AI 是萬能的嗎��?當前 AI 仍面臨的難題是什么
談到人工智能(特別是計算機視覺領域)�����,大家關注的都是這一領域不斷取得的進步�,然而人工智能到底發展到什么程度了���?AI
已經成為萬能的了嗎�?Heuritech 的 CTO Charles Ollion
希望通過他的文章可以揭露一些當前的真實情況����。接下來就讓我們一起看看這位作者都談了什么內容吧���!

作者基于 Xkcd 的漫畫改編
最近���,我讀了
Pete Warden
的一篇文章�,這篇文章介紹了一種可以辨別植物疾病的分類器�����。在辨別病害類型方面�����,這個分類器的精確度要比人類肉眼辨別的精確度高的多���。但是�����,這個分類器在面對一張隨機不含有植物的圖片時會給出一個非常驚人的錯誤結果(如下圖所示:左圖展現了分類器在真實植物上檢測病害類型的良好效果�����;而右圖����,在指向計算機鍵盤時��,一張隨機的非植物圖片��,分類器仍會認為這是一種受損的作物)�����。然而這個錯誤���,卻不會發生在人類身上���。
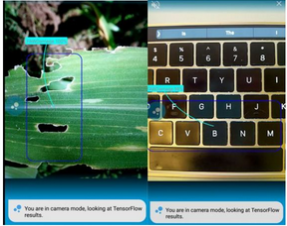
(來源:Pete Warden's blog —— What Image Classifiers Can Do About Unknown Objects)
上面的舉例說明�,計算機視覺系統的能力仍有別于人類的智力��,下面我想通過一道測試題來進一步證明這一觀點:
你知道當前人工智能系統最擅長做什么嗎�?
下面有五個不同的計算機視覺問題����,通過給出的輸入與得到的輸出結果�,試著猜一下哪類問題是計算機視覺系統最容易解決的��?哪類問題是非常困難的��?
▌1.檢測糖尿病性視網膜病變
輸入:有約束的視網膜圖片
輸出:5個類別(健康型以及處于不同階段與形式的病變狀態)
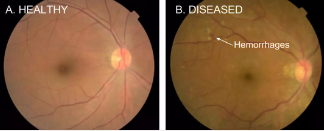
糖尿病性視網膜病變����,一種影響到眼睛的糖尿病并發癥
來源:https://ai.googleblog.com/2016/11/deep-learning-for-detection-of-diabetic.html
▌2.攝像頭手勢識別
輸入:由攝像頭拍攝的一系列短視頻
輸出:25種動作中可能性最大的一種
(注:TwentyBN 現已發布了更豐富的數據集)
來源:TwentyBN
來源:https://medium.com/twentybn/building-a-gesture-recognition-system-using-deep-learning-video-d24f13053a1
▌3.識別 Instagram 圖片里的手提包
輸入:Instagram 上的圖片
輸出:圈出圖片里的手提包

▌4.識別行人
輸入:由固定攝像機拍攝的圖片
輸出:圈出圖中所有的行人

▌5.機器人抓取物體
輸入:由固定攝像機拍攝的兩張圖
輸出:機器人控制策略

左圖為待抓取的物體�����,機器人上裝有一臺固定攝像機來學習如何抓取物體
來源:https://ai.googleblog.com/2017/10/closing-simulation-to-reality-gap-for.html
然而真相是�?
▌糖尿病性視網膜病變:這類識別器是容易實現的����,因為輸入和輸出都是有約束的(谷歌在他們的報道中聲明已經實現并有良好表現了)�。但當把這一系統投入到實際應用時��,困難出現了�。用戶的體驗以及系統與醫生的配合是關鍵問題���,因為對不同類型結果的判定可能會有失偏頗���。
▌攝像頭手勢識別:這個問題相對來說很好定義����,但多變性增加了它的難度:這些由攝像頭拍攝的視頻中��,人們的距離不同���,手勢持續時間不同����,等等... 此外��,在對視頻資料進行分析訓練時�����,隨之產生的還有諸多的工程問題����。不得不說這個問題是非常困難的�����,但已經得到了解決��。
▌識別 Instagram 圖片里的手提包:這個問題看起來似乎很容易解決��,但輸入的圖片是沒有約束的��,而且類別的定義也非常廣(手提包有很多種形態��,沒有一個明確的視覺模式�,因此很有可能被識別成很多其它物體)���。這使得問題變的非常困難����,看看下面圖就明白了��。

