Spark一種快速數據分析替代方案
Spark 是一種與 Hadoop 相似的開源集群計算環境���,但是兩者之間還存在一些不同之處����,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越���,換句話說���,Spark 啟用了內存分布數據集�����,除了能夠提供交互式查詢外���,它還可以優化迭代工作負載����。
Spark 是在 Scala 語言中實現的�����,它將 Scala 用作其應用程序框架����。與 Hadoop 不同�����,Spark 和 Scala 能夠緊密集成�,其中的 Scala 可以像操作本地集合對象一樣輕松地操作分布式數據集�����。
盡管創建 Spark 是為了支持分布式數據集上的迭代作業���,但是實際上它是對 Hadoop 的補充���,可以在 Hadoo 文件系統中并行運行���。通過名為 Mesos 的第三方集群框架可以支持此行為�����。Spark 由加州大學伯克利分校 AMP 實驗室 (Algorithms, Machines, and People Lab) 開發�����,可用來構建大型的�、低延遲的數據分析應用程序���。
Spark 集群計算架構
雖然 Spark 與 Hadoop 有相似之處��,但它提供了具有有用差異的一個新的集群計算框架��。首先��,Spark 是為集群計算中的特定類型的工作負載而設計�,即那些在并行操作之間重用工作數據集(比如機器學習算法)的工作負載����。為了優化這些類型的工作負載���,Spark 引進了內存集群計算的概念��,可在內存集群計算中將數據集緩存在內存中���,以縮短訪問延遲���。
Spark 還引進了名為 彈性分布式數據集 (RDD) 的抽象�����。RDD 是分布在一組節點中的只讀對象集合�����。這些集合是彈性的�����,如果數據集一部分丟失���,則可以對它們進行重建�����。重建部分數據集的過程依賴于容錯機制���,該機制可以維護 “血統”(即充許基于數據衍生過程重建部分數據集的信息)����。RDD 被表示為一個 Scala 對象�,并且可以從文件中創建它��;一個并行化的切片(遍布于節點之間)�;另一個 RDD 的轉換形式��;并且最終會徹底改變現有 RDD 的持久性�����,比如請求緩存在內存中���。
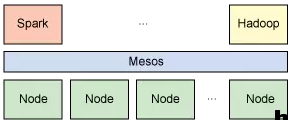
Spark 中的應用程序稱為驅動程序�,這些驅動程序可實現在單一節點上執行的操作或在一組節點上并行執行的操作����。與 Hadoop 類似��,Spark 支持單節點集群或多節點集群���。對于多節點操作��,Spark 依賴于 Mesos 集群管理器����。Mesos 為分布式應用程序的資源共享和隔離提供了一個有效平臺(參見 圖 1)���。該設置充許 Spark 與 Hadoop 共存于節點的一個共享池中���。
圖 1. Spark 依賴于 Mesos 集群管理器實現資源共享和隔離�。
Spark 編程模式
驅動程序可以在數據集上執行兩種類型的操作:動作和轉換�����。動作 會在數據集上執行一個計算����,并向驅動程序返回一個值��;而轉換 會從現有數據集中創建一個新的數據集�����。動作的示例包括執行一個 Reduce 操作(使用函數)以及在數據集上進行迭代(在每個元素上運行一個函數���,類似于 Map 操作)�����。轉換示例包括 Map 操作和 Cache 操作(它請求新的數據集存儲在內存中)��。
我們隨后就會看看這兩個操作的示例��,但是��,讓我們先來了解一下 Scala 語言�。
Scala 簡介
Scala 可能是 Internet 上不為人知的秘密之一���。您可以在一些最繁忙的 Internet 網站(如 Twitter��、LinkedIn 和 Foursquare���,Foursquare 使用了名為 Lift 的 Web 應用程序框架)的制作過程中看到 Scala 的身影�����。還有證據表明��,許多金融機構已開始關注 Scala 的性能(比如 EDF Trading 公司將 Scala 用于衍生產品定價)����。
Scala 是一種多范式語言�,它以一種流暢的����、讓人感到舒服的方法支持與命令式�、函數式和面向對象的語言相關的語言特性�����。從面向對象的角度來看���,Scala 中的每個值都是一個對象����。同樣�����,從函數觀點來看���,每個函數都是一個值�����。Scala 也是屬于靜態類型�,它有一個既有表現力又很安全的類型系統�。
