協同過濾推薦算法是誕生時間最早�,而且應用廣泛的�,著名的推薦算法��。其最主要的功能進行是預測和推薦��。協同過濾推薦算法可以通過對用戶歷史行為數據的挖掘����,從而發現用戶的偏好����,并且基于不同的偏好�,將用戶劃分為不同的群組���,并推薦品味相似的商品�?����;谟脩舻?a href='/map/xietongguolv/' style='color:#000;font-size:inherit;'>協同過濾算法user-based collaboratIve filtering���,是協同過濾推薦算法的極為重要的一個分類�����,今天小編主要給大家分享基于用戶的協同過濾算法的原理和實現���。
一����、基于用戶的協同過濾算法概念
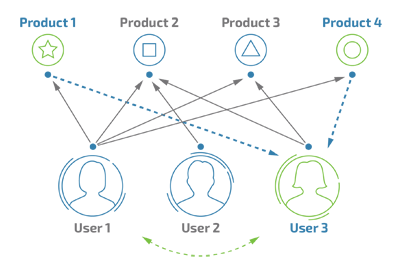
基于用戶(user-based)的協同過濾算法是通過��,挖掘用戶的歷史行為數據�,發現用戶對商品或內容的偏好�����,并對這些偏好進行度量和打分�。之后根據不同用戶對相同商品或內容的態度以及偏好程度�����,來計算用戶之間的相似度關系�?�;谟脩舻?a href='/map/xietongguolv/' style='color:#000;font-size:inherit;'>協同過濾���,主要計算的是用戶與用戶之間的相似度���,只需要找出相似用戶喜歡的物品�,并預測出目標用戶對對應物品的評分���,就能夠找到評分最高的物品推薦給用戶����,這樣能夠挖掘用戶的隱藏屬性��。
二���、基于用戶的協同過濾算法原理
基于用戶的協同過濾算法主要包括以下兩個步驟:
(1) 找到與目標用戶興趣相似的用戶集合�。

(2) 找到此集合中的用戶感興趣的�����,并且目標用戶沒有接觸過的的物品推薦給目標用戶��。

基于用戶User-CF算法的假設是目標用戶和其他用戶的興趣�、偏好相似����,那么他們喜歡的東西都應該也相似�����,就是常說的人以群分�。
基于用戶的協同過濾算法適用于用戶較少���、用戶個性化興趣不太顯著的情況��,這樣�����,在推薦過程中用戶新的行為不一定會導致推薦結果的變化��,但是如果用戶過多�����,那么計算用戶相似矩陣的代價就會太大����。并且這一算法不能解決新用戶進來的冷啟動問題�,新物品進來卻可以較快地進行推薦��。
三�、算法實現
1.計算用戶相似度
user-item:
movieId 1 2 3 4 5 6 7 8
userId
1 3.5 2.0 NaN 4.5 5.0 1.5 2.5 2.0
2 2.0 3.5 4.0 NaN 2.0 3.5 NaN 3.0
3 5.0 1.0 1.0 3.0 5.0 1.0 NaN NaN
4 3.0 4.0 4.5 NaN 3.0 4.5 4.0 2.0
5 NaN 4.0 1.0 4.0 NaN NaN 4.0 1.0
6 NaN 4.5 4.0 5.0 5.0 4.5 4.0 4.0
7 5.0 2.0 NaN 3.0 5.0 4.0 5.0 NaN
8 3.0 NaN NaN 5.0 4.0 2.5 3.0 4.0
# 構建共同的評分向量
def build_xy(user_id1, user_id2):
bool_array = df.loc[user_id1].notnull() & df.loc[user_id2].notnull()
return df.loc[user_id1, bool_array], df.loc[user_id2, bool_array]
#如此用戶評分矩陣中用戶1����,和用戶2的共同評分向量是
movieId
1 3.5
2 2.0
5 5.0
6 1.5
8 2.0
Name: 1, dtype: float64,
movieId
1 2.0
2 3.5
5 2.0
6 3.5
8 3.0
Name: 2, dtype: float64)
# 皮爾遜相關系數
def pearson(user_id1, user_id2):
x, y = build_xy(user_id1, user_id2)
mean1, mean2 = x.mean(), y.mean()
# 分母
denominator = (sum((x-mean1)**2)*sum((y-mean2)**2))**0.5
try:
value = sum((x - mean1) * (y - mean2)) / denominator
except ZeroDivisionError:
value = 0
return value
2.找到相似度最高的用戶并進行推薦:
# 計算最相似的鄰居
def computeNearestNeighbor(user_id, k=3):
return df.drop(user_id).index.to_series().apply(pearson, args=(user_id,)).nlargest(k)
#與用戶3相似的前3個用戶
userId
1 0.819782
6 0.801784
7 0.766965
Name: userId, dtype: float64
#推薦
def recommend(user_id):
# 找到最相似的用戶id
nearest_user_id = computeNearestNeighbor(user_id).index[0]
print('最相似用戶ID:')
print nearest_user_id
# 找出鄰居評價過�、但自己未曾評價的項目
# 結果:index是項目名稱���,values是評分
return df.loc[nearest_user_id, df.loc[user_id].isnull() & df.loc[nearest_user_id].notnull()].sort_values()
#對用戶3進行推薦結果
最相似用戶ID:
1
movieId
8 2.0
7 2.5
Name: 1, dtype: float64
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
