下一個GAN���?OpenAI提出可逆生成模型Glow
目前���,生成對抗網絡
GAN 被認為是在圖像生成等任務上最為有效的方法�,越來越多的學者正朝著這一方向努力:在計算機視覺頂會 CVPR 2018 上甚至有 8%
的論文標題中包含 GAN���。近日來自 OpenAI 的研究科學家 Diederik Kingma 與 Prafulla Dhariwal
卻另辟蹊徑�����,提出了基于流的生成模型 Glow�����。據介紹�����,該模型不同于 GAN 與 VAE�,而在生成圖像任務上也達到了令人驚艷的效果�。
該研究一經發表��,立刻引起了機器學習社區的注意�����,有人對此表示:終于�,我們有了 GAN 以外的優秀生成模型���!
本文將介紹
OpenAI 創造的 Glow�,一種使用可逆 1×1 卷積的可逆生成模型�。它在之前可逆生成模型研究的基礎上(論文:NICE:
Non-linear Independent Components Estimation���、Density estimation using
Real NVP)進一步擴展���,并簡化了架構���。OpenAI
提出的模型可以生成逼真的高分辨率圖像��,支持高效率采樣�����,并能發現用于操作數據屬性的特征����。目前����,OpenAI
已經發布了該模型的代碼�����,并開放了在線可視化工具���,供人們試用��。
論文:Glow: Generative Flow with Invertible 1×1 Convolutions

-
論文鏈接:https://d4mucfpksywv.cloudfront.net/research-covers/glow/paper/glow.pdf
-
項目代碼(TensorFlow):https://github.com/openai/glow
Note:OpenAI 的 Glow 和 PyTorch 內置的機器學習編譯器重名了�����。
摘要:由于可以追蹤確切的對數似然度�、潛在變量推斷�����,以及訓練與合成的可并行性��,基于流的生成模型(Dinh
et al., 2014)在概念上就很吸引人����。在這篇論文中我們提出了 Glow��,這是一種簡單的使用可逆 1x1
卷積的生成流��。使用該方法���,我們展示了在標準基準上的對數似然度的顯著提升�。也許最引人注目的是��,我們展示了僅通過普通的對數似然度目標優化�,生成模型就可以高效地進行逼真圖像的合成以及大尺寸圖像的操作�。




Glow 模型控制人臉圖像屬性以及和其它人臉圖像融合的交互式 demo(讀者可在原網頁進行交互操作��,還可以上傳自己的圖片)�。
研究動機

研究員 Prafulla Dhariwal 和 Durk Kingma 的圖像屬性操作�����。訓練過程中沒有給模型提供屬性標簽���,但它學習了一個潛在空間�,其中的特定方向對應于胡須密度��、年齡����、頭發顏色等屬性的變化���。
生成建模就是觀察數據(比如一組人臉圖片)��,然后學習可生成數據的模型���。學習近似數據生成過程需要學習數據中存在的所有結構�,而且成功的模型應該能夠合成與數據相似的輸出���。精確生成模型應用廣泛���,包括語音合成�����、文本分析與合成�����、半監督學習和基于模型的控制�。研究者提出的技術也能應用于上述任務���。
Glow 是一種可逆生成模型�����,也稱為基于流的生成模型�����,是 NICE 和 RealNVP 技術的擴展��。相比 GAN 和 VAE��,基于流的生成模型迄今為止在研究界受到的關注寥寥無幾����。
基于流的生成模型具有以下優點:
-
準確的潛在變量推理和對數似然估計�。在 VAE 中�,只能推理出對應于數據點的潛在變量的近似值��。GAN 根本沒有編碼器來推理潛在變量���。而在可逆生成變量中��,可以在沒有近似的情況下實現精準推理�。不僅實現了精準推理�,還得以優化數據的準確對數似然度(而不是下界)��。
-
