業界 | 作畫����、寫詩�、彈曲子����,AI還能這么玩
隨著深度學習的發展�,算法研究已經進入一個新的領域:人工智能生成藝術作品��。除了研究機器人����、語言識別��、圖像識別����、NLP 等等這些����,AI 還能作畫��、寫詩����、彈曲子�。驚不驚喜����,意不意外�����?
隨著深度學習取得的成功�����,算法研究已經進入了另一個人類認為不受自動化技術影響的領域:創造引人入勝的藝術品��。
在過去的幾年中�����,利用人工智能生成的藝術作品取得了很大的進步����,其結果可以在 RobotArt 和英偉達舉辦的 DeepArt 大賽中看到:

雖然這些模型的技術成就令人印象深刻��,但人工智能和機器學習模型能否真的像人一樣具有創造性仍是一個爭論的焦點��。有些人認為�����,在圖像中建立像素的數學模型或者識別歌曲結構中的順序依賴性并非什么真正具有創造性的工作����。在他們看來�,人工智能缺乏人類的感知能力����。但我們也不清楚人類大腦正在做什么更令人印象深刻的事情��。我們怎么知道一個畫家或者音樂家腦海中的藝術火花不是一個通過不斷練習訓練出來的數學模型呢�����?就像神經網絡這樣��。
盡管「人工智能的創造力是否是真正的創造能力�����?」這一問題在短期內還不太可能被解決���,但是研究這些模型的工作原理可以在一定程度上對這個問題的內涵作出解釋��。本文將深入分析幾個通過機器生成的頂尖視覺藝術和音樂作品����。具體而言�,包括風格遷移和音樂建模�,以及作者所認為的該領域未來的發展方向���。
風格遷移
你對風格遷移可能已經很熟悉了��,這可以說是最著名的一種通過人工智能生成的藝術�����。如下圖所示:

這究竟是怎么做到的呢�?我們可以認為每張圖片由兩個部分組成:內容和風格�����?��!竷热荨咕褪菆D片中所展示的客觀事物(如左圖中斯坦福大學的中心廣場)���,「風格」則是圖畫的創作方式(如梵高《星月夜》中的螺旋�����、多彩的風格)���。風格遷移是用另一種風格對一幅圖像進行二次創作的任務�����。
假設我們有圖像
c 和 s���,c 表示我們想要從中獲取內容的圖像����,s 表示我們想要從中獲取風格的圖像��。令 y^ 為最終生成的新圖像����。直觀地說�,我們希望 y^
具有與 c 相同的內容�����、與 s 相同的風格�。從機器學習的角度來看�����,我們可以將這個任務形式化定義為:最小化 y^ 和 c 之間的內容損失以及 y^
和 s 之間的風格損失���。
但是我們該如何得出這些損失函數呢����?也就是說�����,我們如何從數學上接近內容和風格的概念����?Gatys�����,Ecker
和 Bethge 等人在他們具有里程碑意義的風格遷移論文「A Neural Algorithm of Artistic
Style」(https://arxiv.org/abs/1508.06576)中提出���,這個問題的答案在于卷積神經網絡(CNN)的架構�。

假設你通過一個已經被訓練過的用于圖像分類
CNN
來饋送圖像����。由于這樣的初始化訓練����,網絡中的每一個后繼層都被設置來提取比上一層更復雜的圖像特征��。作者發現圖像的內容可以通過網絡中某一層的特征映射來表示�。然后�����,它的風格就可以用特征映射通道之間的相關性來表示����。這種相關性被存在了一個名為「Gram
matrix」的矩陣中�。
基于這種數據表征����,作者將生成圖像的特征映射與內容圖像之間的歐氏距離相加�����,從而構建內容損失���。接下來���,作者將每個風格層特征映射的
Gram
矩陣之間的歐氏距離相加��,從而計算風格損失���。在這兩個損失中��,每一層的重要性都是根據一組參數來加權�����,可以對這些參數進行調優以獲得更好的結果��。
形式上��,令 y^ 為生成的圖像��,并令 ?j(x) 為輸入 x 的 第 j 層特征映射�����。相應的內容損失可以被計算為:

