小編今天跟大家分享的文章是關于python基于主成分分析的客戶信貸評級實戰的�����,大家在學習python過程中要注意理論學習與實際案例操作相結合���,這樣才能更好地掌握�。好了�����,跟小編一起來看具體內容吧��!
文章來源: 早起Python
作者:蘿卜
本文是Python商業數據挖掘實戰的第5篇
前言
大樣本的數據集固然提供了豐富的信息�����,但也在一定程度上增加了問題的復雜性�。如果我們分別對每個指標進行分析�����,往往得到的結論是孤立的�,并不能完全利用數據蘊含的信息�����。但是盲目的去減少我們分析的指標��,又會損失很多有用的信息�����。所以我們需要找到一種合適的方法��,一方面可以減少分析指標��,另一方面盡量減少原指標信息的損失�����。
變量壓縮的方法非常多��,但百法不離其中����,其實最根本的都是「主成分分析」(Primary Component Analysis�,下簡稱PCA)�。能夠理解 PCA 的基本原理并將代碼用于實際的業務案例是本文的目標����,本文將詳細介紹如何利用Python實現基于主成分分析的5c信用評級��,主要分為兩個部分:
引入
在正式開始原理趣析前�����,我們先從兩個生活場景入手����,借以更好的理解需要進行變量壓縮的原因���。
場景1:
上司希望從事數據分析崗位的你僅用兩個短句就概括出以下數據集所反映出的經濟現象

用幾個長句都不一定能夠很好的描述數據集的價值�����,更何況高度凝練的兩個短句�,短短九個指標就已經十分讓人頭疼了��,如果表格再寬一些呢���,比如有二三十個變量����?
場景2
大學生講究德智體美勞全面發展�����,學校打算從某學院挑選一兩名學生外派進修數據分析�,需要綜合全面的考量學生素質���。部分候選學生的個人情況如下:
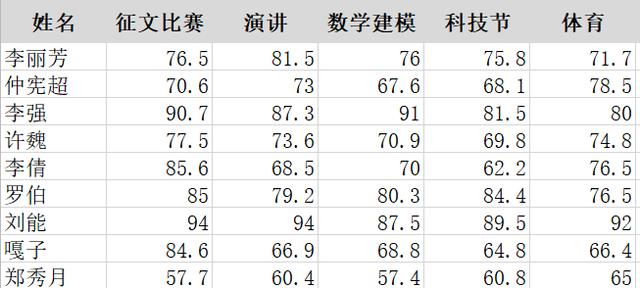
首先還是與場景1類似的問題�����,這些指標只是冰山一角����,還沒算上學生們其他領域的成績���,如果說在場景1中還可以以犧牲全面性來刪除一些我們覺得關系不大的變量�,比如我們猜測老板只會關注GDP與人均GDP這兩個指標�����,那么場景2的背景便已經清晰地說明了需要綜合地考慮變量����,不能有生硬的去掉“體育”之類的操作�����。
信息壓縮
如果把信息壓縮這四個字拆成信息和壓縮這兩部分來看的話��,便會呈現如下值得探究的問題:
