相信做數據分析的小伙伴一定都聽說過啤酒與尿布的故事����,超市把有關聯的東西放在一起�,以方便顧客購買�����,這個故事體現的就是關聯規則���。關聯規則又被稱為關聯分析�,它的目的是在一堆事物中找出具有關聯的事物�����。經常被應用于超市購物和電商網購的數據集中���,對超市來說��,運用關聯規則��,能夠優化產品的位置擺放�,方便顧客購買;對電商來說�����,關聯規則能夠幫助優化商品所在的倉庫位置����,從而節約成本�,增加經濟效益�����。
一��、關聯規則經常用支持度�、置信度和提升度來進行評估�����。
支持度:幾個關聯的數據在數據集中出現的次數占總數據集的比重�。
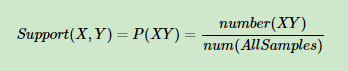
以啤酒和尿布為例�,就是指客戶同時購買尿布和啤酒的概率�����。
置信度:一個數據出現后�,另一個數據出現的概率�,或者說數據的條件概率�����。
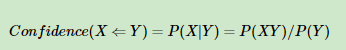
例如:
客戶購買尿布時購買啤酒的置信度�,也就是購買尿布的人�����,同時購買啤酒的概率�����,( 尿布 -> 啤酒 ) 的置信度=同時購買尿布和啤酒的人數/購買尿布的人數
提升度:表示含有Y的條件下��,同時含有X的概率���,與X總體發生的概率之比
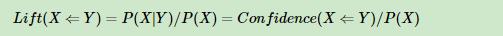
二����、實現算法
Apriori算法是常用的用于挖掘出數據關聯規則的算法
Apriori算法采用了迭代的方法
1.掃描所有數據集���,先找出候選1項集及對應的支持度�,篩選去掉低于支持度的1項集��,產生頻繁1項集���。
2.在上述基礎上�,對剩下的頻繁1項集進行連接����,得到候選的頻繁2項集����,將低于支持度的候選頻繁2項集剪枝去掉���,產生真正的頻繁2項集����,
3.以此類推����,迭代下去����,直到無法找到頻繁k+1項集為止也就是���,當第k次循環的時候�,選擇頻繁k項集進行并集��,生成k候選集�����, 對k候選集進行篩選剪枝��,產生k頻繁項集�����,就是算法的輸出結果
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