令 Gj(x) 為 ?j(x) 的 Gtam 矩陣�����。相應的風格損失可以用以下形式計算�,其中 F 表示弗羅貝尼烏斯范數(Frobenius norm):
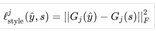
最后����,我們用權重αj 和βj 對所有 L 層求和����,從而得到總的損失函數:
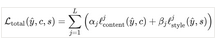
也就是說��,這意味著整個網絡的損失函數
Ltotal 僅僅是內容損失和風格損失的加權組合�。在這里���,α_j 和 β_j
除了用來每一層加權��,還要控制忠實重建目標內容和重建目標風格之間的權衡�。在每一步訓練中���,作者根據損失函數更新輸入的像素���,然后反復進行這種更新操作��,直到輸入圖像收斂到目標風格圖像�。
前饋風格遷移
對于我們想要生成的每張圖像來說���,解決這個優化問題都需要時間�����,因為我們需要從隨機噪聲完美地轉化到具有特定風格的內容��。事實上����,本文的原始算法要花大約兩個小時的時間來制作一張圖像�����,這種情況激發了更快處理的需求�����。幸運的是�����,Jognson
等人(https://arxiv.org/abs/1603.08155)在 2016
年針對該問題發表了一篇后續論文����,該文描述了一種實時進行風格遷移的方法���。
Johnson
等人沒有通過最小化損失函數從頭開始生成圖像����,而是采取了一種前饋方法��,訓練一個神經網絡直接將一種風格應用到指定的圖片上�。他們的模型由兩部分組成——一個圖像轉化網絡和一個損失網絡����。圖像轉化網絡將一個常規圖像作為輸入�����,并且輸出具有特定風格的相同圖像�����。然而����,這個新模型也要使用一個預先訓練好的損失網絡�。損失網絡將測量特征重構損失����,后者是(圖片內容的)特征表示和風格重建損失之間的差異����,而風格重建損失則是通過
Gram 矩陣計算的圖像風格之間的差異�����。
在訓練過程中�,Johnson
等人將微軟「COCO」數據集(http://cocodataset.org/#home)中的一組隨機圖像輸入到圖像轉化網絡中�,并且用不同的風格創作這些圖像(比如《星月夜》)���。這個網絡被訓練用于優化來自于損失網絡的損失函數組合�����。通過這種方法生成的圖片質量與原始圖片質量相當�,而且這種方法生成
500 張大小為 256*256 的圖片時速度比之前快了令人難以置信的 1060 倍�。這個圖像風格遷移的過程需要花費 50 毫秒:

在未來���,風格遷移可以被拓展到其它媒介上�,比如音樂或詩歌�����。例如�,音樂家可以重新構思一首流行歌曲(比如
Ed Sheeran 的「Shape of
You」)����,讓它聽起來有爵士的風格���?�;蛘?���,人們可以將現代的說唱詩轉換成莎士比亞的五步抑揚詩風格���。到目前為止�,我們在這些領域還沒有足夠的數據來訓練出優秀的模型��,但這只是時間問題��。
對音樂建模
生成音樂建模是一個難題�,但是前人已經在這個領域做了大量工作�。
當谷歌的開源人工智能音樂項目「Magenta」剛剛被推出時�����,它只能生成簡單的旋律���。然而���,到了
2017 年夏天��,該項目生成了「Performance RNN」���,這是一種基于 LSTM
的循環神經網絡(RNN)���,可以對復調音樂進行建模��,包括對節拍和力度進行建模�。
一首歌可以被看作一個音符序列���,音樂便是一個使用
RNN 建模的理想用例���,因為 RNN 正是為學習序列化模式而設計的�。我們可以在一組歌曲的數據集合(即一系列代表音符的向量)上訓練
RNN��,接著從訓練好的 RNN 中取樣得到一段旋律�����?���?梢栽凇窶agenta」的 Github 主頁上查看一些演示樣例和預訓練好的模型����。
之前 Magenta 和其他人創作的音樂可以生成可傳遞的單聲道旋律或者時間步的序列��,在每一個時間步上��,最多一個音符可以處于「開啟」狀態�����。這些模型類似于生成文本的語言模型:不同的是�,該模型輸出的不是代表單個詞語的獨熱向量���,而是代表音符的獨熱向量�。
即使使用獨熱向量也意味著一個可能生成旋律的巨大空間�。如果要生成一個由 n 個音符組成的序列——意味著我們在 n 個時間步的每一個時間步上都要生成一個音符——如果我們在每個時間步上有 k 個可以選擇的音符�,那么我們最終就有 k 的 n 次方個有效向量序列��。