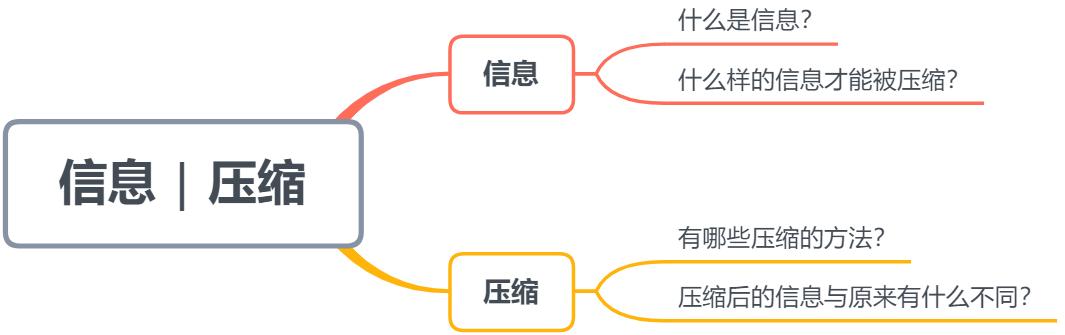
「信息壓縮中的信息指什么�?」
其實各種數據��、變量都可被稱為信息���,而統計學家們常把方差當作信息�����。其實在做描述性統計分析的時候��,只要能夠表現我們數據的變異情況的統計量都可以被稱作信息����,如方差�,極差等�����,只不過是極差會更好計算�。以方差為例�����,方差變化越大�����,數據分布越分散�����,涵蓋的信息就越多�。
「什么樣的信息/變量才能被壓縮�����?」
-
只有相關性強的變量才能被壓縮�。如場景2的數學建模和科技節活動�����,都是學生們理科思維的體現方式����,所以可以考慮把這兩者合并成一個新的叫
“ 理科思維 ” 的變量���,這樣便可以不用兩個變量都要費筆墨描述�����,關鍵是 “ 理科思維 ”
這個新的變量里面數學建模和科技節這兩個舊變量的各自的占比是多少�。(因為這里并沒有因變量��,所以這兩個舊變量的權重系數無法簡單的使用多元線性回歸來完成)如果變量間的關系幾乎是獨立的卻依然強制壓縮(比如體育和演講)�,則會大大加劇信息的缺失程度���,這也是為什么
“ 壓縮 ” 其實帶有一絲迫不得已的意味�����,都是以盡可能損失最少的信息為前提��。
-
主成分分析是只能針對連續變量來進行壓縮���,分類變量則不行���。因為分類變量之間可以說是完全獨立的�,并沒有正負兩種相關性一說�,如性別男和女之間就完全是獨立的�����。如果一定也要將分類變量壓縮的話��,通常會對他們進行WOE轉換(后續推文會提及)�,之后就可以愉快的進行壓縮了��。所以分類變量是沒辦法進行單獨壓縮的��,因為沒有對應的算法�����。有些人可能會直接對分類變量間進行卡方檢驗�����,然后把
p 值大的刪去一些�,這個其實應該被劃分為手工的范疇�,并不屬于算法���。
「有哪些壓縮的方法����?」
總的來說降維有兩種方法��,一種是特征消除���,另一種是特征提取
-
特征消除:如上一問提到的采用卡方檢驗這樣的非算法����,又或者直接拍腦袋決策需要刪掉哪些變量����,但這可能會使我們丟失這些特征中的很多信息��。
-
特征提取:通過組合現有特征來創建新變量��,可以盡量保存特征中存在的信息���。
PCA就是一種常見的特征提取方法�����,它會將關系緊密的變量們用盡可能少的新創建的變量代替��,使這些新變量是兩兩不相關的����。這就實現用較少的綜合指標分別代表存在于各個變量中的各類信息���。所以多元變量壓縮思路的基礎其實是相關分析����。