此外��,Scala 是一種虛擬機 (VM) 語言����,并且可以通過 Scala 編譯器生成的字節碼�,直接運行在使用 Java Runtime Environment V2 的 Java? Virtual Machine (JVM) 上����。該設置充許 Scala 運行在運行 JVM 的任何地方(要求一個額外的 Scala 運行時庫)����。它還充許 Scala 利用大量現存的 Java 庫以及現有的 Java 代碼����。
最后�,Scala 具有可擴展性�����。該語言(它實際上代表了可擴展語言)被定義為可直接集成到語言中的簡單擴展��。
Scala 的起源
Scala 語言由 Ecole Polytechnique Federale de Lausanne(瑞士洛桑市的兩所瑞士聯邦理工學院之一)開發���。它是 Martin Odersky 在開發了名為 Funnel 的編程語言之后設計的�����,Funnel 集成了函數編程和 Petri net 中的創意��。在 2011 年�,Scala 設計團隊從歐洲研究委員會 (European Research Council) 那里獲得了 5 年的研究經費�,然后他們成立新公司 Typesafe��,從商業上支持 Scala�,接收籌款開始相應的運作�����。
舉例說明 Scala
讓我們來看一些實際的 Scala 語言示例���。Scala 提供自身的解釋器�����,充許您以交互方式試用該語言����。Scala 的有用處理已超出本文所涉及的范圍���,但是您可以在 參考資料 中找到更多相關信息的鏈接�。
清單 1 通過 Scala 自身提供的解釋器開始了快速了解 Scala 語言之旅��。啟用 Scala 后����,系統會給出提示���,通過該提示�����,您可以以交互方式評估表達式和程序���。我們首先創建了兩個變量���,一個是不可變變量(即 vals���,稱作單賦值)���,另一個變量是可變變量 (vars)�����。注意�����,當您試圖更改 b(您的 var)時�����,您可以成功地執行此操作�,但是��,當您試圖更改 val 時�����,則會返回一個錯誤�����。
清單 1. Scala 中的簡單變量
$ scalaWelcome to Scala version 2.8.1.final (OpenJDK Client VM, Java 1.6.0_20).
Type in expressions to have them evaluated.
Type :help for more information.
scala> val a = 1a: Int = 1
scala> var b = 2b: Int = 2
scala> b = b + ab: Int = 3
scala> a = 26: error: reassignment to val
a = 2
^
接下來�,創建一個簡單的方法來計算和返回 Int 的平方值���。在 Scala 中定義一個方法得先從def 開始����,后跟方法名稱和參數列表���,然后���,要將它設置為語句的數量(在本示例中為 1)��。無需指定任何返回值����,因為可以從方法本身推斷出該值��。注意���,這類似于為變量賦值��。在一個名為 3的對象和一個名為 res0 的結果變量(Scala 解釋器會自動為您創建該變量)上�,我演示了這個過程�����。這些都顯示在 清單 2 中�。
清單 2. Scala 中的一個簡單方法
scala> def square(x: Int) = x*xsquare: (x: Int)Int
scala> square(3)res0: Int = 9
scala> square(res0)res1: Int = 81
接下來�,讓我們看一下 Scala 中的一個簡單類的構建過程(參見 清單 3)�����。定義一個簡單的Dog 類來接收一個 String 參數(您的名稱構造函數)�。注意���,這里的類直接采用了該參數(無需在類的正文中定義類參數)�����。還有一個定義該參數的方法����,可在調用參數時發送一個字符串�����。您要創建一個新的類實例��,然后調用您的方法��。注意��,解釋器會插入一些豎線:它們不屬于代碼�����。
清單 3. Scala 中的一個簡單的類
scala> class Dog( name: String ) {
| def bark() = println(name + " barked")
| }defined class Dog
scala> val stubby = new Dog("Stubby")stubby: Dog = Dog@1dd5a3d
scala> stubby.barkStubby barked
scala>
完成上述操作后�����,只需輸入 :quit 即可退出 Scala 解釋器����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
