
當我與越來越多的數據科學和 "大數據" 社區合作時��,我震驚地發現��,大部分從業者基礎都狹隘地集中在統計和計算專業知識上����,并沒有對正在研究的領域有扎實的基礎��。不管是政府機構�,還是商業公司���,許多崗位都有數據科學家的身影�����。我曾共事過的同事�,多是從計算機科學或硬件科學領域開始他們的職業生涯���。這種特定領域知識的缺乏如何影響當今的大數據和數據分析世界���?
在我接觸過的數據科學家中�,極少數在他們目前研究的學科和領域擁有深厚的背景或嚴格的培訓����。與我合作過的許多組織中��,數據科學家被視為即時問題解決者, 在組織的整個運作中快速移動���,分析一個領域中的深層技術�����。然后第二天去解決在另一個完全不同的領域中出現的復雜問題�����。每天早上��,數據科學者制作出電子報表�,當天下午便會收到模型的結果��,然而數據分析流程中的生產者和消費者之間幾乎沒有互動或溝通�。
這造成了一種危險的情況�����,數據科學家往往不熟悉他們所使用的數據中的細微差別或他們所研究的領域的專業假設���,并可能會無意中產生誤入歧途的分析���。這并不是說數據科學是一門糟糕的科學���,而是數據分析只是一種工具�����,而不是某種形式的普遍真理�����。其實所有的數據都是一樣����,大量數據以及用于分析這些數據的統計方法��、算法和軟件包必須與無數潛在錯誤作斗爭��。
正如我在無數場合所指出的���,挖掘數據和回答問題有很大的不同��。任何給定的數據集都只是對實際情況的某一方面體現����,但單一的數據集不可能提供了對所有現實存在的完美�、全面和公正的體現���。這意味著, 在分析數據方面���,對自己正在關注的數據有任何了解遠比擁有統計博士要重要得多���。正如我去年為《衛報》撰寫的文章那樣����,即使是像內特·西爾弗這樣最著名的統計學家���,也會對他們正在處理的數據做出錯誤的假設����。
進行數據挖掘與進行其他領域的實驗是一樣的: 實驗的實際執行是一個非常長的流程的最后階段����,即使在收集結果之后���,仍然有一個漫長而詳細的過程來驗證結果����。然而��,我遇到的數據科學家很少接受過實驗設計方面的嚴格培訓��,也很少有人完全理解和認可他們在分析的每個階段所做的無數假設����。
與任何實驗一樣, 數據分析有很長的流程�����,每個階段都會對環境產生影響���。首先是利用通過調查或傳感器儀器新收集的數據或推特等存儲庫的現有數據收集數據���。與任何實驗一樣��,用于收集數據的儀器和收集數據的條件會對最終數據產生巨大影響�,甚至有可能使數據捕捉感興趣現象的能力消失�����。一旦收集到數據�,就必須隔離收集環境的各種影響和偏見���,以嘗試清理數據和隔離錯誤�。這可能需要規范化來處理隨著時間的推移對集合環境的更改�����。有一系列的算法或統計方法用于清理和分析數據��,但這些方法往往可能會對數據的組成做出假設��,而這些假設可能不成立���,可能需要替代方法對錯誤和噪聲更加穩健�����。最后�����,分析的最終結果要求仔細考慮整個處理流程�����,以徹底消除假設所提議的結果以外的任何其他來源��。
我所看到的數據科學往往從抓取任何最容易訪問的數據集開始: 因此����,驅動查找的基礎數據更多的是基于哪些數據可以最快速地獲得�����,而不是哪些數據實際上最能回答問題���。一位域名專家可以告訴你, 從英語西方社交媒體平臺挖掘直播流媒體視頻可能不是評估偏遠森林村觀點的最佳方式�����,這個村莊只有一部太陽能非數據功能手機作為其唯一的手機與外界的聯系��。同樣, 在一個沒有移動數據滲透����、只有功能手機的地區�����,很少有居民有手機�。在打電話吃飯的手續上���,使用開放餐桌餐廳預訂來衡量疾病爆發可能不是一個可行的解決方案預訂不是當地傳統的一部分�。然而���,這兩者都給我被要求審查的重大項目帶來了嚴峻的驚喜����。問題是����,很少有數據科學項目涉及大量能夠對數據選擇過程進行這種檢查和深入了解的領域專家��。

