888)���。
最后保存為新的csv文件���,評分卡就做好了�。具體代碼如下:
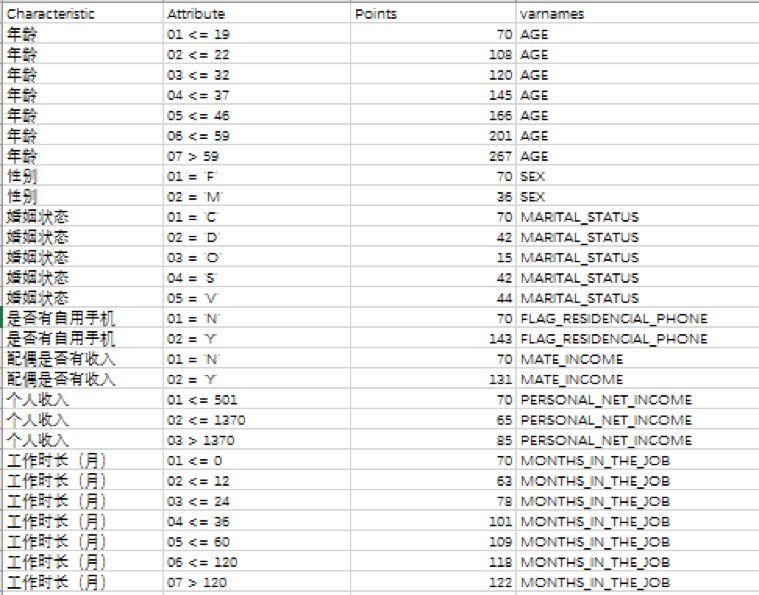
評分卡展示如下�����,points表示為評分卡的分值���。如年齡在45歲的客戶��,得分為166分�。
最后�����,你總得告訴領導或者同事�����,到底大于等于多少時�����,我們認為是好客戶�,這時還有最后一步��,就是求cutoff值�,將訓練數據通過函數smbinning.scoring.gen()可以得到客戶的得分�,由于訓練數據本身有是否違約這個變量�����,那么cutoff值有兩種選擇方式��,第一種基于業務發展現狀��,即公司是需要盈利增收����,還是公司需要控制風險���,然后商議討論選擇一個cutoff值���。下圖為客戶得分與客戶違約的箱體圖�����,1表示好客戶�����,0表示壞客戶���,可以看出好客戶的得分值會高于壞客戶的得分值���。
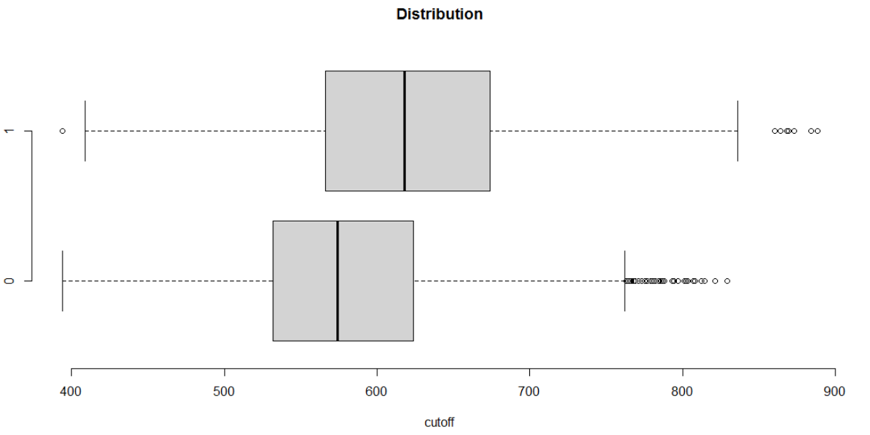
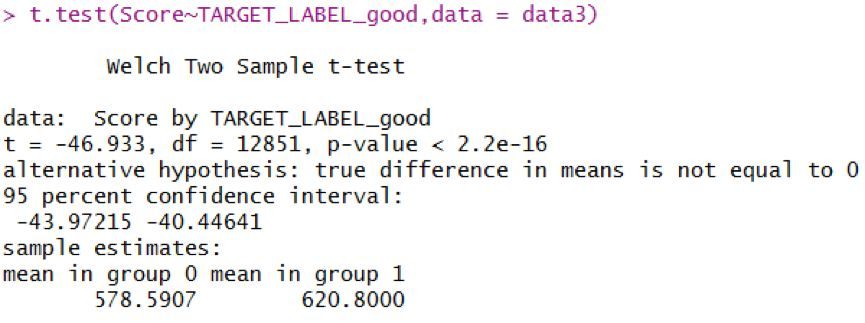
對客戶得分與客戶違約做t檢驗�,檢驗結果表明��,兩分布具備顯著性差別���,可以認為好客戶和壞客戶的得分會有顯著性差別���。壞客戶的得分集中在578分附近�,好客戶得分集中于620分附近�。
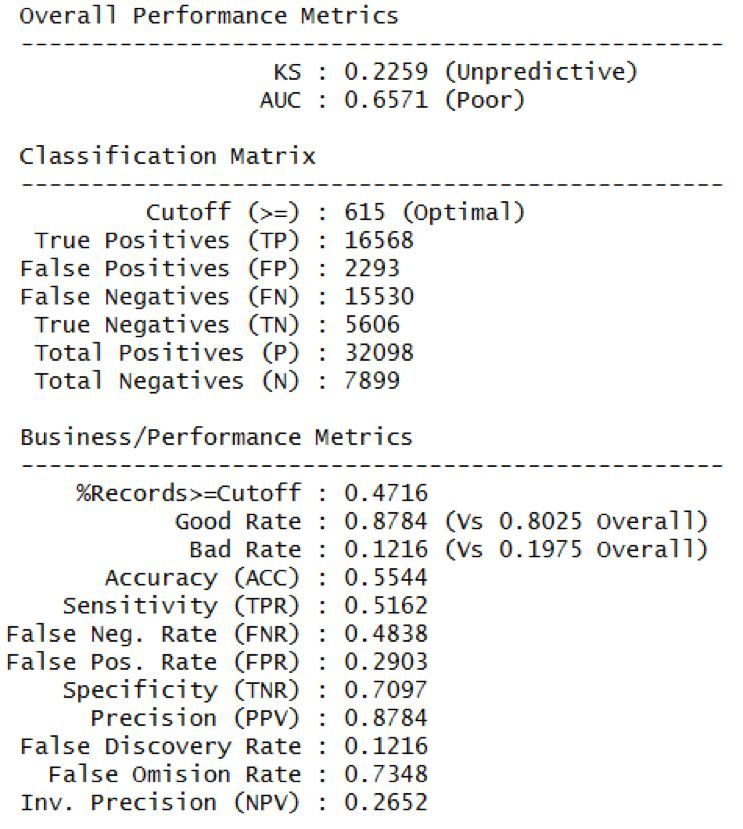
