seaborn是一款基于matplotlib的圖形可視化python庫�����,它提供了一種高度交互式界面��,便于用戶能夠做出各種有吸引力的統計圖表��。seaborn主要是針對統計繪圖的��,一般來說�,seaborn能滿足數據分析90%的繪圖需求���,它最大的特點是簡單�����。小編今天給大家分享的就是關于如何使用seaborn繪圖的內容���,希望對大家有所幫助�����。
一����、常用參數

二�����、seaborn-數據集分布可視化
1.單變量分布
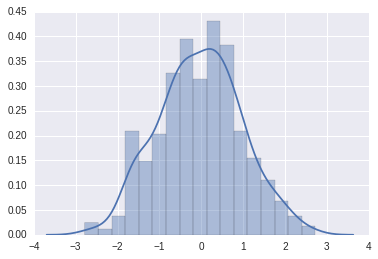
# 正態分布的500個數據
x1 = np.random.normal(size=500)
# 分布圖���,默認是直方+線型
sns.distplot(x1);
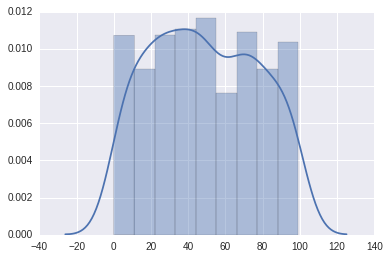
# 均勻分布的500個整數數據
x2 = np.random.randint(0, 100, 500)
# 分布圖�,默認是直方+線型
sns.distplot(x2);
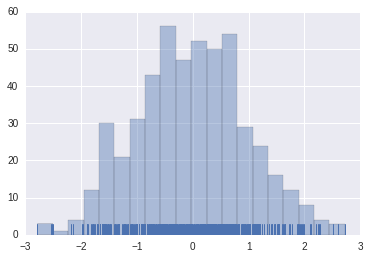
# 分布圖����,bin是直方的個數����,kde是線型(false表示去掉線型)��,rug顯示每個數據的分布(下面深藍色的部分)
sns.distplot(x1, bins=20, kde=False, rug=True)
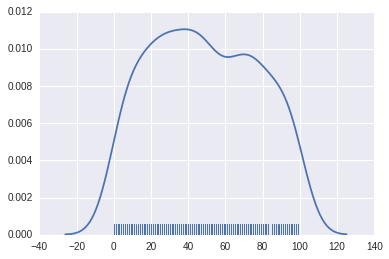
# 核密度估計�����,hist表示直方(false表示不要直方)
sns.distplot(x2, hist=False, rug=True)
# 核密度函數也可以表示成如下�,shade表示陰影
sns.kdeplot(x2, shade=True)
sns.rugplot(x2)
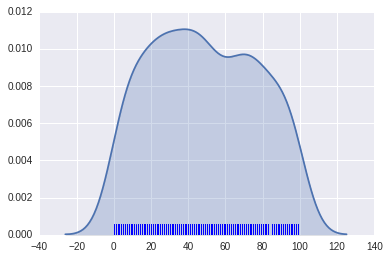
# 擬合參數分布
sns.distplot(x1, kde=False, fit=stats.gamma)
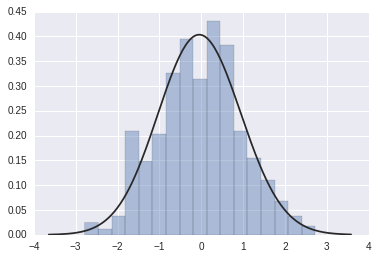
2.雙變量分布
# 雙變量分布
df_obj1 = pd.DataFrame({"x": np.random.randn(500),
"y": np.random.randn(500)})
df_obj2 = pd.DataFrame({"x": np.random.randn(500),
"y": np.random.randint(0, 100, 500)})
# print df_obj1
# print df_obj2
# 散布圖
sns.jointplot(x="x", y="y", data=df_obj2)
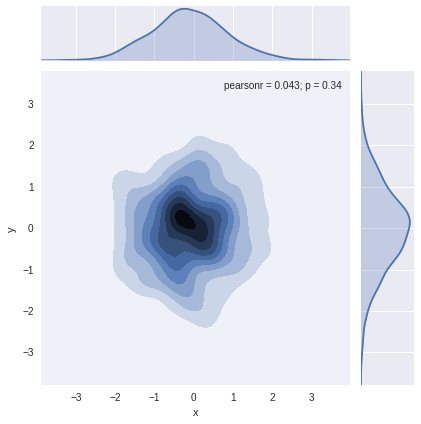
# 二維直方圖
sns.jointplot(x="x", y="y", data=df_obj2, kind="hex");

# 核密度估計
sns.jointplot(x="x", y="y", data=df_obj1, kind="kde");
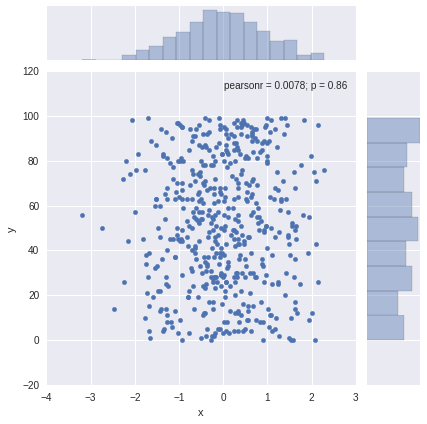
3.數據集中變量間關系可視化
# 數據集中變量間關系可視化
dataset = sns.load_dataset("tips")
#dataset = sns.load_dataset("iris")
sns.pairplot(dataset);
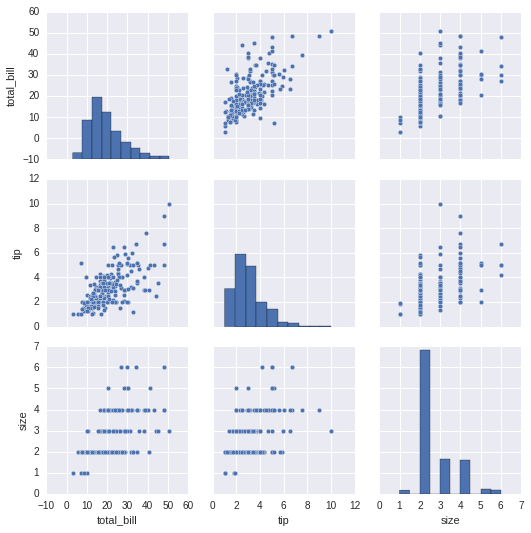
以上就是小編今天跟大家分享的關于seaborn繪圖的一些內容�����,希望對于大家seaborn的學習和使用有所幫助��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