也許接下來最關鍵的部分是: 驗證和清潔�����。這就是領域專業知識對于驗證當前數據是否可以轉換為實際支持所需分析的內容更為關鍵的地方��。例如, 我曾經被要求幫助監督一個按國家匯編失業數據的項目, 該項目可以追溯到幾百年前�。問題是, 每個國家對 "失業" 概念的定義都不同����。有些人將所有失業者混為一談, 而另一些人則將尋找的人與不找工作的人分開, 或將殘疾人排除在外或包括殘疾人�����、在家工作�、社會福利收據���、大學生等��。這些定義往往會隨著時間的推移而變化, 這意味著在一年的數據中, "失業" 可能只指一個國家的失業磚匠, 可能會將國家支持的福利領取者排除在另一個國家, 并可能包括所有個人, 包括所有個人全日制大學生在另一個, 然后改變第二年在一些國家, 但不是其他國家����。這在比較需要對數據進行廣泛研究和修補才能修復的國家時, 在數據中產生了非常奇怪的滲出和樓梯步進效應����。
不幸的是, 很少有數據科學家在探索性和魔鬼的數據集分析方面接受過廣泛的培訓�����。他們經常會下載一個數據集, 閱讀隨數據所附的文檔, 并完全根據文檔所說的數據應該是什么樣子進行分析����。當然, 在現實生活中, 數據很少與文檔完全匹配��。也許最著名的是, 在創建廣泛報道的2012年全球推特心跳分析時, 我們發現, 當時的文檔和其他數據科學家提供的公共統計數據表明, 推特數據所包含的數據不到1% 的地理標記推特�����。然而, 當我對 Twitter Decahose 進行各種模式和異常的初步掃描時, 一個早期的發現是, iPhones 將其地理位置信息存儲在一個沒有記錄和非標準的字段中, 這在推特中增加了1%可用的地理位置信息 (推特規模的大量信息)���。雖然有幾篇奇怪的論文評論說, 在這里和那里看到了一些奇怪的數據點, 但沒有人坐下來, 帶著完整的推特數據, 在上面進行詳盡的掃描, 尋找任何與文件不同的東西, 或者是像奇怪的一樣突出的東西��,如 JSON 工程中的技術錯誤等�����。
也許最致命的是, 我所遇到的數據科學家很少有在理解規范化和測量對結果的影響方面有過廣泛的培訓或背景, 從調查設計和管理到錯誤的數字精度����。隨著時間的推移, 幾乎所有數據集的可用性和準確性都呈指數級增長, 尤其是在后數字時代���。無論是看失業數據, 還是看提及特定主題的新聞文章數量, 任何數據集中捕捉到的現實的基本觀點都不是靜態的: 它是高度流動和動態的, 往往以非常非線性的方式變化�。這就需要廣泛的領域知識來了解數據集是如何編譯的, 以及它所測量的字段或現象的功能和細微差別����。
在所有關于推特的學術研究中, 很大一部分使用了免費的1% 流量媒體的API�����。然而, 一長串的研究認為, 1% 的流量是一個非隨機樣本的整個推特消防軟管與明顯的差異, 這表明我們對 Twitter 如何大規模運作的理解和知識可能是有偏見或錯誤的��。
在互聯網時代之前, 絕大多數涉及新聞報道的學術研究都是扭曲的, 因為它未能使被評估的網點的組成和總產量的潛在變化常態化���。新聞機構并不是及時固定的靜態實體--它們的主題焦點會隨著讀者利益的變化而變化, 每天發表的文章總量也會隨著時間的推移而發生巨大的變化�����。
