作者 | Jeremy Curuksu
編譯 | CDA數據分析師
數不清的企業通常使用機器學習(ML)來輔助決策�。但是��,在大多數情況下��,機器學習系統做出的預測和業務決策仍然需要人類用戶的直覺來做出判斷���。
在本文中����,我將展示如何將ML與靈敏性分析結合起來以開發數據驅動的業務策略�����。這篇文章重點關注客戶流失�����,同時涵蓋了使用基于ML的分析時經常出現的問題���。這些問題包括處理不完整和不平衡的數據���,推導模型選擇以及定量評估這些選擇的潛在影響方面的困難�。
具體來說�,我使用ML識別可能流失的客戶���,然后將特征重要性與方案分析結合使用以得出定量和定性的建議�����。然后����,組織可以使用結果來做出適當的戰略和戰術決策��,以減少未來的客戶流失����。該用例說明了數據科學實踐中出現的幾個常見問題����,例如:
-
低信噪比�����,特征與流失率之間缺乏明確的相關性
-
高度不平衡的數據集(其中90%的客戶不流失)
-
使用概率預測和調整來確定決策機制�����,以最大程度地減少對客戶流失問題進行過度投資的風險
端到端實施代碼可在Amazon SageMaker中使用�,也可以在Amazon EC2上獨立使用����。
在這種用例中��,我考慮一家提供不同類型產品的虛構公司�。我將其兩個主要產品稱為產品A和B���。我僅了解有關該公司產品和客戶的部分信息�����。該公司最近發現客戶流失有所增加��。數據集包含有關數以千計的客戶的不同屬性的信息�����,這些信息是在幾個月內收集和分類的��。這些客戶中有一些已經流失了��,有些還沒有�����。通過使用特定客戶列表����,我將預測任何一個人流失的可能性�。在此過程中�����,我嘗試回答幾個問題:我們能否創建一個可靠的客戶流失預測模型���?哪些變量可以解釋客戶流失的可能性����?公司可以采取哪些策略來減少客戶流失��?
這篇文章將介紹使用ML模型創建減少客戶流失策略的以下步驟:
1. 探索數據和設計新功能
我首先介紹如何通過查看各個輸入要素與客戶流失標簽之間的簡單關聯來探索客戶數據����。我還研究了特征之間的關聯(稱為互相關或協方差)�。這使我能夠做出算法決策���,尤其是確定那些特征需要派生����,更改或刪除�。
2. 開發一組ML模型
然后��,我建立了多個機器學習算法��,包括自動特征選擇����,并結合了多個模型來提高性能�。
3. 評估和完善ML模型的性能
在第三部分中����,我測試了我開發的不同模型的性能��。從這里��,我確定了一種決策機制���,該機制可以將高估客戶流失數量的風險降到最低����。
4. 將ML模型應用于業務策略設計
最后�����,在第四部分中��,我將使用ML結果來了解影響客戶流失的因素��,得出特征選擇并量化評估這些選擇對客戶流失率的影響�。我通過執行靈敏性分析來做到這一點��,在該分析中�����,我修改了在現實生活中可以控制的一些因素(例如折現率)�,并預測了針對該控制因素的不同值預期的客戶流失率的相應降低幅度����。所有預測都將使用第3節中確定的最佳ML模型進行�����。
探索數據和建立新的特征
在ML模型開發期間經常出現問題的關鍵問題包括輸入數據中共線和低方差特征的存在����,離群值的存在以及數據的丟失(缺少特征和某些特征的值)�����。本節介紹如何使用Amazon SageMaker處理Python 3.4中的每個問題��。(我還通過深度學習AMI在Amazon EC2實例上評估了獨立代碼�。兩者都可用����。)
