R語言基本數據分析
本文基于R語言進行基本數據統計分析��,包括基本作圖���,線性擬合��,邏輯回歸����,bootstrap采樣和Anova方差分析的實現及應用���。
不多說��,直接上代碼�����,代碼中有注釋��。
1. 基本作圖(盒圖���,qq圖)
#basic plot
boxplot(x)
qqplot(x,y)
2. 線性擬合
#linear regression
n = 10
x1 = rnorm(n)#variable 1
x2 = rnorm(n)#variable 2
y = rnorm(n)*3
mod = lm(y~x1+x2)
model.matrix(mod) #erect the matrix of mod
plot(mod) #plot residual and fitted of the solution, Q-Q plot and cook distance
summary(mod) #get the statistic information of the model
hatvalues(mod) #very important, for abnormal sample detection
3. 邏輯回歸
#logistic regression
x <- c(0, 1, 2, 3, 4, 5)
y <- c(0, 9, 21, 47, 60, 63) # the number of successes
n <- 70 #the number of trails
z <- n - y #the number of failures
b <- cbind(y, z) # column bind
fitx <- glm(b~x,family = binomial) # a particular type of generalized linear model
print(fitx)
plot(x,y,xlim=c(0,5),ylim=c(0,65)) #plot the points (x,y)
beta0 <- fitx$coef[1]
beta1 <- fitx$coef[2]
fn <- function(x) n*exp(beta0+beta1*x)/(1+exp(beta0+beta1*x))
par(new=T)
curve(fn,0,5,ylim=c(0,60)) # plot the logistic regression curve
3. Bootstrap采樣
# bootstrap
# Application: 隨機采樣�����,獲取最大eigenvalue占所有eigenvalue和之比�,并畫圖顯示distribution
dat = matrix(rnorm(100*5),100,5)
no.samples = 200 #sample 200 times
# theta = matrix(rep(0,no.samples*5),no.samples,5)
theta =rep(0,no.samples*5);
for (i in 1:no.samples)
{
j = sample(1:100,100,replace = TRUE)#get 100 samples each time
datrnd = dat[j,]; #select one row each time
lambda = princomp(datrnd)$sdev^2; #get eigenvalues
# theta[i,] = lambda;
theta[i] = lambda[1]/sum(lambda); #plot the ratio of the biggest eigenvalue
}
# hist(theta[1,]) #plot the histogram of the first(biggest) eigenvalue
hist(theta); #plot the percentage distribution of the biggest eigenvalue
sd(theta)#standard deviation of theta
#上面注釋掉的語句�,可以全部去掉注釋并將其下一條語句注釋掉��,完成畫最大eigenvalue分布的功能
4. ANOVA方差分析
#Application:判斷一個自變量是否有影響 (假設我們喂3種維他命給3頭豬��,想看喂維他命有沒有用)
#
y = rnorm(9); #weight gain by pig(Yij, i is the treatment, j is the pig_id), 一般由用戶自行輸入
#y = matrix(c(1,10,1,2,10,2,1,9,1),9,1)
Treatment <- factor(c(1,2,3,1,2,3,1,2,3)) #each {1,2,3} is a group
mod = lm(y~Treatment) #linear regression
print(anova(mod))
#解釋:Df(degree of freedom)
#Sum Sq: deviance (within groups, and residuals) 總偏差和
# Mean Sq: variance (within groups, and residuals) 平均方差和
# compare the contribution given by Treatment and Residual
#F value: Mean Sq(Treatment)/Mean Sq(Residuals)
#Pr(>F): p-value. 根據p-value決定是否接受Hypothesis H0:多個樣本總體均數相等(檢驗水準為0.05)
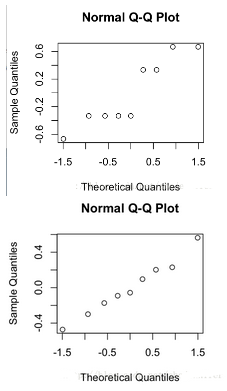
qqnorm(mod$residual) #plot the residual approximated by mod
#如果qqnorm of residual像一條直線����,說明residual符合正態分布���,也就是說Treatment帶來的contribution很小�����,也就是說Treatment無法帶來收益(多喂維他命少喂維他命沒區別)
如下面兩圖分別是
(左)用 y = matrix(c(1,10,1,2,10,2,1,9,1),9,1)和
(右)y = rnorm(9);
的結果���?��?梢娙绻o定豬吃維他命2后體重特別突出的數據結果后���,qq圖種residual不在是一條直線�����,換句話說residual不再符合正態分布�,i.e., 維他命對豬的體重有影響�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