「壓縮后的信息與原來的有什么不同�����?」
我們需要明確的是��,無論是主成分還是后續推文的稀疏主成分分析�����,都有一個問題:他們得到的主成分均沒有什么業務含義�,如果希望得到的壓縮后的變量是有意義的���,則可以考慮變量聚類����。
壓縮過程
下圖為兩個正態分布的變量間可能存在的三種關系的示意圖�,去正態分布和相關系數為 0.9 是為了從比較理想化的角度來解釋變量壓縮的步驟�。
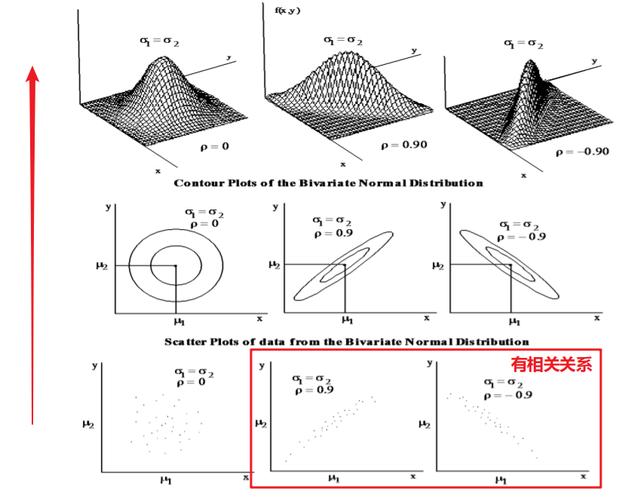
可以看到�,若兩變量間的關系是較強的正/負相關�,用鉛筆把散點圖的范圍圈起來的話呈現的都是一個較扁的橢圓�����;反之��,完全獨立的兩個變量的分布更像是一個肥胖的圓形�。關于壓縮過程我們依舊對以下幾個常見的問題進行解釋����。
「如何通過散點圖理解信息壓縮�����?」
直接看散點圖只能判斷出是否值得壓縮�����,畢竟只有變量間具有一定的相關性才值得壓縮���。接下來將涉及到 PCA 中很重要的一個知識點:坐標軸旋轉
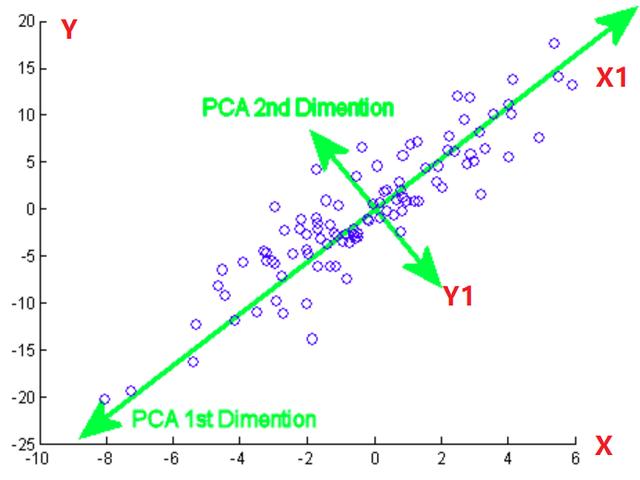
「旋轉坐標軸的作用��?」
旋轉后的坐標軸與原坐標軸一樣��,都是正交(垂直)的�。這樣的旋轉方式可以使兩個相關的變量的信息在坐標軸上得到最充分的體現(如果以極差作為信息����,則點在 X1 的投影范圍最長)�。之后便可從短軸方向來壓縮�,當這個橢圓被壓扁到一定程度時����,短軸上的信息就可以忽略不計���,便達到了信息壓縮的目的�。
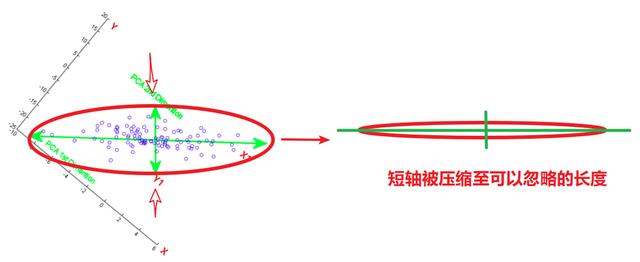
「如果有三個變量該如何壓縮��?」
三維的也是如此�,只不過是由橢圓變成橢球(三個變量都相關)���。步驟還是一樣��,找到最長軸后�����,在軸上做切面��,切面一旦有了����,便又回歸到了二維的情況���。這時可以找到次長軸和最短軸��,這就可以依次的提取�,當我們認為最短軸可以忽略不計的時候�����,就又起到了信息壓縮的作用�����。
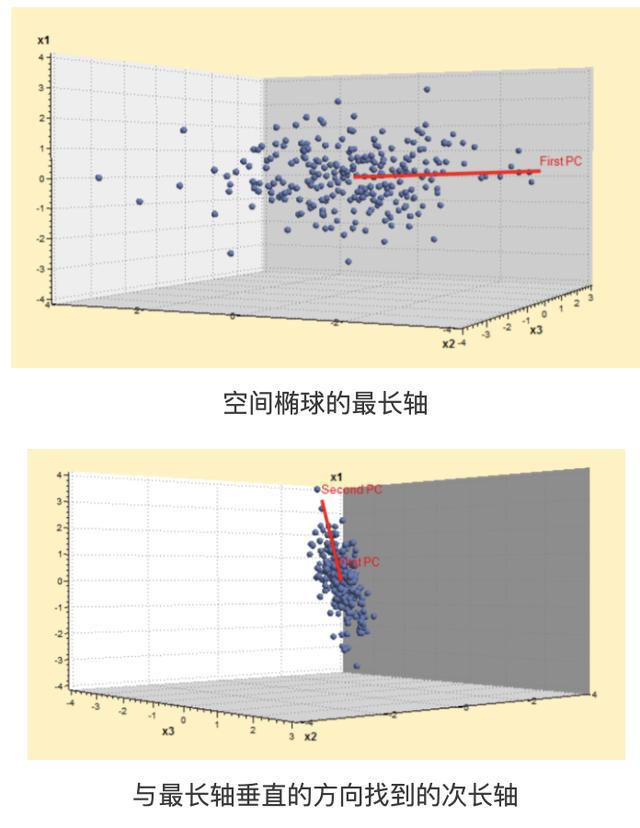
要注意的是如果呈球形分布���,這說明變量間沒有相關關系���,沒有必要做主成分分析�����,也不能做變量的壓縮����。
建模分析
前面已經說到����,PCA后所得到的壓縮的主成分并沒有什么意義�����,比如5個變量壓縮成2個主成分P1和P2����。