這種帶有時間戳的數據可以在某些指標內包含重要的模式��。我將這些指標分為每日�,每周和每月的細分�,這使我能夠開發新功能來說明指標的動態性質�����。
然后��,我研究原始特征和新特征之間每個簡單的一對一(也稱為邊際)關聯和關聯度量��。我還研究了特征與客戶流失標簽之間的相關性�����。(請參見下圖)���。
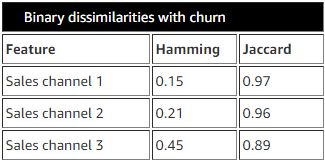
可以通過使用邊際相關和Hamming / Jaccard距離來處理低方差特征(當流失標簽更改時不會顯著變化的特征)����,如下表所示���。Hamming / Jaccard距離是專門為二進制結果設計的相似性度量�。這些措施提供了一個觀點���,即每個特征對客戶流失提供了多大程度的信息��。
刪除低方差特征是個好習慣����,因為無論是要預測什么�����,它們都不會發生明顯變化��。因此�����,它們的存在不能幫助進行分析��,并且實際上會使學習過程效率降低�����。
下表顯示了特征和客戶流失之間的最高相關性和二進制差異�。48個原始特征和派生特征中僅顯示最重要的特征���?!?nbsp;Filtered“列包含對異常值和缺失值進行數據過濾時獲得的結果��。
上表的主要結論是�����,三個銷售渠道似乎與客戶流失成反比��,并且與客戶流失的大多數邊際相關性很?��。ā?.1)����。對異常值和缺失值應用過濾器會改善邊際相關的統計顯著性�����。上表的右列描述了這種效果�。
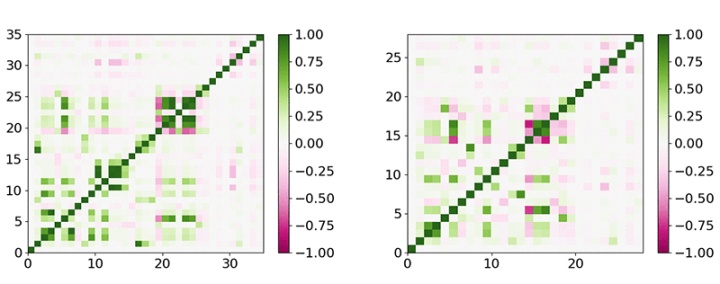
共線特征的問題可以通過計算所有特征之間的協方差矩陣來解決����,如下圖所示���。該矩陣為判斷某些特征具有的冗余量提供了新的角度����。刪除冗余特征是一個好習慣���,因為它們會產生偏差并需要更多的計算量����,這會使學習過程效率降低����。
上圖中的左圖表示某些特征(例如價格和某些預測指標)是共線的��,其中ρ> 0.95��。設計下一節中描述的ML模型時�����,我只保留了其中的一個����,這給了我留下了大約30個特征����,如上圖中的右圖所示���。
缺失和異常數據的問題通常通過經驗規則來處理����,例如在缺少某些記錄數據值或它們超過樣本標準差的三倍時刪除觀察值(客戶)�����。
由于數據缺失是一種常見的問題���,你可以使用樣本或總體的均值或中位數來估算缺失值���,作為刪除觀測值的替代方案�����。那就是我在這里所做的:我刪除了缺失超過40%以上的特征��,并將剩下每個特征的缺失值替換為中位數���。讀者應注意��,一種更高級的�����,最佳實踐的缺失數據填補方法是訓練一種基于其他特征的監督學習模型���,但是這可能需要大量的工作����,因此在此不做介紹�����。當我在數據中遇到異常值時�����,我刪除了那些數值超過均值六倍標準差的客戶��?�?偣矂h除了16096個觀察結果中的140個(<1%)��。
開發一組ML模型
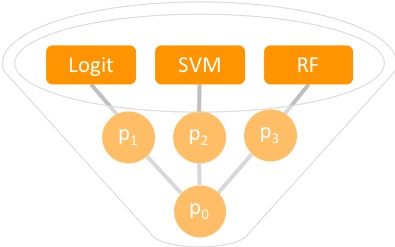
在本節中��,我將開發和組合多個ML模型以利用多種ML算法的功能�����。集成建模還可以使用整個數據集中的信息���,即使流失標簽的分布高度不平衡�����,如以下流程圖所示����。
