一小時領會SVM支持向量機
在機器學習領域�,SVM支持向量機作為殺手級武器���,對于分類問題是一招鮮——吃遍天��!它強大的通用技能對于很多偷懶的工程師都是一大福音��,所謂是兵來將擋���,更有甚者����,來了問題用SVM上�,沒有問題也要創造問題讓SVM上��,開玩笑啦�����。所以�����,童鞋們都知道了SVM的重要性���,紛紛投向其大本營�,于是看到了一大堆公式的推導����,懵X……
寫這篇文章的目的就是為了幫助找不到簡單易理解的學習資料的童鞋�,請你一致向這看齊�����。
等等��,想要熟讀本文����,你們還得需要基礎的高數���、線性代數��、統計學習知識����,什么��?都沒有�?學了都忘了�����?基本沒關系�,因為到時候遇到關鍵詞的時候��,我會具體指出哪些需要你們花三分鐘百度一下的����,好了����,又說了這么多���,這一次����,我們真的要開始了����!
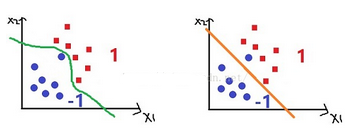
先簡單解釋一下支持向量機的作用����。這是一個二分類分類器����,所謂分類分類�,就是把你輸入的樣本扔到該待的陣營里��。好����,舉個例子�,最簡單是二維的��,我們現在假設有n個(X1�,X2)樣本�,對應的陣營有兩個類別�����,分別是1和-1�����。那么我現在給你一個(X1��,X2)樣本�,你告訴我它是屬于1的還是屬于-1的����。說得有點抽象���,來畫個圖���,假如我給你一個方塊�����,你是覺得它是屬于1還是-1�,由圖可見��,它是屬于1了�����。
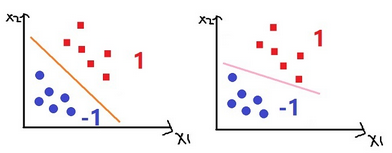
作用我們說完了���,接下來我們開始聊原理��。上面的圖片告訴我們什么了�?我們看到���,有兩個一模一樣的坐標圖����,方塊和圓圈的分界很明顯��,所以你要是給我一個方塊我毫不猶豫就把它扔進-1的區域���。那么問題來了�����,我大概知道1區域在哪里��,但是具體的邊界位置在哪里����?我們看到第一個坐標軸和第二個坐標軸劃分的區域是不一樣的�����,第一個區域劃分得比較勻稱����,而第二個區域劃分得有點勉強����,為什么會有這種感覺����?第一個劃分線距離每一個點都是有些距離的�����,而第二個劃分線距離其中有些點過于近了��,這是我們直觀的判斷感覺����。
對于支持向量機��,它是怎么判斷這個線劃分得好不好�?接下來這句話非常重要:我們找的這條線�,能夠讓所有點中離它最近的點�����,具有最大間距���。
我們分析一下這句話��,我們找的這條線���,判斷它好不好�����,不靠所有的點����,而是靠離它最近的一個點��,僅靠這一個點到直線的距離��,來直接判斷這條線好不好�����。
那我們就開始找這條線��,根據眾多的樣本(X1,X2)�,我們設這個直線為wTx+b=0
( wTx=w1x1+w2x2+w3x3+……+wnxn����,這里只有二元��,所以這里的wTx=w1x1+w2x2)���。
wTx看不懂�?這里就要開始用到線性代數知識了��,熟悉的直接掠過這段話��,這里可以百度矩陣的知識����。簡單解釋下���,假設有一條直線y=kx+b���,這是一元的�。如果是多元的�����,比如三元一次函數y=k1x1+k2x2+k3x3+b����,這個時候我們就可以用矩陣K=[k1,k2,k3]來代表�,那么這個函數就變成了y=KTx�,上標T代表矩陣的轉置���,這里你們需要百度矩陣的乘法����。

我們看到了圖中的這條直線wTx+b=0�,其實對于數學稍微敏感點的童鞋已經知道怎么利用公式判斷點屬于哪個陣營的了�,看圖中方塊都在wTx+b=1直線以上�,說明如果wTx+b>=1的一定是方塊���,同理�,如果wTx+b<=-1的一定是圓圈�����,重點來了��,在這里我介紹一個函數��,它就是SVM最基礎的決策函數:f(x)=sgn(wTx+b)���,sgn()是一個函數��,遇到小于等于-1的值會返回-1�����,遇到大于等于1的值返回1����,所以最終f(x)的值是1或者-1���,所以我們要把wTx+b=0解出來���,再次明確一下我們現在的目標�����,求w和b的值��。
