RDD 即 Resilient Distributes Dataset, 叫做彈性分布式數據集�,是spark中最基礎��、最常用的數據結構��。其本質是把input source 進行封裝����,封裝之后的數據結構就是RDD���。RDD具有數據流模型的特點:自動容錯�����、位置感知性調度和可伸縮性����。RDD允許用戶在執行多個查詢時顯式地將工作集緩存在內存中�����,后續的查詢能夠重用工作集��,這極大地提升了查詢速度�。
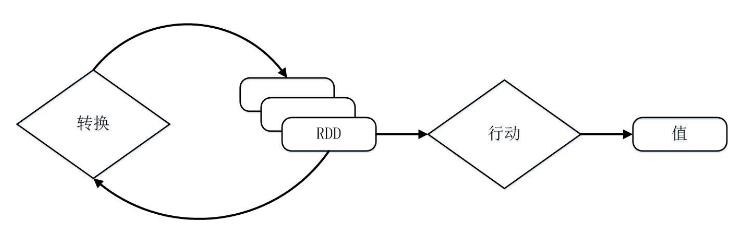
RDD提供了一組豐富的操作以支持常見的數據運算����,分為“行動”(Action)和“轉換”(Transformation)兩種類型�,前者用于執行計算并指定輸出的形式��,后者指定RDD之間的相互依賴關系��。兩類操作的主要區別是�,轉換操作(比如map���、filter���、join等)接受RDD并返回RDD����,而行動操作(比如count�����、collect等)接受RDD但是返回非RDD(即輸出一個值或結果)����。
RDD采用了惰性調用����,即在RDD的執行過程中���,真正的計算發生在RDD的“行動”操作�����,對于“行動”之前的所有“轉換”操作�����,Spark只是記錄下“轉換”操作應用的一些基礎數據集以及RDD生成的軌跡�����,即相互之間的依賴關系���,而不會觸發真正的計算����。
RDD的五大基本屬性
1)A list of partitions 一組分片(Partition)�,即數據集的基本組成單位�����。對于RDD來說�,每個分片都會被一個計算任務處理�����,并決定并行計算的粒度�。用戶可以在創建RDD時指定RDD的分片個數�,如果沒有指定�����,那么就會采用默認值����。默認值就是程序所分配到的CPU Core的數目�����。
2)A function for computing each split 一個計算每個分區的函數�。Spark中RDD的計算是以分片為單位的�����,每個RDD都會實現compute函數以達到這個目的���。compute函數會對迭代器進行復合��,不需要保存每次計算的結果�。
3)A list of dependencies on other RDDs RDD之間的依賴關系�。RDD的每次轉換都會生成一個新的RDD����,所以RDD之間就會形成類似于流水線一樣的前后依賴關系�����。在部分分區數據丟失時�,Spark可以通過這個依賴關系重新計算丟失的分區數據���,而不是對RDD的所有分區進行重新計算�。
4)Optionally,a Partitioner for key-value RDDs 一個Partitioner�����,即RDD的分片函數����。當前Spark中實現了兩種類型的分片函數�,一個是基于哈希的HashPartitioner��,另外一個是基于范圍的RangePartitioner��。只有對于key-value的RDD���,才會有Partitioner�����,非key-value的RDD的Parititioner的值是None����。Partitioner函數不但決定了RDD本身的分片數量��,也決定了parent RDD Shuffle輸出時的分片數量����。
5) Optionally,a list of preferred locations to compute each split 一個列表���,存儲存取每個Partition的優先位置(preferred location)�����。對于一個HDFS文件來說���,這個列表保存的就是每個Partition所在的塊的位置�。按照“移動數據不如移動計算”的理念����,Spark在進行任務調度的時候�����,會盡可能地將計算任務分配到其所要處理數據塊的存儲位置�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