這兩個主成分中的組成等式為:
其中��,等式右邊的系數正負與否并沒有什么意義���,通??唇^對值即可�����。第一個主成分 P1中受五個變量的影響程度無明顯差別�����,權重都在0.42 ~ 0.47間 主成分P2受第一個變量的影響最大����,權重系數為0.83����,受第三個變量影響最小����,權重為0.14
那么如何知道應該壓縮成幾個主成分��?PCA 的功能是壓縮信息�����,壓縮后的每個主成分都能夠解釋一部分信息的變異程度(統計學家喜歡用方差表示信息的變異程度)����,所以�,只需要滿足解釋信息的程度達到一定的值即可�����。
-
計算每個成份因子
-
將不同成分因子所能解釋的變異百分比相加 3. 得到的值被稱之為累積變異百分比 4. PCA 過程中���,我們將選擇能使得這個值最接近于 1 的維度個數
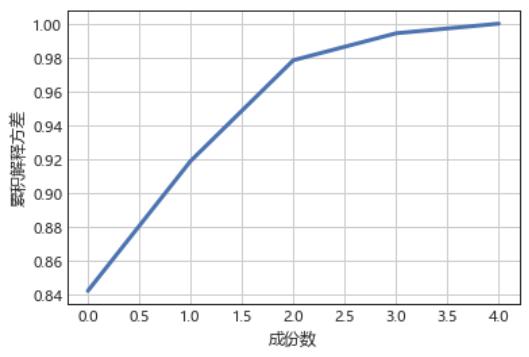
明顯可以看出隨著成分數目的增加�,累積變異百分比逐漸增加����。不建議使得累積百分比等于1����,這將會導致有些主成分帶來冗余信息�,通常等于 0.85
就可以了��。當然我們也可以選擇兩個主成分��,因為當我們增加第三個主成分因子時�,會發現增加它對于累積變異的百分比沒有太大的影響����。
Python實戰
在正式開始 Python 代碼實戰前���,簡要了解主成分分析的運用場景是非常有必要的
-
綜合打分:這種情況在日常中經常遇到����,比如高考成績的加總�、員工績效的總和排名�。這類情況要求只出一個綜合打分����,因此主成分分析比較適合�。相對于講單項成績簡單加總的方法�����,主成分分析會賦予區分度高的單項成績以更高的權重����,分值更合理�。不過當主成分分析不支持只取一個主成分時���,就不能使用該方法了�。
-
數據描述:描述產品情況�����,比如著名的波士頓矩陣��,子公司業務發展狀況���,區域投資潛力等�����,需要將多變量壓縮到少數幾個主成分進行描述��,如果壓縮到兩個主成分是最理想的����。這類分析一般做主成分分析是不充分的�����,做到因子分析更好����。
-
為聚類或回歸等分析提供變量壓縮:消除數據分析中的共線性問題���,消除共線性常用的有三種方法�,分別是:
-
同類變量中保留一個最有代表性的����;
-
保留主成分或因子�����;
-
從業務理解上進行變量修改����。
?