高效的推理與合成����。自回歸模型���,如 PixelCNN��,也是可逆的�,然而從這樣的模型合成難以實現并行化���,并且通常在并行硬件上效率低下�?��;诹鞯纳赡P腿?Glow 和 RealNVP 都能有效實現推理與合成的并行化�。
-
對下游任務有用的潛在空間�����。自回歸模型的隱藏層有未知的邊際分布�����,使其更難執行有效的數據操作����。在 GAN
中����,數據點通常不是在潛在空間中直接被表征的��,因為它們沒有編碼器��,并且可能無法表征完整的數據分布�����。而在可逆生成模型和 VAE
中不會如此�,它們允許多種應用�����,例如數據點之間的插值��,和已有數據點的有目的修改�����。
-
內存存儲的巨大潛力�。在可逆神經網絡中計算梯度需要恒定而不是和深度呈線性關系的內存��,如 RevNet 論文中所述���。
結果
使用該技術�,OpenAI 在標準基準數據集上獲得了優于 RealNVP 的顯著改進�,后者是之前基于流的生成模型的最好結果��。

在不同數據集的測試集上對 RealNVP 模型和 Glow 模型的量化性能評估(bits per dimension)對比結果��。
Glow 模型在包含三萬張高分辨率人臉圖像的數據集上進行訓練后生成的結果示例����。
Glow
模型可以生成逼真的高分辨率圖像�,而且非常高效�。該模型使用一塊 NVIDIA 1080 Ti GPU��,只需大約 130ms 即可生成一張 256 x
256 的圖像�����,研究人員發現從溫度降低的模型中采樣通常會帶來高質量的樣本�����。上圖中的圖像示例就是通過將潛在空間標準差的溫度縮放 0.7
而得到的��。
潛在空間中的插值
研究人員還可以在任意人臉圖像之間插值�����,方法是使用編碼器對兩張圖像進行編碼�,然后從中間點進行采樣�。注意:輸入是任意人臉圖像�����,而不是從模型中采集的樣本��,因此這可以證明該模型支持完整的目標分布��。
在 Prafulla 的人臉圖像和名人面部圖像之間進行插值�����。
潛在空間中的操作
研究人員可以在無需標簽的情況下訓練一個基于流的模型���,然后使用學到的潛在表征進行下游任務���,如處理輸入的屬性��。這些語義屬性可以是頭發的顏色�、圖像的風格��、樂聲的音高����,或者文本句子的情緒��。由于基于流的模型具備一個完美的編碼器����,因此你可以編碼輸入�����,并計算輸入在具備和不具備某屬性時的平均本征向量(latent
vector)��。然后利用兩個本征向量之間的向量方向來處理任意輸入���。
上述過程需要相對較小規模的標注數據�����,可以在模型訓練好之后進行(訓練過程不需要標簽)�。之前利用
GAN 的研究(https://arxiv.org/abs/1606.03657)需要分別訓練編碼器�。使用 VAE
的研究(https://arxiv.org/abs/1804.03599)只能保證解碼器和編碼器可以兼容分布內數據�����。其他方法包括直接學習表示變換的函數���,如
Cycle-GAN�,但是它們需要對每一次變換進行重新訓練��。
使用基于流的模型處理屬性的簡單代碼片段:
# Train flow model on large, unlabelled dataset X
m = train(X_unlabelled)
# Split labelled dataset based on attribute, say blonde hair
X_positive, X_negative = split(X_labelled)
# Obtain average encodings of positive and negative inputs
z_positive = average([m.encode(x)forxinX_positive])
z_negative = average([m.encode(x)forxinX_negative])
# Get manipulation vector by taking difference
z_manipulate = z_positive - z_negative