wTx+b=0的前后還有兩條平行線����,仔細觀察�,這兩條線都與各自區域內最外邊的點是重合關系�����,這里說得直白一點�,其實wTx+b=0是由它前后兩條線推出來的�����,因為它正處于前后兩條線的正中間���。要打戰了�,我們把那兩條線都當作是雙方的戰壕����,把每個點都當作要打戰的士兵�����,士兵打完戰回戰壕休整�,這個時候當然我方戰壕離敵方戰壕越遠越好�,士兵有安全感嘛�����,而士兵太累活動不了���,他們的位置就是不變的��,在這種情況下怎么才能把雙方的戰壕隔得最遠�����?這里先求兩個直線的距離���,這里假設第一條直線是w1x1+w2x2=1��,第二條直線是w1x1+w2x2=-1�����,根據高中的數學知識��,我們求得它們的距離d=2/ sqrt(W12+w22)�����,用矩陣表示就是2/||w||,問題轉化為求2/||w||的最大值��。這兩條線向后退��,退到什么時候距離才是最大的��?那就是剛好貼在最前面的士兵���,不能再后退了��,不然前面的士兵就沒東西擋著了�����,這個時候�����,我們想起前面一句話�����,我們找的這條線�,能夠讓所有點中離它最近的點�,具有最大間距 �,這個最前面的士兵就是離中線最近的點�,所以這個時候這兩條直線的距離間接幫助我們解決了找中間這條線的問題�����。
開始簡化問題���,目前我們手中有一個目標函數�,2/||w||�,求它的最小值���,把它轉化一下�����,就是求1/2*||w||2的最大值�����,這個可以理解���。直接求肯定是求不出來的����,看看有沒有其他條件����,我們知道方塊的屬性是y=1��,而它的wTx+b>=1���,圓圈的屬性是y=-1����,而它的wTx+b<=1���。所以yi(wTx+b)>=1�����,我們稱它為約束條件�。

這個時候我們引入拉格朗日乘子法���,其簡單解釋如下圖����,即把目標函數和約束條件以一定形式結合到一個函數中�����,再求解�,具體解釋百度拉格朗日乘子法����。
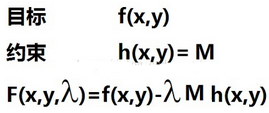
由拉格朗日乘子法轉換得到
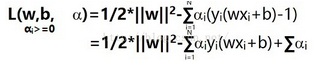
現在把原函數轉化成了現在這個L函數�����,由于轉化為對偶問題(這里不懂直接百度拉格朗日對偶問題)��,原來求的最小值�����,變成了求L的最大值���,不過L也是有約束條件的��,不然它就變成無窮大了�,這個約束條件還是那個yi(wTx+b)>=1��。梳理一下思路�,現在有三個變量���,分別是w���,b�����,a����,那么L函數最大是什么時候�,就是減號后面為0(因為它不能為負數�����,不然不滿足導入拉格朗日乘子法這個目的)�,所以L函數最大的時候還是1/2*||w||2�,問題又來了���,我們本來不就是要求1/2*||w||2的最小值嗎����?所以現在的情況變成了這樣
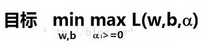
把它轉化一下
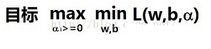
有時候數學就是這么奇妙�����,我們的腦筋還沒轉過彎�����,它就幫我們不知不覺解決了問題�,想起一位老師的話:微妙的數學思維蘊含著宇宙的真理�����,我們不知道為什么這樣能解出來��,可它就是解出來了���,就像宇宙中的種種巧合�����,突然就蹦了出來�,當然這是眾多資深的數學家前輩們窮其一生的精華��,值得我們去尊仰��。又不知道說到哪里去了���,現在我們目標就明確了一點�����,求解L函數關于w和b的最小值�,你想到什么���?沒錯��,簡單的一階偏微分就夠了��,這個時候w��,b的梯度都為0���,它們在這里都達到極值��。
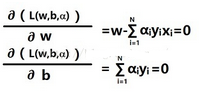
將第一個函數代入L函數�����,得到
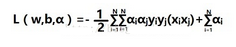
現在得到了一個新函數��,是不是有些陌生���,其實這些都是w和b的化身而已�����,α現在取代了w和b的位置�����,這樣看起來求解確實是方便了許多�����。你們有沒有發現之前的約束條件已經用掉了����,現在需要去尋找新的約束條件去求解��,眼皮底下只有一個條件可以用����,那就是L函數關于b的偏微分所得到的結果�����。約束條件找到了����,現在把目標函數轉化一下�����,求L函數的最大值���,就是求-L的最小值�����,重新梳理一下���,再次明確我們的目標�����,通過求α的值來求w和b的值�����。
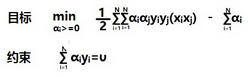
這里我們先打住�����,因為有比求解α更為重要的事情?��,F在既然能用α來表示w和b了����,自然也可以用α來表示分類決策函數��。
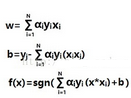
圖中的b是由y=wTx+b得到的��,就這樣我們得到了關于α的分類決策函數�����,其中x是輸入測試的樣本�����。
接下來我們來考慮另一個非常重要的問題���,如果樣本分布邊界并不是很明顯怎么辦?
