Social Network 社交網絡分析_數據分析師
一:什么是SNA-社交網絡分析
社交網絡分析的威力何在�?我想幾個案例來說明��。
案例1:對一個毫無了解的組織(這個組織可以是一個公司���,亦或是一個組織)�����,如果能夠拿到這個組織成員之間的信息流動記錄(例如通話記錄/或郵件記錄)��,那么通過SNA可以分析出誰是這個組織的實際控制者(要知道有必要加上實際二字)���,誰是這些成員中有影響力的人����,那些成員更傾向于聚集在一起�。對上述問題的回答可以用來做公關-把精力用在對的人身上����;用來處理組織架構�;用來游說獲得支持--關系緊密的人會更傾向于支持同一種意見����,一方面是由于觀點相同所以關系緊密����,另一方面你的大部分朋友都支持的事情你總不會下臉來做那個少數派吧��。
案例2:舉個現實中的例子吧���,鵝廠剛推出朋友圈的時候我對這個產品的印象非常好��,因為它給我推薦的朋友有一些是很多年都沒有聯系�,不特意提起都想不起來名字的“朋友”��。包括人人網推薦的好友也是很精準的��。這些產品的背后就是用的SNA-朋友的朋友也是我的朋友���,敵人的朋友是我的敵人��,敵人的敵人是我的朋友��,朋友的敵人是我的敵人���。
這兩個案例是直觀印象中的社交網絡分析���,網絡中的節點是人���。如果把SNA只用在人身上那就太狹隘了���。相同的思想完全可以用在物身上��。例如:
案例3:豆瓣FM也是我很喜歡的一款產品---與你喜歡的音樂不期而遇����。一些歌曲是我對某一個時期的感覺印記�,有些印記記憶猶新�,有些印記逐漸模糊����。時不時就能在豆瓣FM和這些或清晰或模糊的印記不期而遇��,讓人驚喜���。為什么豆瓣FM能做到這點那���?是它對歌曲按照什么節奏/曲調/風格/歌詞做了分類嗎���?如果你這樣認為那就太傻太天真了��。這里的SNA每一首歌就是網絡中的每個節點��,而你的喜歡或不再播放就給你聽過的歌曲之間加強/減弱了聯系��。
經過上面三個案例����,可以對SNA有個初步了解����。
二:我的好友圈
一般來說有兩大途徑來獲得好友圈:1)社交應用/社交網站���,比如人人/微博/微信����。2)通信記錄-電話/郵件/短信��。后者數據都掌握在相應的運營商�����,前者的數據可以從應用開放的API或者簡單粗暴一點自己寫蜘蛛爬��。
我采用寫爬蟲的方式得到了人人的好友圈��。抓了兩層好友�����,即我的好友���,和我好友的好友��。其實這個層數可以自己設定����,用遞歸函數很容易實現�����。唯一消耗的是運行時間和存儲��。即使只抓兩層好友圈�����,用我的筆記本也跑了15分鐘�����。
接下來該networkx登場了����。一通運算之后得到如下結果:
1)兩層好友圈
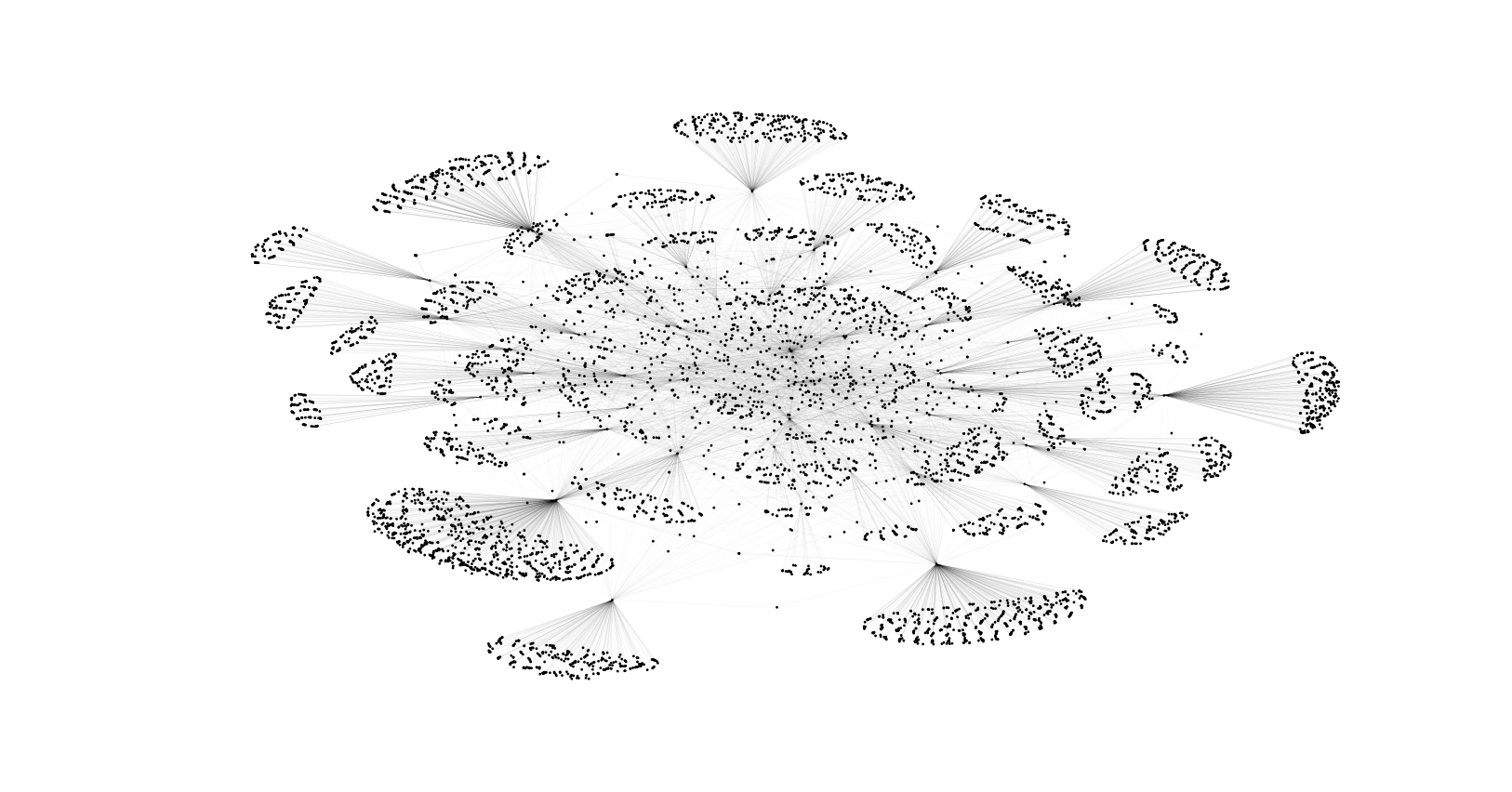
這是對7169個好友關系的做圖�����。當然最中心的點是我自己��??梢钥吹街車蝗κ窍鄬铝⒌?/span>“云”����,那是因為我只抓了兩層的原因����。
七千多個好友���,這么多層關系����,如何分析�����?別擔心�����,社交網絡分析不是一個新興的領域��,看米國文獻說這個領域從六七十年代就有了���,只不過是近十年火起來的��。所以有一大堆現成的算法來基本搞定你的大部分需求��。
對七千多個好友的基本分析如下:
---------------2014-06-08 21時32分16秒開始整體分析----------------
社交網總共有7169個好友
排名前10的好友數
1--徐希文--909
2--劉杉--607
3--李超--505
4--colipso--405
5--呂秀芳--343
6--藏新汀--336
7--王大舸--312
8--王卉卉--258
9--孫昊--255
10--楊子旭--248
--------2014-06-08 21時32分16秒開始受歡迎指數分析(基于closenes centrality)------------
受歡迎指數排名前10的好友為
1--colipso--0.51
2--馬佳--0.50
3--徐希文--0.40
4--賈麗娜--0.40
5--洛鋒--0.39
6--張偉--0.39
7--陳欣--0.39
8--王蘊杰--0.39
9--孫峰--0.39
10--張寧--0.38
---------2014-06-08 21時35分15秒開始樞紐指數分析(基于Betweenness centrality算法 )----------
處于樞紐節點的前10好友為
1--徐希文--0.21
2--colipso--0.20
3--劉杉--0.14
4--馬佳--0.12
5--李超--0.11
6--呂秀芳--0.08
7--藏新汀--0.08
8--王大舸--0.08
9--王卉卉--0.06
10--陳欣--0.05
----------2014-06-08 21時49分07秒開始幕后黑手指數分析(基于Eigenvector centrality算法)---------
Not defined for multigraphs.
-------2014-06-08 21時49分07秒開始Google PageRank指數分析(基于Google PageRank算法)-------
pagerank() not defined for graphs with multiedges.