2010年, 為了在美國教育委員會的《總統任期》中進行的一項研究, 保羅·馬蓋利和我在《紐約時報》的美國記錄報紙印刷版中研究了過去半個世紀來高等教育覆蓋面的變化�����。如果僅僅計算出每年提到所有美國研究型大學的原始文章數量, 由此得出的圖表顯示, 60年來對高等教育的興趣相對穩定���。
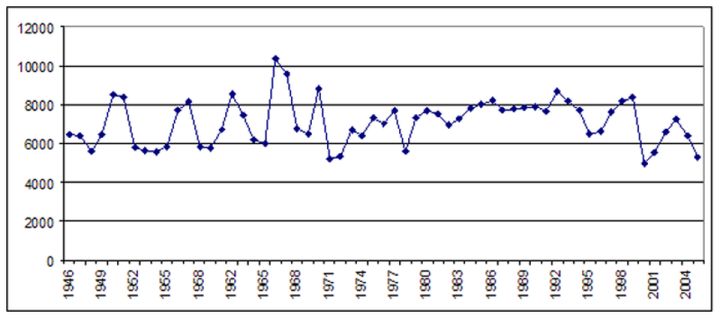
在《紐約時報》1945-2005年印刷版中提到一所研究型大學的文章總數 (信用: Kalev Leetaru/sunden 大學轉載)�。然而, 如下文所示, 在這60年期間 (1945-2005年), 《紐約時報》的年總產量線性萎縮了50% 以上���。
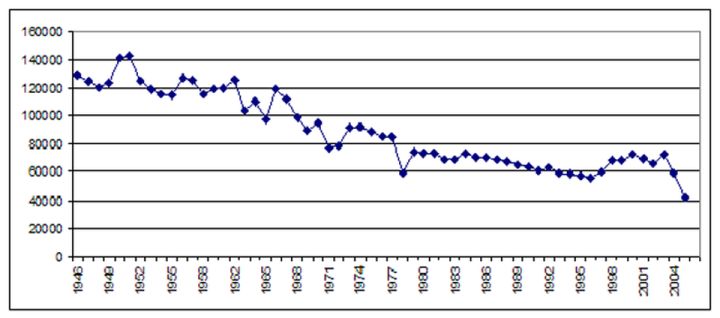
因此, 雖然在這60年里, 提到研究型大學的文章的絕對數量保持相對穩定, 但這是在論文縮小一半以上的背景下發生的, 這意味著如果我們每年除以原始文章的數量當年《紐約時報》所有文章的總數都提到了高等教育, 我們得到了一個截然不同的畫面, 這一情況顯示, 在這60年里, 這一情況穩定地幾乎增加了兩倍�����。
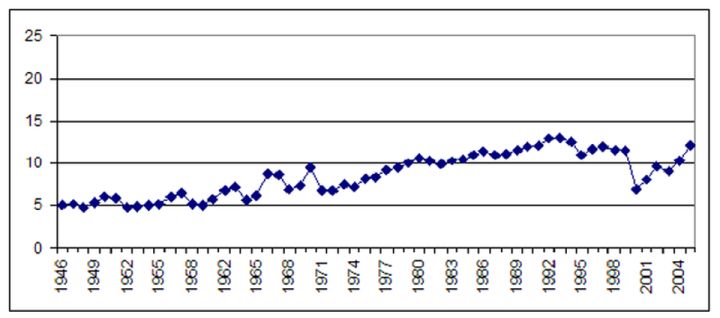
問題就出在這里--大多數研究審查媒體對某一主題的報道只是報道原始數量, 而不是通過被評估的網點的總產出的變化來常態化��。
即使在規范化之外, 數據科學家也經常通過對照輔助數據集檢查數據集來 "驗證" 數據集�����。然而, 如果比較數據集是由同一組織使用相同的數據源和方法生成的, 則不會提供真正的驗證點�。事實上, 我看到在同行評審文獻中發表的文章越來越多, 這些文章比較了多個數據集, 并認為其中一篇比另一個數據集更準確, 因為它表明它與第三個數據集的相關性更密切, 但第三個數據集是在哪里產生的使用相同的數據和方法����。這意味著, 相關檢查實際上只是評估這兩個項目在將相同的方法應用于相同的數據時的匹配程度, 而不是它們在評估有關現象時是否比第三個項目更準確�����。讓一名領域專家參與該項目, 將使這種錯誤在最初階段被抓住, 而不是通過同行審查才能生存到出版�。這也表明, 許多同行評審期刊, 包括一些最負盛名的領域, 缺乏領域專家來可信地同行評審他們的許多提交��。
數據集創建者可以做些什么來幫助分析師避免犯這類錯誤����?當 Culturomics 團隊發表 2010年的論文時, 他們意識到, 大量將使用其數據的人不會完全理解或理解正?��;闹匾?����。僅僅報告到1800年到年英語語文書籍中出現的每個單詞的原始次數就會產生巨大的誤導, 因為在這一期間, 按年出版的數字化書籍的總宇宙成倍增長�����。為了解決這個問題, 作者創建了一個公共訪問視圖, 該視圖只報告規范化的值, 而無法查看原始計數��。這可確保普通用戶不會被引入歧途�。對于擁有處理數十億行數據集的技術能力的高級用戶來說, 這些數據集也可供下載, 前提是任何有技能處理原始數據的人都可能擁有了解如何正確規范化數據.
簡而言之, Culturomics 的創作者主動設計了他們的數據集的發布, 以便積極引導用戶遠離無意中的錯誤, 而不僅僅是在 web 服務器上翻拍一組 CSV 文件, 并交叉手指, 讓人們使用這些文件正確�。
正如我在2014年為 wired 撰寫的文章中所說, "要使大數據超越營銷炒作, 走向真正的變革性解決方案, 就必須從產生它的計算機科學實驗室中 ' 成長 ', 花更多的時間去理解它所應用的特定領域的算法和數據, 而不是操作它們的計算算法.
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
