通常來說���,計算機對于網絡上存在的大量半結構化或結構化的文本數據�,計算機很難直接進行處理����,因此我們需要在文本分類之前對這些數據作相應的預處理����。 文本的預處理分為:文本分詞�����、去除停用詞��、詞義消歧�、統計等處理���。英文文本各單詞之間則有代表分割的空格��,而中文文本則不相同�,沒有詞的界限�����,因此我們對中文文本進行分類之前���,首先要進行分詞處理�,這也就是我今天要分享給大家的中文文本分類的關鍵技術--中文分詞���。
一�、中文分詞概念
中文分詞���,Chinese Word Segmentation)���,指的是將一個漢字序列切分成一個一個單獨的詞�����。再具體解釋一下:分詞指的是:將連續的字序列按照一定的規范重新組合成詞序列的過程��,分詞效果會直接對影響詞性�����、句法樹等模塊的效果產生影響�。當然���,分詞只是一個工具�,隨著場景的不同����,要求也會隨之變化�����。
在人機自然語言交互中�,成熟的中文分詞算法可以達到更好的自然語言處理效果��,幫助計算機對復雜的中文語言的理解·����。
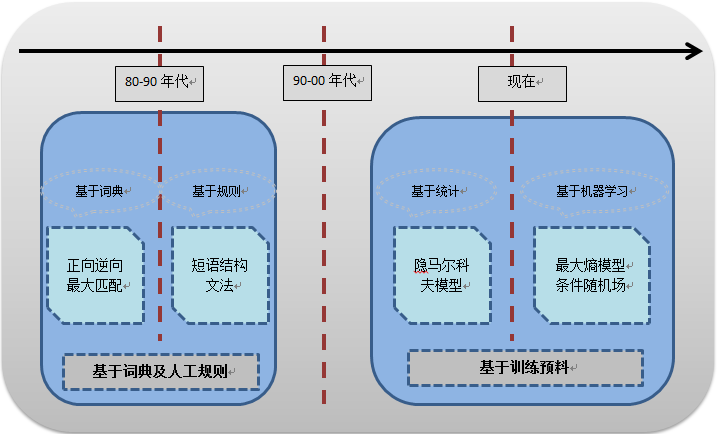
目前中文分詞算法有主要分為四大類:基于詞典的方法�����,基于統計的方法��,基于規則的方法����,基于理解的方法�。下面具體介紹一下這四種方法����。
二��、基于詞典的方法
1.基于詞典的方法�����,或者說是字符串匹配����,機械分詞方法���。
定義:按照一定策略將待分析的字符串與一個“大機器詞典”中的詞條進行匹配���,如果能在詞典中找到某個字符串�,那么就表示匹配成功���,識別該詞���。
2.優缺點分析
優點:簡單����,很容易實現
缺點:
匹配速度較慢
存在交集型和組合型歧義切分問題
詞本身并沒有一個標準的定義����,沒有統一標準的詞集
不同詞典所產生的歧義不同
對于自學習的智能性比較缺乏
3.常見的基于詞典的方法有:
按照掃描方向的不同:正向匹配 & 逆向匹配
按照長度的不同:最大匹配 & 最小匹配
按照是否與詞性標注過程相結合:單純分詞方法 & 分詞與標注相結合
(1)正向最大匹配算法(MM)
從左向右取待切分漢語句的m個字符作為匹配字段���,m為大機器詞典中最長詞條個數
(2)逆向最大匹配算法(RMM)
該算法是正向最大匹配的逆向思維����,匹配不成功����,將匹配字段的最前一個字去掉��,實驗表明�,逆向最大匹配算法要優于正向最大匹配算法�。
(3)雙向最大匹配法(Bi-directction Matching method,BM)
雙向最大匹配法是將正向最大匹配法得到的分詞結果和逆向最大匹配法的到的結果進行比較���,從而決定正確的分詞方法����。
三����、基于規則(基于語義)的分詞方法
這一方法的原理為:模擬人對句子的理解����,以此來達到識別詞的效果���?����;舅枷霝椋赫Z義分析��,句法分析����,也就是通過對句法信息和語義信息來進行文本分詞�。
基于規則(基于語義)的分詞方法能夠自動推理���,并完成對未登錄詞的補充�����。
語義分詞法引入了語義分析�����,能夠對自然語言本身的語言信息作更多的處理�����,例如擴充轉移網絡法���、知識分詞語義分析法��、鄰接約束法���、綜合匹配法�����、后綴分詞法���、特征詞庫法���、矩陣約束法���、語法分析法等�。
四����、基于統計的分詞方法
基于統計的分詞方法指的是:在給定大量已定分詞的文本的前提下�,通過利用統計機器學習模型學習詞語切分的規律(稱為訓練)����,從而實現對未知文本的切分�����。其基本思想為:上下文當中��,相鄰的字同時出現的次數越多�,那么就越可能構成一個詞�。所以字與字相鄰出現的概率或頻率�,可以比較好的反映詞的可信度����。
主要的統計模型有:N元文法模型(N-gram)���,HMM模型(隱馬爾可夫模型Hidden Markov Model �����,)���,最大熵模型(ME)�,條件隨機場模型(Conditional Random Fields�,CRF)等�����。
1.N-gram模型思想
模型基于這樣一種假設����,第n個詞的出現只與前面N-1個詞相關��,而與其它任何詞都不相關���,整句的概率就是各個詞出現概率的乘積��。
2.HMM模型(隱馬爾可夫模型Hidden Markov Model )
根據觀測值序列找到真正的隱藏狀態值序列���。
五���、基于人工智能技術的中文分詞方法(基于理解)
基于人工智能技術的中文分詞方法原理為:在進行分詞的同時��,對句法���、語義也進行分析����,也就是利用句法信息和語義信息對歧義現象進行處理
一般分為三個部分: 分詞子系統����、句法語義子系統和總控部分���。
在總控部分的協調下���,分詞子系統能夠獲得有關詞�����、句子等的句法和語義信息���,并以此來對分詞歧義進行判斷��,也就是說�,它是對人理解句子過程的模擬
基于人工智能技術的中文分詞需要使用大量的語言知識和信息��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
