一�、sparkSQL簡介
1.sparkSQL定義
sparkSQL是Spark用來處理結構化數據的一個模塊�,它提供了一個編程抽象叫做DataFrame并且作為分布式SQL查詢引擎的作用���。
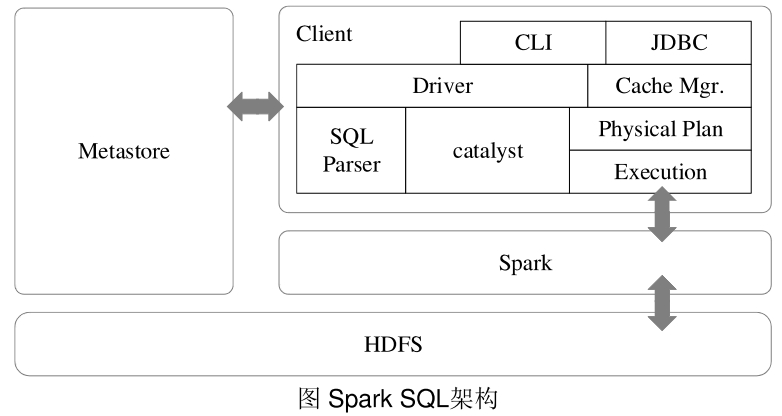
2.sparkSQL來源
要想了解sparkSQL來源���,必須要知道Shark���。
Shark也就是Hive on Spark�����,Shark在HiveQL方面重用了Hive里HiveQL的解析�����、邏輯執行計劃�����、翻譯執行計劃優化等邏輯�����,通過Hive中HiveQL解析���,把HiveQL翻譯成Spark上的RDD操作��。Shark的設計導致了兩個問題:
(1)執行計劃優化完全依賴于Hive�����,對于添加新的優化策略很是不便;
(2)Spark是線程級并行�����,而MapReduce是進程級并行���。Spark在兼容Hive的實現上存在線程安全問題�����,因而使得Shark必須使用另外一套獨立維護的打了補丁的Hive源碼分支;
Spark團隊在汲取了shark的優點基礎上�,重新設計了sparkSQL�,使sparkSQL在數據兼容�����、性能優化����、組件擴展等方面有很大的提升
二���、sparkSQL特點
1.數據兼容:支持從Hive表���、外部數據庫(JDBC)����、RDD����、Parquet 文件�����、以及JSON 文件中獲取數據;
2.組件擴展:SQL 語法解析器����、分析器���、優化器都能夠重新定義;
3.性能優化:內存列存儲��、動態字節碼生成等優化技術����,內存緩存數據;
4.多語言支持:Scala�����、Java��、Python;
三���、 DataFrame
1.DataFrame讓Spark具備了處理大規模結構化數據的能力�,比起原有的RDD轉化方式�,更加簡單易用��,而且計算能力也有顯著提高���。
RDD是分布式的Java對象的集合�,但是�,RDD對于對象內部結構并不可知�����。
DataFrame是一種以RDD為基礎的分布式數據集�,提供了詳細的結構信息�。
Spark能夠輕松實現從MySQL到DataFrame的轉化�����,并且支持SQL查詢���。
2.創建DataFrame
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().getOrCreate()
//是支持RDDs轉換為DataFrames及后續sql操作
import spark.implictis._
val df = spark.read.json("file://usr/local/spark/examples/src/main/resources/people.json")
df.show()
//打印模式信息
df.printSchema()
df.select(df("name"), df("age")+1).show()
//分組聚合
df.groupBy("age").count().show()
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