打戰的時候���,有些士兵還沒來得及返回自己的戰壕����,雙方就歇下了�����,那他只能就近找個地方隱蔽自己����,可能這個地方還在敵人的腹地中��,那修戰壕肯定不可能把這個戰友考慮進去��,不然就修到敵人的地盤去了����。所以第一種劃分的方法是不理智的�����,這個時候劃分邊界就要選擇性忽視偏差較大的樣本點����,可能那個樣本是收集數據的噪點�,也可以從統計學來說���,它距離均值太遠����,沒啥參考意義����。問題又來了����,怎么忽略�����?在機器學習中��,我們稱其軟間隔最大化�,說得俗點����,我們允許這樣偏離較大的樣本出現����,并且在目標函數中增加一個懲罰項降低這些樣本的權重(這是土理解�,反正差不多這個意思)����。
于是我們的目標函數和約束條件變成了這樣
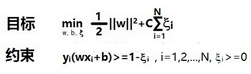
有人說了�,這個公式看不懂���,C和x是什么���?這里的C稱為懲罰系數�,一般由具體的問題所決定����,C大的話對目標函數影響越大�,懲罰效果就越強����,雙方的戰壕就越近���,x是什么����?看圖
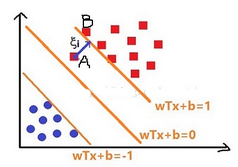
對于點A和點B來說���,假如點B代入公式y=wTx+b����,則是wTx+b=1���。而點A代入公式則是wTx+b+xi=1�����,即wTx+b=1-xi�,所以約束條件變成了yi(wxi+b)>=1-x���。其實引入這個懲罰項主要有兩個目的��,第一使1/2*||w||2盡量小��,第二使偏離點(誤分類點)的個數盡量小(這個就是拉近雙方戰壕的距離�����,讓那些偏離點看起來不那么偏離)�,而C是調和二者的關系的作用����。
現在有了新的目標函數�����,那就從新開始求解�����。這里省略了與上面類似的求解過程��,直接看最后的目標函數和約束條件���。
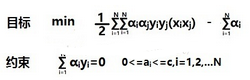
我們發現與上面的約束條件很相似����,但是多了一個條件:0<=ai<=C�。
最重要的時候來了�����,要開始求解α�����,真相的大門馬上就要打開了��。這里我們用的是序列最小最優化算法�����,簡稱SMO���。
先看上圖中的約束條件�,發現每一個aiyi都是互相關聯的��,它們所有的和等于0�。這里作一個假設���,假設這里的α是類似于w的系數(事實上α是與w有直接關系的�,這個假設還是靠譜的)�����,那好�����,我們就當它是系數好了�����。眼前有無數個α等著我們去解出來����,怎么解�����?這么多的α���,那就一個一個解�����,直到滿足KKT條件為止(KKT條件后面會說明)��。由于這些系數都是互相關聯的����,不是相對獨立的���,于是有了這么一個關系�。
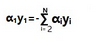
用其它的α可以表示出α1��,如果想凍住其他α而只對α1進行求導取極值是不現實的�,這就變成了牽一發而動全身了�����,而我們并不想動全身����,只想一個一個去求解���,有沒有辦法���?肯定有�����,再看一眼上圖的公式��,再給它變化一下
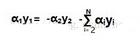
這時可以直接凍住其他α了���,由α1和α2保持平衡���,可是這時候有兩個變量����,求解又不那么樂觀了�����,聰明的你已經有新想法了�����,用α2和其他α表示α1直接代入目標方程�����,再求導求解���,α2的值就這么的出來了�,是不是很簡單����,再把α2的值代入上面的公式��,α1的值也出來���,這一對的值就求解完畢了���,這就是大名鼎鼎的SMO算法�����,由偉大的platt于1988年提出���。
現在我們來解決一下KKT的問題�,KKT是拉格朗日乘子法衍生的條件�,簡單說一般情況下涉及到對偶問題����,或者相關的轉化問題�����,會有一個KKT條件作為支撐約束��,具體的推導過程可以參考鏈接1��。KKT條件如下
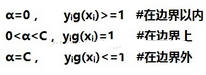
解釋一下上圖的條件��,當α=0時��,可見這個xi對邊界時沒有意義的����,它一直處于遠離邊界的自己的地盤中����。當0<α<C的時候����,則ξi=0����,這個時候xi作為支持向量(剛好在戰壕線上的點)在邊界(戰壕)上��。當α=C時�,0<ξ<1����,xi在邊界(戰壕)和分隔平面(分割線)的中間�,ξ=1時�,xi在分隔平面上��,ξ>1時��,xi在分隔平面外(過了分割線�����,已經是對方的地盤了)�,
解題思路有了��,接下來��,就要開始動手了�。因為α1和α2并行作戰����,所以它們的取值范圍不僅僅是[0,C]這么簡單了��。這里可以寫個目標函數明確下求值目的��。

圖中的Kij看作是(xi,xj)?���,F在看約束條件����,α1和α2有著很明顯的比例關系����,當y1不等于y2的時候���,α1和α2成正比����。當y1等于y2的時候���,α1和α2成反比����。α1和α2各自的取值范圍都是[0,C]���,加上這個條件后�����,取值范圍就開始變化了��。是怎么變化呢����?