# Manipulate new x_input along z_manipulate, by a scalar alpha in [-1,1]
z_input = m.encode(x_input)
x_manipulated = m.decode(z_input + alpha * z_manipulate)
該研究的主要貢獻(不同于早期 RealNVP 研究)是添加了可逆 1x1 卷積�����,以及刪除其他組件���,從而整體簡化架構���。
RealNVP 架構包含兩種層的序列:含有棋盤掩碼(checkerboard masking)的層和含有通道掩碼(channel-wise masking)的層����。研究人員移除了含有棋盤掩碼的層以簡化架構�。含有通道掩碼的層執行并重復以下步驟:
1. 通過在通道維度上反轉輸入的順序來置換輸入���。
2. 從特征維的中間向下將輸入分成兩部分:A 和 B�。
3. 將 A 輸入淺層卷積神經網絡����。根據神經網絡的輸出對 B 進行線性變換���。
4. 連接 A 和 B�����。
將這些層連在一起之后����,A 更新 B�,B 更新 A�,然后 A 再更新 B……這種信息的二分流動(bipartite flow)顯然是相當僵硬的�����。研究人員發現��,通過將步驟(1)的反向排列改變為(固定)shuffling 排列�����,模型性能可以得到改善����。
更進一步�����,模型還可以學習最優排列���。學習置換矩陣(permutation
matrix)是一種離散優化���,不適合梯度上升�。但由于置換操作只是具有平方矩陣的線性變換的特例����,因此可以用卷積神經網絡來實現�����,置換通道相當于通道數相等的輸入和輸出的
1x1 卷積運算��。因此�����,研究人員用學習的 1x1 卷積運算替換固定排列�����。1x1
卷積的權重被初始化為一個隨機的旋轉矩陣��。如下圖所示�����,這一運算帶來了模型性能的大幅提升���。研究人員還指出�,通過對權重進行 LU
分解����,可以高效地完成優化目標函數所涉及的計算�。
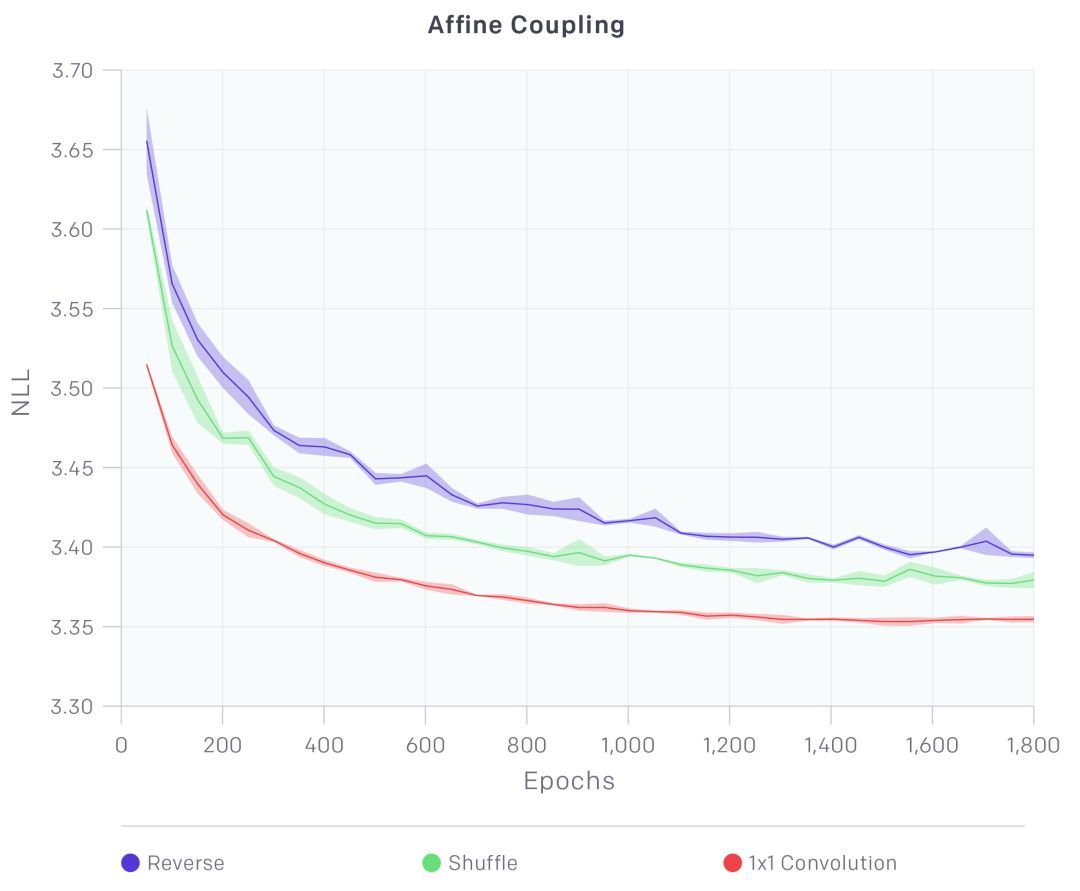
主要貢獻——可逆 1x1 卷積�,極大地改進了模型��。
此外���,研究人員刪除了批歸一化�,用一個激活歸一化層作為替代���。這個層簡單地移動和擴大了激活函數�����,給定數據的初始
minibatch�,該層具備依靠數據的初始化技術可對激活函數進行歸一化操作���。這能把 minibatch 大小縮減到
1(對于較大的圖像)���,把模型大小擴大����。
規模
本文提出的架構結合了各種優化方法�����,例如梯度檢查點���,因此能夠訓練規模更大的基于流的生成模型��。此外�����,研究人員使用
Horovod 在機器集群上訓練模型����。上面 demo 中使用的模型是在有 8 塊 GPU 的 5 臺機器上訓練的�����。使用這個設置�,可以訓練具有 1
億多個參數的模型�。
研究方向
本研究表明�����,訓練基于流的模型來生成真實的高分辨率圖像并非不可能��,而且還能學習隱藏表征�,用于數據處理這樣的下游任務�����。研究人員還為未來的研究提供了幾個方向:
1. 在似然函數上可與其它模型類別相媲美�。自回歸模型和 VAE 在對數似然上表現要比基于流的模型好����,然而����,它們各自有采樣效率低���、推理不精確的缺陷��?�?梢詫⒒诹鞯哪P?�、VAE 以及自回歸模型三者相結合來權衡其長處����。這會是一個有趣的研究方向��。
2.
改進架構���,從而提高計算與參數效率�。為了生成真實的高分辨率圖像�����,人臉生成模型使用了大約 2 億個參數�、600
個卷積層�,因此訓練成本極高��。而較淺的模型在學習長期依存關系時表現會變差���。使用自注意架構����,或者用更進步的訓練方法作為更好的解決方案能夠讓訓練流模型更廉價����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