案例背景:某金融服務公司為了了解貸款客戶的信用程度�,評價客戶的信用等級����,采用信用評級常用的5C(品質 Character���,能力
Capacity�����,資本 Capital��,抵押 Collateral�����,條件 Condition)方法�, 說明客戶違約的可能性����。
?
本次實戰將圍繞綜合打分��,即只選出一個主成分的情況來實現客戶信用評級�����。
數據探索
首先導入相關包并進行探索性分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
plt.rc('font', **{'family': 'Microsoft YaHei, SimHei'})
# 設置中文字體的支持
df = pd.read_csv('loan_apply.csv')
df
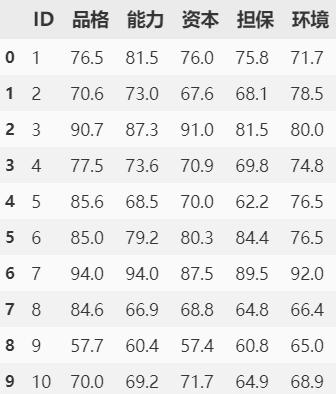
參數解釋:
-
品格:指客戶的名譽�;
-
能力:指客戶的償還能力����;
-
資本:指客戶的財務實力和財務狀況����;
-
擔保:指對申請貸款項擔保的覆蓋程度��;
-
環境:指外部經濟政策環境對客戶的影響
進行主成分分析前����,一定要對數據進行相關分析�,因為相關性較低或獨立的變量不可做PCA
# 求解相關系數矩陣�����,證明做主成分分析的必要性
## 丟棄無用的 ID 列
data = df.drop(columns='ID')
import seaborn as sns
sns.heatmap(data.corr(), annot=True)
# annot=True: 顯示相關系數矩陣的具體數值
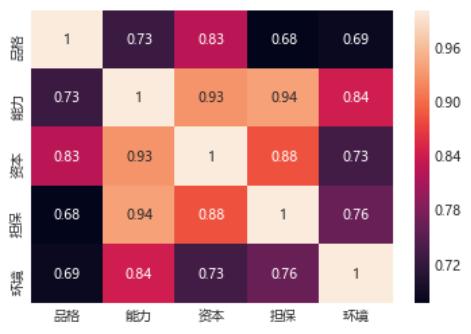
發現變量間相關性都比較高�����,大于0.7�����,有做PCA的必要
PCA 建模前�,數據需要進行標準化�����,通常使用中心標準化���,也就是將變量都轉化成Z分數的形式����,即偏離平均數的標準差個數�,這樣才能防止量綱問題給建模帶來的影響�����。如身高-體重的量綱1.78-59與178-60在散點圖上的顯示會有比較大的區別!
# PCA 通常用中心標準化�,也就是都轉化成 Z 分數的形式
from sklearn.preprocessing import scale
data = scale(data)
使用sklearn進行PCA分析����,注意:
-
第一次的n_components參數最好設置得大一些(保留的主成份)
-
觀察explained_variance_ratio_取值變化�,即每個主成分能夠解釋原始數據變異的百分比
from sklearn.decomposition import PCA
pca = PCA(n_components=5) # 直接與變量個數相同的主成分
pca.fit(data)
結果分析
累計解釋變異程度

明顯看出第一個主成分就已經能夠解釋84%的信息變異程度了!