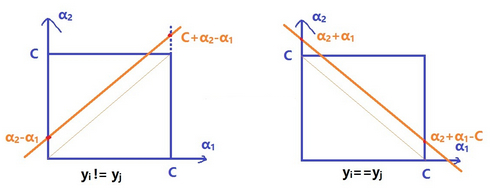
首先���,要明白一件事�,α2必然要滿足[L,H]的約束條件���,L和H的具體值是什么��?
看上左圖����,當y1不等于y2的時候�,這條直線的左交縱坐標是α2-α1����,右交縱坐標是α2-α1+C����,而α的最大值是C��,所以這里的α2取值應該是[α2-α1�����,C],我們找一個規律滿足圖中直線的取值��,它就是這樣
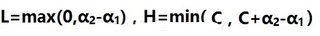
同理�����,當y1等于y2的時候�,L和H的取值規律是這樣的
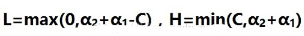
取值范圍出來了��,輔助條件一個一個清晰明了����,接下來最重要的一步大棋馬上就要開盤�。找α1和α2開戰����,準確地說��,是找αi和αj���,因為是通過無數對的
αi和αj迭代計算才能最終出來我們想要的結果�����。
αi怎么找��?在這里我們用愚笨一點的方法����,因為優化重點在αj上���。首先全局遍歷αi�,在αi的基礎上用最長步長法找αj��,什么是最長步長法����?舉個栗子�����,我們從大城市出發����,到達一個小鄉村�,沒有直達的方法��,怎么選擇交通工具���?你可以做大客車轉大客車轉中巴車轉小巴車轉牛車����,你也可以坐火車轉
中巴車轉牛車�,你也可以做飛機轉中巴車轉牛車�����,在不在乎錢的情況下����,哪個最快���?毫無疑問啊��,坐飛機效果太明顯�,加上轉車��,可能全部加起來也就幾個小時�,而國內長途火車和大客車都是起步價十幾個小時的����,這差了一個數量級���,結論是坐飛機最快��。找αj也一樣����,我們要找最明顯的那個αj��,一旦
修正了αj��,就會讓結果看上去改變非常大���,這個落實到具體問題上��,就是錯誤率和αi差的最遠的那個�。這里要說明下一個小細節���,顯然找αj的過程涉及到了對比的過程�,我們要建立一個全局變量用于儲存這個錯誤率的差值�,這樣才能找出最大的來尋找αj���。
條件全部都找齊了��,接下來就是套用公式求值了�����。
首先要知道錯誤率怎么求�,簡單點就是當前樣本的決策分類值與它的標簽值的差(這里是試驗集�,所以是有標簽的)
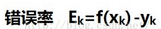
接下來求i與j的相似系數η
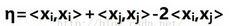
括號內是矩陣內積的運算����,這里可以百度矩陣內積����。求這個相似系數是為接下來的求αj的公式做鋪墊��。

αj由目標函數對αi求導解出�����,然后用αj求αi�����。

我們看KKT條件�,當0<α<C�����,也就是當樣本在邊界上的時候��,yg(x)=1,這個時候可以直接求解b的值�,也就是b1和b2���。假如樣本不再邊界上���,就取平均值
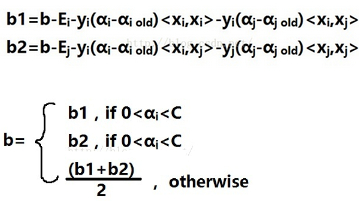
整體思路就到這里結束了��,這是一個超級入門超級入門超級入門的教程���,沒有任何正統借鑒意義���,給看不懂其他參考文獻的童鞋一個簡單粗暴的解釋����,如果想要深入地研究學習SVM���,還需要投入更多的時間去積累和領悟�,網上有很多大神的博客都寫得很好這里就不列舉了����,相信讀到這里你差不多花了一個小時��,SVM是一個很有意思的算法�����,如果你仍保持很大的學習興趣�,那就繼續耕耘吧��,到這里才走了僅僅一小步哦�����!
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