作為刪除低方差特征的一種很好的做法�����,我通過應用一個快速簡單的方差過濾器進一步將特征空間限制為最重要的特征����。此過濾器會刪除對95%的客戶不顯示差異的特征��。為了根據特征對客戶流失的綜合影響(而不是邊際影響)篩選特征�,我使用了帶有逐步回歸的網格搜索�,進行了基于ML的特征選擇����。請參閱下一節的詳細信息��。
在實現ML模型之前���,我將數據隨機分為兩組���,并確定了30%的測試集�。就像在下一節中討論的那樣�,我還在70%/30%拆分的基礎上使用了10倍交叉驗證�����。K-folding是一個迭代周期��,可以對K個評估的平均性能進行平均��,每個測試都針對單獨的K%保留數據集�。
分別訓練了三種ML算法(邏輯回歸�����,支持向量機和隨機森林)�����,然后將它們組合在一起��,如前面的流程圖所示�����。集成方法在文獻中稱為”軟投票”�����,因為它采用了不同模型的平均概率并將其用于客戶分類(在前面的流程圖中也可以看到)��。
客戶流失率僅占數據的10%��;因此���,數據集是不平衡的�。我測試了兩種解決類別不平衡的方法�����。
-
在第一種最簡單的方法中��,訓練是基于對豐富類(沒有流失的客戶)的隨機抽樣來進行的�����,以匹配稀有類(有流失的客戶)的規模����。
-
在第二種方法中(如下圖所示)�,我將訓練基于模型的集合�����,其中每個模型使用9個豐富類的隨機樣本(不進行替換)和稀有類的一個完整樣本�����。我之所以選擇9倍�,是因為類別的不平衡程度大約是1比9(如下圖的直方圖所示)�。因此��,1-9是使用豐富類中的全部或幾乎所有數據所需的采樣量��。這種方法比較復雜��,但是會使用所有可用信息��,從而提高了通用性��。我將在以下面章節中評估其有效性�。
對于這兩種方法��,在測試集上考慮實際情況而保持類的不平衡來評估模型性能����。
評估和完善ML模型的性能
在本節中����,我測試了上一節中開發的不同模型的性能��。然后����,我確定了一種決策機制�����,該機制最大程度地降低了高估可能流失的客戶數量的風險(稱為誤報率)�����。
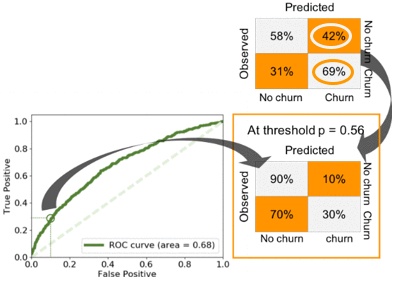
在ML性能評估中經常使用所謂的接收算子特性(ROC)曲線來補充列聯表���。當更改概率閾值以推斷正類別和負類別(在此項目中���,分別為流失類和非流失類)時���,ROC曲線提供了準確性的不變度量�。它涉及繪制所有準確的陽性預測(真陽性)與假陽性的圖表�。請參閱下表�。
默認情況下�,將對不同ML模型預測的概率進行校準����,以使p> 0.5的值對應一個類別�����,而p <0.5的值對應另一類別�����。此閾值是一個超參數�����,可以對其進行微調以最大程度地減少一類的錯誤分類�。這是以增加另一種錯誤分類為代價的�,這會影響不同性能指標的準確性和精確度���。相比之下�����,ROC曲線下的面積是性能的不變度量��,在任何閾值下都保持不變���。
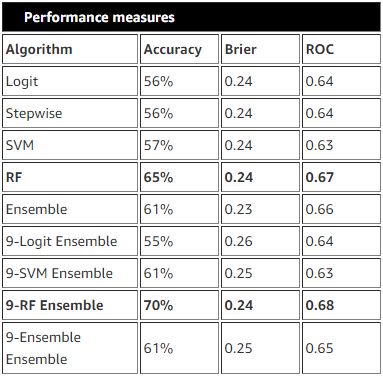
下表描述了使用稀有類9倍訓練總體的不同ML模型的性能����。您可以看到隨機森林具有最佳性能�,并且9倍總體的綜合性更好���,ROC AUC得分為0.68����。這個模型是表現最好的�。
