今天小編給大家帶來的是現在非?�;鸨?a href='/map/jiqixuexi/' style='color:#000;font-size:inherit;'>機器學習方法——集成學習���。集成學習����,顧名思義����,通過將多個單個學習器集成/組合在一起�����,使它們共同完成學習任務�����,有時也被稱為“多分類器系統(multi-classifier system)”�、基于委員會的學習(Committee-based learning)�����。
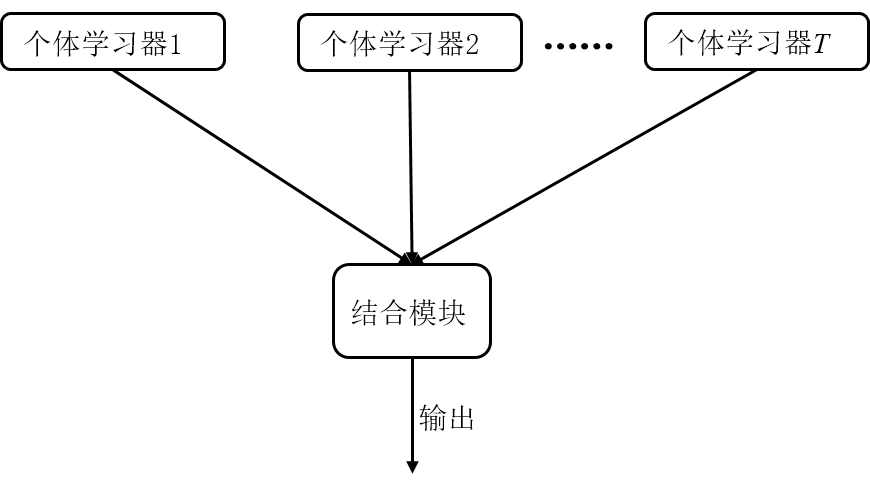
它本身不是一個單獨的機器學習算法����,而是通過構建并結合多個機器學習器來完成學習任務��。也就是我們常說的“博采眾長”�����。集成學習可以用于分類問題集成���,回歸問題集成�����,特征選取集成�����,異常點檢測集成等等�,可以說所有的機器學習領域都可以看到集成學習的身影���。
一般集成學習會通過重采樣獲得一定數量的樣本���,然后訓練多個弱學習器(分類精度稍大于50%)����,采用投票法��,即“少數服從多數”原則來選擇分類結果�����,當少數學習器出現錯誤時�����,也可以通過多數學習器來糾正結果���。
集成學習分類
目前根據個體學習器的生成方式�����,集成學習可以分為兩大類:
1)個體學習器之間存在較強的依賴性���,必須串行生成的序列化方法:boosting類算法;
Boosting是一簇可將弱學習器提升為強學習器的算法�����。其工作機制為:先從初始訓練集訓練出一個基學習器�,再根據基學習器的表現對樣本分布進行調整��,使得先前的基學習器做錯的訓練樣本在后續收到更多的關注���,然后基于調整后的樣本分布來訓練下一個基學習器;如此重復進行���,直至基學習器數目達到實現指定的值T�����,或整個集成結果達到退出條件��,然后將這些學習器進行加權結合��。
2)個體學習器之間不存在強依賴關系����,可以并行生成學習器:bagging和隨機森林
Bagging的算法原理和 boosting不同��,它的弱學習器之間沒有依賴關系����,可以并行生成�����。
Bagging的基本流程:
1.經過T輪自助采樣���,可以得到T個包含m個訓練樣本的采樣集���。
2.然后基于每個采樣集訓練出一個基學習器�。
3.最后將這T個基學習器進行組合����,得到集成模型���。
隨機森林(Random Forest�����,簡稱RF) 是Bagging的一個擴展變體��。
隨機森林對Bagging做了小改動:
1.Bagging中基學習器的“多樣性”來自于樣本擾動���。樣本擾動來自于對初始訓練集的隨機采樣�����。
2.隨機森林中的基學習器的多樣性不僅來自樣本擾動�����,還來自屬性擾動�。
3.這就是使得最終集成的泛化性能可以通過個體學習器之間差異度的增加而進一步提升�。
4.隨機森林在以決策樹為基學習器構建Bagging集成模型的基礎上����,進一步在決策樹的訓練過程中引入了隨機屬性選擇���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