對一些詞解釋下:
樞紐:一個人同時屬于兩個不怎么想干的群體�����,那么這個人就處于樞紐的位置���。
幕后黑手:顧名思義�,一個人不怎么和大部分人聯系�����,只和關鍵人物發生聯系���,通過關鍵人來影響群體�����。
在分析中后兩個算法因為底層數據構造的社交網絡為無向網絡�����,所以在這一個具體分析中不適用��。
2)核心交往圈
扯那么多基本人我不可能都認識���,networkx還提供了分析某人的核心交往圈的算法���,還是以我為例:

---------------2014-06-08 21時20分39秒開始整體分析----------------
社交網總共有502個好友
其他的分析因為是用同一個模塊來實現的����,和上面相同���,就不重復了���。
3)圈里圈外
上面的還只是宏觀層面的結果�,從微觀層面看�����,在大群體中也總是少不了一個一個的小圈子�����,這個圈子里的人關系更為緊密�����,有著共同的話題���,一般對圈子之外的人有一定的排斥性��,而對圈子里的人信任度會很高���,正所謂圈里圈外��。
對于一門發展了將近半個世紀的學科��,還是那句話�,你想到的東西早就有人想到了���。
比如我的好友圈中:
第45個小圈子為:
崔文英 殷渤濤 鄭新玉 孫昊 陳欣 張辰星 陸伯文
這是我的一幫高中同學���。
4)最短路徑
已經有非常成熟的算法來尋找社交網絡中的兩個節點之間的最短路徑���。也就是所謂的六度空間�����。即我如果想認識某某����,那么應該找那些最少的中間人來達到目的�����?
舉一反三一下���,如果是由各種書籍來組成的一個網絡�,書是節點��,一個人如果讀過兩本書���,那么這兩本書就有個連線���。問題來了�����,在各種小說APP上��,如果一個人讀了兩本書��,如何給他推薦第三本書�����?這兩本書最短路徑上的其它書嘛����,有人會問�����,這不是兩本書已經有連線了����,路徑不是最短了嗎���?這就涉及到了路徑的權重問題��,有了權重��,直接的連線就不一定最短咯��。權重如何得到���?Well,It depands.
由于我只抓了兩層好友���,so�����,最短路徑不會超過2.
隨便找一個:colipso ---谷雨--- 范文卓 我想認識范��,那么找谷雨就對了�。
5)三人行
對于任意三個人�����,可以有如下16種關系:
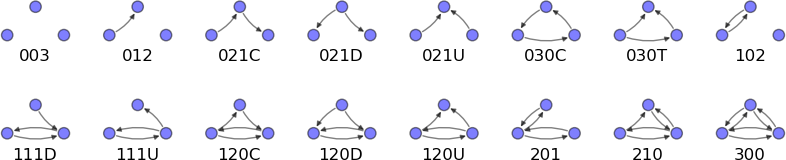
比如對于012C這種類型��,作為中間人���,是不是可以介紹另外兩人認識那��?
看看我的交往圈里面這16種類型各占多少:
201類型的三節點有94109個
021C類型的三節點有0個
021D類型的三節點有0個
210類型的三節點有0個
120U類型的三節點有0個
030C類型的三節點有0個
003類型的三節點有19747819個
300類型的三節點有3605個
012類型的三節點有0個
021U類型的三節點有0個
120D類型的三節點有0個
102類型的三節點有1112967個
111U類型的三節點有0個
030T類型的三節點有0個
120C類型的三節點有0個
111D類型的三節點有0個
當然����,因為我只抓了兩層交往圈�����,可以說還是比較核心的交往圈����,所以很多三節點類型都沒有出現����,如果抓取的層數更多�����,結果會更顯著����。
仍然是舉一反三����,網絡中的節點無論是人還是物���,對于16種結構中的每一種其實都可以制定一定的策略來達到一定的目的�����。上述分析已經完成了行動的第一步�����,識別目標��。
三:亂七八糟的一些想法
1)傳統統計和現代分析
最近同時在研究R和社交網絡分析���,發現傳統統計分析方法和現代分析方法還是有一些差別的�。
傳統統計分析方法起源于19世紀��,無論是點估計/區間估計/假設檢驗都是依賴于一定的分布假設前提���,更不要提貝葉斯統計�����,有大量的學術研究搞定了小樣本下檢驗整體的方法����,目的是想方設法降低計算量���。但問題是現在的環境/用戶偏好變化非?����??,也就是分布變化快�����。用傳統統計方法在分析的群體變化�����,分析的參數變化下還是有一定局限���。
而現代的分析方法無論是蒙特卡洛模擬還是社交網絡分析都是基于密集計算�����,管你什么分布�����,模擬100次不夠�����,那就模擬10000次��,100000次�。根據大數定律��,結果跑也跑出來了�����,八九不離十�。
2)工具
上面的所有分析都是用python 和networkx模塊完成���。Python的靈活數據結構�,大量的開源模塊(numpy/scipy/matplotlib/networkx/webpy等等)可以說是居家旅行����,數據分析的必備良藥����。清晰的語言規范也避免了括號風暴�。我很欣賞���。
networkx分析規模的瓶頸首先在于內存/存儲��,其次在于算法的合理性����。對于10萬以內的節點數還是容易應付的�。如果節點數量級在于千萬甚至億���,那就得好好設計了���。
3)分析價值
分析能產生的價值一種是用于決策/一種用在產品����。決策的對錯在中長期能看到效果�。產品則更直接����,分析價值快速見于用戶數量/意見�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
