用R語言把超大文本文件拆分成幾個小文本文件
近一段時間一直在研究一些醫院的數據��。前兩天遇到一個尷尬:想打開一個僅有3G左右的文本文件(有時候必須要打開���,直接傳到數據庫滿足不了需求)����,破電腦(4G內存的電腦)就是打不開(用的Notepad++)����。就是這造型:
上網搜了一些方法���,下了一些比較不常用的文本處理工具和其它工具���,也不理想���。得知好多人在許多場景都需要打開或者拆分8G甚至10G以上的文本文件�����,于是想著自己研究一下���。下面就是我用R來拆分大文本的過程��,雖然方法比較笨�����,但是簡單輕巧�、思路清晰�。
1.首先把你想要拆分的大文本文件放到R的當前工作目錄下�����。我的文件名在這里叫details.txt�����。
2.用函數split_file()來拆分大文本文件�。
split_file()函數是自定義的一個函數���,用來拆分超大文本文件�����。
它總共有兩個參數filename和eachfile_lines_num�,即split_file(filename����,eachfile_lines_num)���。
filename是指需要拆分的超大文本的名字���,eachfile_lines_num是指拆分完的每一個文件中有多少行數據����。
split_file()會返回一個數值�,代表了總共拆分成的小文本的數量����。
split_file()拆分出來的文件會放置在R當前的工作目錄下����。
使用如:split_file("details.txt",1000000)�����,它把名為details.txt的超大文本文件拆分為每個文件只有1000000行的一個個的小文本文件���。
split_file()的細節:
file_split <- function(filename,eachfile_lines_num){ #建立函數
c <- file(filename,"r") #建立鏈接
varnames <- paste("splitfile", 1:1000, sep = "_") #建立盡可能多但不要太多的動態變量名
i <- 1 #初始值
while(TRUE){
assign(varnames[i],value = readLines(c,n = eachfile_lines_num)) #分別把從filename中讀出來的數據存放在變量中
write.table(get(varnames[i]),paste(varnames[i],".txt",sep = "")) #分別把存放在變量中的數據寫出到文件中
if (length(get(varnames[i])) < eachfile_lines_num) break
else i <- i + 1 #判斷循環停止條件
}
return(i) #返回文件數量
}
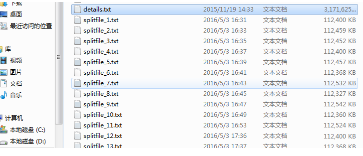
我執行完file_split("details.txt",500000)之后得到了30多個文件:
3.對拆分的文件進行處理����。由于過程中用到了readLines()�,因此拆出來的文件每一行是一個字符串���,有引號���。這好像不符合要求�,只需用Windows記事本或notepad++或其他文本處理應用處理一下就行��。在notepad++中執行“搜索
-> 替換”把雙引號替換成\0就行了��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情����;












 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