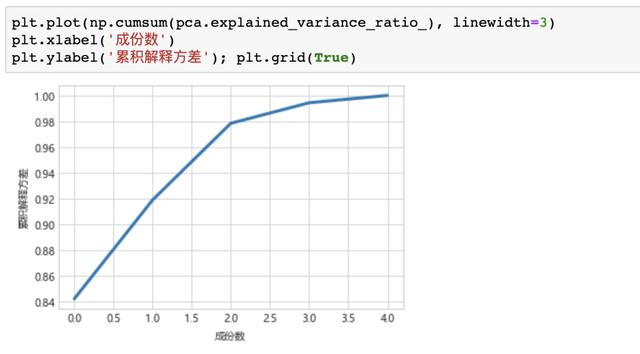
重新建模
重新選擇主成分個數進行建模

主成分中各變量的權重分析
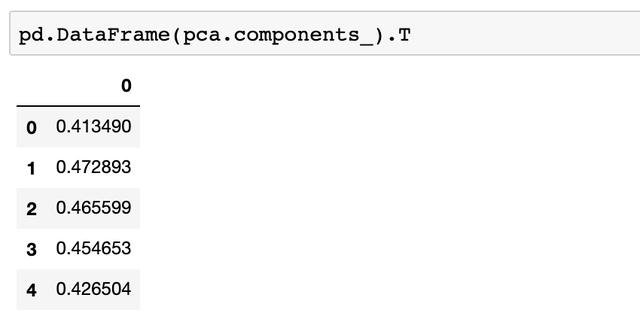
第一個主成分(解釋了84% 的變異的那個)與5個自變量的系數關系可以理解成:「第一主成分 = 0.413 * 品格 + 0.47 * 能力 + 0.46 * 資本 + 0.45 * 擔保 + 0.42 * 環境」���。所以說生成的主成分除降維意義顯著外����,并沒有什么其他的意義�����,并不好解釋�����。
做出決策
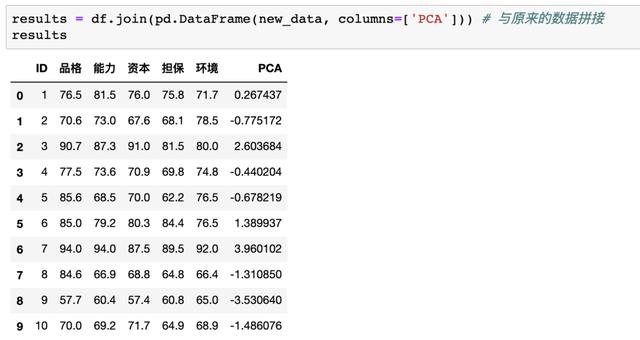
這里的new_data是上文代碼pca.fit_transform(data)生成的降維后的數據����,接著按照綜合打分從高到低進行排序
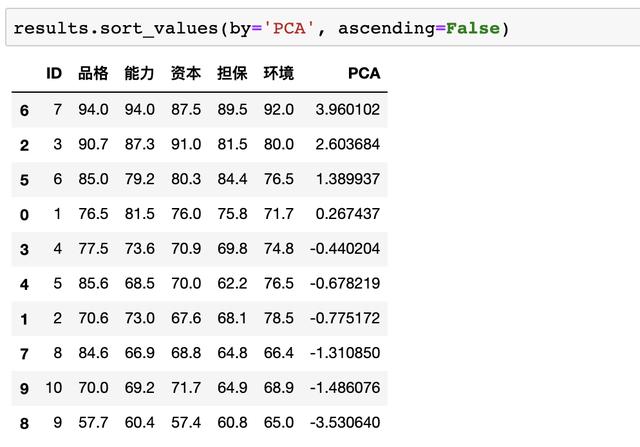
根據結果我們可以發現貸款給7號客戶風險最低���,給9號客戶風險最高�!
小結
本文通過生活實例引出為什么要進行信息的壓縮與提煉���,講解了主成分分析 PCA
的原理與使用時的注意事項����,并使用Python示范了完整的建模流程�����,給讀者提供了參考和借鑒����。另外����,作為數據分析師必會的PCA在圖像處理如人臉識別和手寫數字識別等機器學習領域也有很廣的運用���,值得好好琢磨并熟練掌握���。











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