這個空間可能相當大�����,而且到目前為止我們的創作僅僅局限于單聲道音樂���,它在每個時間步上只播放一個音符����。而我們聽到的大多數音樂都是復調音樂�����。復調音樂的一個時間步上包含多個音符�����。想象一下一個和弦���,或者甚至是多種樂器同時演奏?����,F在��,有效序列的數量是巨大的——2^(k^n)��。這意味著谷歌的研究人員必須使用一個比用于文本建模的
RNN 更復雜的網絡:與單個詞語不同��,復調音樂中每個時間步上可以有多個音符處于「開啟」狀態���。
還有一個問題�����,如果你曾經聽過電腦播放的音樂——盡管是人類創作的音樂——它仍然可能聽上去像機器人創作的���。這是因為����,當人類演奏音樂時���,我們會改變節奏(速度)或者力度(音量)��,讓我們的表演有情感的深度�。為了避免這種情況��,研究人員不得不教該模型稍稍地改變節奏和力度���?!窹erformance
RNN」可以通過改變速度���、突出某些音符以及更大聲或更柔和地演奏來生成聽起來像人類創作的音樂��。
如何訓練一個能有感情地演奏音樂的模型呢�����?實際上有一個數據集完美適用于這個目標����。雅馬哈電鋼琴比賽數據集包括現場演出的
MIDI
數據:每首歌被記錄為一個音符序列�,每一個音符都包含關于演奏速度(彈奏音符的力度)和時間的信息��。因此��,除了學習要演奏哪些音符��,「Performance
RNN」還利用人類表演的信息去學習如何演奏這些音符���。
最近的這些發展就好比是一個用一根手指彈奏鋼琴的六歲孩子與一個富有感情地演奏更復雜樂曲的鋼琴演奏家之間的區別�����。然而�,還有很多工作要做:「Performance
RNN」生成的一些樣本仍然一聽起來就是人工智能生成的�����,因為它們沒有固定的音調或者像傳統歌曲那樣重復主題或旋律�����。未來的研究可能會探索該模型能夠為鼓或者其他樂器做什么����。
但是就目前的情況而言�����,這些模型已經發展到足以幫助人們創造他們自己的音樂的地步����。
人工智能生成藝術作品的未來
過去幾年中�����,機器學習和藝術的交叉研究迅速發展���。這甚至成為了紐約大學一門課程的主題����。深度學習的興起對這個領域產生了巨大的影響����,重新喚起了人們對表示和學習如圖片��、音樂��、文本等大量非結構化數據的希望��。
我們現在正在探索機器生成藝術作品的可能性����。未來�����,我們可能會看到機器學習成為藝術家的工具�,比如為草圖上色�、「自動完成」圖像��、為詩歌或小說生成大綱等���。
憑借更強的計算能力�,我們可以訓練能夠在諸如音頻�、電影或其它形式復雜的媒介上泛化的模型?�,F在已經有可以根據任何新文本生成相應音頻和口型同步的視頻的模型����。Mor
等人的「musical translation network」能夠在樂器和音樂流派之間進行一種聲音風格遷移��。Luan
等人展示了適用于高分辨率圖像的真實風格遷移�。這種機器生成的媒體文件的潛在應用價值是巨大的�。
我們可以無休止地討論通過人工智能生成的藝術作品是否真正具有創造性����。但或許可以從另一個角度來看待這個問題�����。通過對人類的創造力進行數學化建模的嘗試����,我們開始對人類的藝術作品為何如此具有感染力有了更深刻的理解����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