由經過手提包識別訓練的模型給出的識別結果
我們的訓練數據中沒有“斧子”的圖片作為反例��,而斧子的頭部和模型學習過的手提包的圖像非常相似��。它是褐色的���,有著手提包的形狀和大小�����,而且被握在手里�����。
然后我們就這樣放棄了嗎�����?不���,我們可以通過主動學習來解決這個問題���,即對模型給出的錯誤判斷進行標記�����,然后把這些錯誤例子反饋給模型繼續訓練��。但憑借現有的技術來說�����,想像 Instagram 中的圖片���,如此開放的領域上達到完美的效果����,仍然是一項巨大的挑戰����。
對于我們人類來講�,關于糖尿病相關的工作很難�,但辨認斧子和手提包卻很容易��,這主要原因是斧子對我們來說是一種極為普遍的存在�����,一種大家都知道的常識���,并且這些內容超出了輸入到系統數據的范圍�。
▌識別攝像頭中的行人:這類問題很簡單:輸入非常受限(固定攝像機)���,而且類別(行人)也很標準�����?����?赡軙嬖谀繕吮徽趽醯认嚓P問題�,但總體來說這個問題很容易就可以解決����。不過����,如果對這個問題稍作改動��,就會變得困難很多:如攝像機是移動的����;或從不同方位�、角度�、范圍進行拍攝
—— 這個問題就變得更開放且棘手了��。
▌機器人抓取物體:這個問題是極其困難的���。它超出了標準分類和回歸問題的范圍�����,因為輸出是控制機器人的策略�,通常使用強化學習來進行訓練��,與有監督學習相比�����,這種學習方法還不太成熟�����。此外����,對象在大小��、形狀和抓取的方式上都會有所不同���,可能還要借助語義的理解����。但是這個問題可以由一個2歲的小孩子輕易解決(即使沒有固定攝像頭��、背景完全相同這些設定)�����,但對我們來說����,讓人工智能做這件事還有很長的路要走�����。
作者聲明:如果不同意我給出的答案�,我很樂于和大家討論�,因為在這個領域要學的知識很多����,我不認為我知道所有問題的答案��。
對計算機視覺與人工智能的期望
對計算機視覺系統和我們人類來說��,“難度”這個概念是有很大不同的����,這一點很容易引導我們對人工智能產生錯誤的期望�。工程師和科研人員不得不從現實出發來對待人工智能系統在開放域的表現���。
當前我們在對人工智能系統發展情況的理解上也還存在很多問題�。以自動化駕駛為例:在有約束(例如:高速公路)下駕駛與無約束(如:
市區����、小路...
...)下對駕駛存在著極大的區別��。如今大多數企業都基于在沒有司機操控下��,通過自動駕駛汽車所行駛的里程數來對自動化駕駛水平進行評估�����。這也促使了測試者更樂于把汽車放到容易駕駛的環境里��,但其實我們更應該做的是建立一些指標����,重點關注擴大自動化駕駛汽車正常駕駛的范圍��。
更概括地來講�����,我認為我們不應該再說什么“計算機視覺已經實現了����?��!边@樣的話了��。如果我們有足夠多已經標記了的數據和有約束的類別��,小范圍內的問題可能已經解決了����。但若將世界范圍的常識知識引入計算機視覺系統�,這仍然是一個巨大的挑戰���。

ClevR��,用于組合式語言和初級視覺推理的診斷數據集
其實現在很多的研究人員已經開始在進行這方面的研究了����,也有一些研究領域正在蓬勃的發展著��,例如:視覺推理�、物理發現法則�����、通過無監督/自我監督進行表征學習等��。AI 科技大本營在文末給大家列出了相關的研究文章����,方便大家學習���。
鑒于我對計算機視覺的研究與發展了解多一些����,上述都是我關于這方面的一些看法���,但我相信同樣的理由也可以應用到其它機器學習問題上���,特別是關于 NLP 應用深度學習與機器學習的研究領域����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