下圖描述了整體最佳模型的表現(9倍總體的隨機森林模型)以及對精度和誤差的優化���。當使用概率閾值0.5時�,最好的結果可以準確預測69%的流失客戶�。
查看ROC曲線����,您可以看到同一模型可以準確預測30%的客戶流失��,而將非流失客戶預測為流失客戶的概率為10%��。使用網格搜索��,我發現閾值為p = 0.56���。如果您想最大程度地減少高估會流失客戶數量的風險(例如���,由于我們為保留這些客戶而進行的活動可能會成本很高)�,則可能要使用此模型����。
將ML模型應用于業務策略設計
在本節中�����,我將使用我開發的ML模型來更好地理解影響客戶流失的因素��,得出減少流失的特征選擇����,并評估這些選擇可能對流失率產生的影響�����。
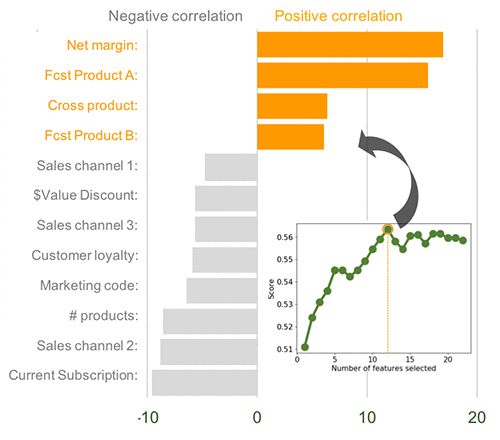
考慮到特征對客戶流失的綜合影響����,我使用了逐步邏輯回歸來評估特征的重要性�。如下圖所示����,回歸確定了12個關鍵特征���。當我在回歸模型中包含這12個特征時�,預測得分最高���。
在這12個因素中�,凈利潤率�,產品A和產品B的預計購買量以及多個產品客戶的指標是最容易引起客戶流失的特征���。減少客戶流失的因素包括三個銷售渠道�����,一個營銷活動����,折扣價值�,總體訂購額���,客戶忠誠度以及購買的產品總數����。
因此�����,向最易流失的客戶提供折扣似乎是一種簡單有效的策略����。當然還有其他戰略手段����,包括增強A和B以外的產品�,銷售渠道1-3����,營銷活動和長期合同之間的協同作用����。根據數據��,利用這些手段可能會減少客戶流失�����。
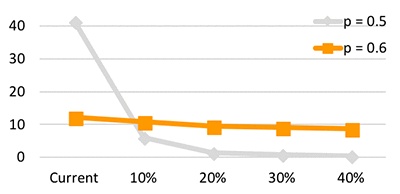
最后��,我使用了靈敏性分析:我對ML模型確定為可能流失的客戶應用了高達40%的折扣�����,然后重新運行該模型以評估合并了折扣后預計會有多少客戶流失���。
當我將模型的p閾值設置為0.6以使損失最小化至10%時�,我的分析預測20%的折扣會減少25%的客戶流失����。假設在此閾值下的真陽率約為30%���,這個分析表明采用20%的折扣方法可以消除至少8%的客戶流失���。有關詳細信息�����,請參見下圖�����。折扣策略是遇到客戶流失的企業可以考慮采取的緩解問題的簡單的第一步����。
結論
在這篇文章中���,我演示了如何執行以下操作:
-
探索數據并獲得新特征����,以最大程度地減少由于缺少數據和低信噪比而引起的問題���。
-
設計一組ML模型以處理強不平衡的數據集����。
-
選擇性能最佳的模型���,并優化決策閾值�����,以最大程度地提高精度并最大程度地減少客戶流失����。
-
使用結果得出特征選擇并定量評估其對客戶流失率的影響�����。
在這個特定的用例中�����,我開發了一個模型��,該模型可以識別30%可能流失的客戶����,而將假正率限制為10%�。這項研究支持在服務和銷售渠道之間建立協同作用以保留更多客戶的基礎上��,部署提供折扣的短期策略和制定長期戰略的有效性�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;














 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
