機器學習中���,當原始數據的分類極不均衡����,需要對不平衡數據進行處理�,而下采樣就是處理方法之一����。簡單來說就是從多數類中隨機抽取樣本從而減少多數類樣本的數量���,使數據達到平衡�����。
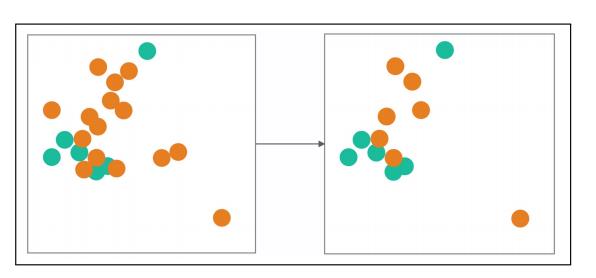
下采樣�����,通常適用于正負樣本相差較大���,而且小樣本數據不足的情況���。就是將大樣本中數據使用一定的方法取出一部分���,讓正負樣本數量相當�����。但是下采樣的缺點也很明顯����,就是沒有學到全部的數據��,只考慮了部分數據的情況���。
下采樣的方法常見的有:
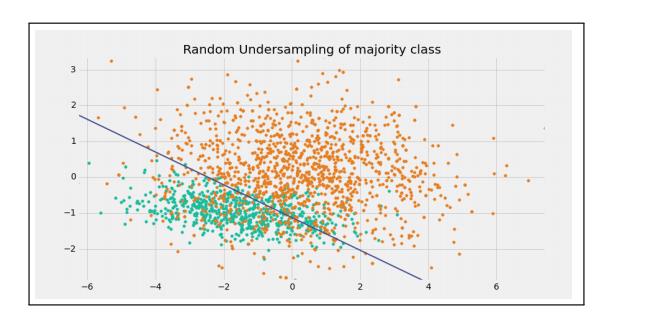
1.隨機下采樣法���。這種方法不能考慮到全部數據���,在使用過程中會使用一些方式減小信息的損失����。方法很簡單�,從多數類樣本中隨機選取一些����,直接剔除掉�����。這種方法的最大缺點是�����,沒有考慮到全部數據��,被剔除的樣本可能包含著一些重要信息��,導致最終學習出來的模型效果比較差�。
2.EasyEnsemble����,就是利用模型融合的方法�,將多數類樣本隨機劃分成n個子集�,每個子集的數量等于少數類樣本的數量�,多次進行下采樣產生多個不同的模型�����,通過組合這些模型的結果���,得到最終的結果��。
3.BalanceCascade����,即利用增量訓練也就是有監督結合Boosting的方法���,在第n輪訓練中����,將從多數類樣本中抽樣得來的子集與少數類樣本結合起來訓練一個基學習器H�����,訓練完后多數類中能被H正確分類的樣本不放回�����,然后對剩下的樣本訓練生成第二個基學習器�,以此類推���,最后將不同的基學習器集成起來�����。
3.NearMiss,本質上是一種原型選擇(prototype selection)方法�,就是從多數類樣本中選取最具代表性的樣本用于訓練�����,這主要是為了緩解隨機欠采樣中的信息丟失問題��。NearMiss采用一些啟發式的規則來選擇樣本�,根據規則的不同可分為3類:
NearMiss-1:選擇到最近的K個少數類樣本平均距離最近的多數類樣本
NearMiss-2:選擇到最遠的K個少數類樣本平均距離最近的多數類樣本
NearMiss-3:對于每個少數類樣本選擇K個最近的多數類樣本��,目的是保證每個少數類樣本都被多數類樣本包圍
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
