R語言是一種用來進行數據分析�����、繪圖的解釋型語言�。而我們在數據分析過程中會遇到許多缺失值�����,我們必須對這些缺失值進行處理�,才能更好地進行下一步工作����。今天小編跟大家分享R語言缺失值的判別和處理方法�,希望對大家研究和學習R語言有幫助�����。
一�����、R語言中的缺失值NA
在R語言中通常用NA來表示缺失值��,NA表示數據集中��,該數據遺失����、不存在����。在針對具有NA的數據集進行函數操作的時候����,不會直接剔除這個NA��。
二���、R語言識別缺失值
NA:代表缺失值;
NaN:代表不可能的值;
Inf:代表正無窮;
-Inf:代表負無窮���。
is.na():識別缺失值;
is.nan():識別不可能值;
is.infinite():無窮值���。
is.na()����、is.nan()和is.infinte()函數的返回值示例
列表顯示缺失值:
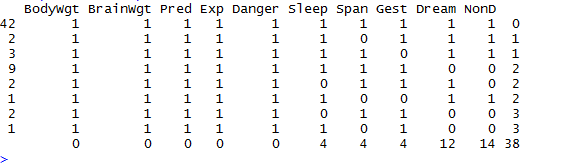
> library(mice)
> data(sleep,package="VIM")
> md.pattern(sleep)
三�����、R語言探索缺失值模式
在R語言中是利用mice包中的md.pattern函數來探索缺失值模式的�����。
library(mice)
md.pattern(sleep)
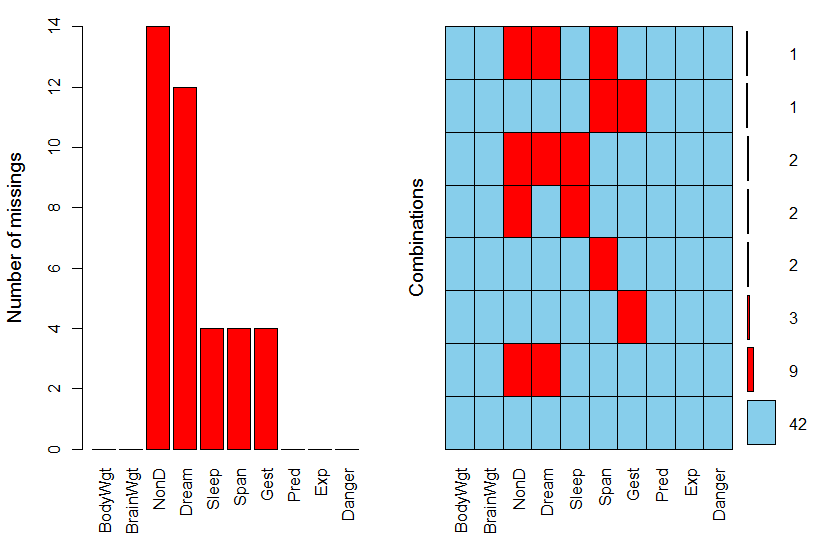
通過上圖�,我們可以看出:左邊圖能夠顯示出每個變量中含缺失值得個數���,右邊圖能夠顯示出變量組合的缺失值個數
四���、R語言缺失值處理
1.如果缺失數據較少時���,可以直接刪除相應樣本
刪除缺失數據樣本的前提為:缺失數據的比例較少�,并且缺失數據是隨機出現的���,這種情況下��,刪除缺失數據之后對于分析結果的影響不是很大�。
2.對缺失數據進行插補
(1)如果滿足正態分布�,用平均值進行填補;
(2)如果偏態分布或者離群值的分���,布用中位數進行填補���。
注意:均值或中位數來代替缺失值���,其優點在于不會減少樣本信息�,處理簡單��。但是缺點在于當缺失數據不是隨機出現時會產成偏誤����。
(3)多重插補是通過變量間關系來預測缺失數據��,利用蒙特卡羅方法生成多個完整數據集�,再對這些數據集分別進行分析��,最后對這些分析結果進行匯總處理����。能夠用mice包實現����。
3.利用對缺失數據不敏感決策樹等分析方法
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