第二種獲得cutoff值的方式就是電腦自動計算最優cutoff值�,用的函數smbinning.metrics()�����,從輸出的報告可以看出��,最優cutoff值為615���,這樣劃分的話����,ROC曲線的AUC值為0.657�����,不算特別優良��,準確率(precision)達到87.8%�����。
具體執行代碼如下:
預測
針對新樣本��,我選擇用Excel工具獲得信用評分���,使用VLOOKUP函數可以很方便地得到想要的數據�,評分展示如下���,選擇cutoff值為615�,這里認為(600,620)的客戶為關注客戶��,信用情況中等�,620分以上的客戶信用情況良好���,600分以下的客戶信用情況堪憂���。
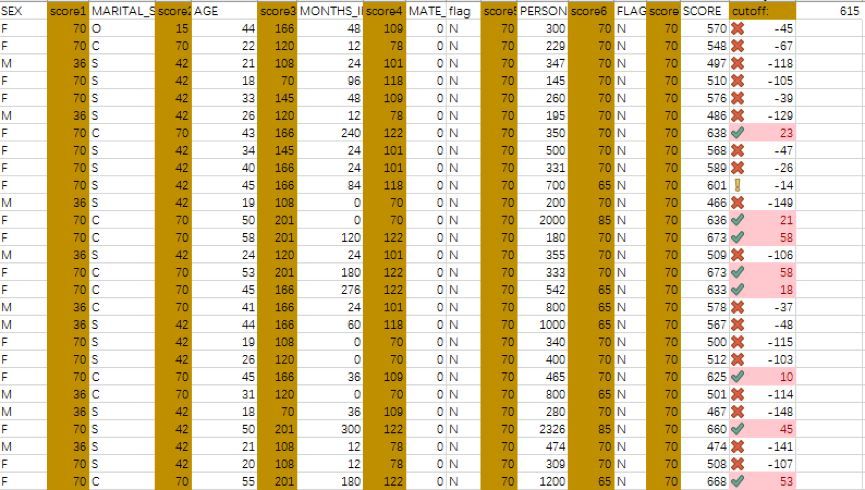
分別用���!�、√�����、×來表示中等���、優良��、較差的信用情況�。
結語
本案例不足之處在于:
1. 未對職業代碼���、商店等級代碼等信息進行提煉����,可能會忽略掉一些有可能對模型有影響的變量���。
2. Smbinning包在數值型變量分箱這一塊很強大�,但是對分類變量分箱結果不太盡如人意�����,可以考慮其他分箱方法�����。
3. 可以整合更多模型���,從而提高預測準確率�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
