
作者:馬立和 高振嬌 韓鋒
來源:大數據DT(ID:hzdashuju)
內容摘編自《數據庫高效優化:架構��、規范與SQL技巧》
案例01 一條SQL引發的“血案”
1. 案例說明
某大型電商公司數據倉庫系統����,正常情況下每天0~9點會執行大量作業���,生成前一天的業務報表���,供管理層分析使用�����。但某天早晨6點開始�,監控人員就頻繁收到業務報警�,大批業務報表突然出現大面積延遲�����。原本8點前就應跑出的報表��,一直持續到10點仍然沒有結果�����。公司領導非常重視�����,嚴令在11點前必須解決問題����。
DBA緊急介入處理�����,通過TOP命令查看到某個進程占用了大量資源���,殺掉后不久還會再次出現����。經與開發人員溝通����,這是由于調度機制所致�����,非正常結束的作業會反復執行����。
暫時設置該作業無效���,并從腳本中排查可疑SQL��。同時對比從線上收集的ASH/AWR報告��,最終定位到某條SQL比較可疑�。
經與開發人員確認系一新增功能�,因上線緊急��,只做了簡單的功能測試��。正是因為這一條SQL��,導致整個系統運行緩慢����,大量作業受到影響����,修改SQL后系統恢復正常��。
這是一個很典型的兩表關聯語句�,兩張表的數據量都較大��。下面來看看執行計劃����,如圖1-1所示���。
執行計劃觸目驚心��,優化器評估返回的數據量為3505T條記錄���,計劃返回量127P字節��,總成本9890G�,返回時間999:59:59�����。

從執行計劃中可見����,兩表關聯使用了笛卡兒積的關聯方式����。我們知道笛卡兒連接是指兩表沒有任何條件限制的連接查詢�。一般情況下應盡量避免笛卡兒積���,除非某些特殊場合��,否則再強大的數據庫也無法處理���。
這是一個典型的多表關聯缺乏連接條件���,導致笛卡兒積����,引發性能問題的案例��。
2. 給我們的啟示
從案例本身來講并沒有什么特別之處�����,不過是開發人員疏忽導致了一條質量很差的SQL�����。但從更深層次來講�����,這個案例可以給我們帶來如下啟示�����。
-
開發人員的一個疏忽造成了嚴重的后果���,原來數據庫竟是如此的脆弱��。需要對數據庫保持“敬畏”之心���。
-
電腦不是人腦���,它不知道你的需求是什么�����,只能根據寫好的邏輯進行處理��。
-
不要去責怪開發人員�����,誰都會犯錯誤���,關鍵是如何從制度上保證不再發生類似的問題�。
3. 解決之道
1)SQL開發規范
加強對數據庫開發人員的培訓工作����,提高其對數據庫的理解能力和SQL開發水平���。將部分SQL運行檢查的職責前置��,在開發階段就能規避很多問題��。要向開發人員灌輸SQL優化的思想���,在工作中逐步積累��,這樣才能提高公司整體開發質量�����,也可以避免很多低級錯誤���。
2)SQL Review制度
對于SQL Review��,怎么強調都不過分����。從業內來看����,很多公司也都在自己的開發流程中納入了這個環節�,甚至列入考評范圍���,對其重視程度可見一斑��。其常見典型做法是利用SQL分析引擎(商用或自研)進行分析或采取半人工的方式進行審核�����。審核后的結果可作為持續改進的依據�����。
SQL Review的中間結果可以保留�����,作為系統上線后的對比分析依據�,進而可將SQL的審核��、優化�����、管理等功能集成起來�����,完成對SQL整個生命周期的管理�����。
3)限流/資源控制
有些數據庫提供了豐富的資源限制功能���,可以從多個維度限制會話對資源(CPU��、MEMORY���、IO)的使用�,可避免發生單個會話影響整個數據庫的運行狀態����。
對于一些開源數據庫����,部分技術實力較強的公司還通過對內核的修改實現了限流功能���,控制資源消耗較多的SQL運行數量�,從而避免拖慢數據庫的整體運行�����。
案例02 糟糕的結構設計帶來的問題
1. 案例說明
這是某公司后臺的ERP系統�����,系統已經上線運行了10多年��。隨著時間的推移�,累積的數據量越來越大�����。隨著公司業務量的不斷增加��,數據庫系統運行緩慢的問題日益凸顯�。
為提高運行效率����,公司計劃有針對性地對部分大表進行數據清理����。在DBA對某個大表進行清理時出現了問題����。這個表本身有數百吉字節����,按照指定的清理規則只需要根據主鍵字段范圍(運算符為>=)選擇出一定比例(不超過10%)的數據進行清理即可�。
但在實際使用中發現�����,該SQL是全表掃描��,執行時間大大超出預期��。DBA嘗試使用強制指定索引方式清理數據�����,依然無效����,整個SQL語句的執行效率達不到要求�����。為了避免影響正常業務運行����,不得不將此次清理工作放在半夜進行�,還需要協調庫房等諸多單位進行配合�����,嚴重影響正常業務運行���。
為了盡量減少對業務的影響����,DBA求助筆者幫助協同分析����。這套ERP系統是由第三方公司開發的���,歷史很久遠����,相關的數據字典等信息都已經找不到了���,只能從純數據庫的角度進行分析����。這是一個普通表(非分區表)�,按照主鍵字段的范圍查詢一批記錄并進行清理���。
按照正常理解��,執行索引范圍掃描應該是效率較高的一種處理方式�,但實際情況都是全表掃描���。進一步分析發現�,該表的主鍵是沒有業務含義的��,僅僅是自增長的數據���,其來源是一個序列����。
但奇怪的是�,這個主鍵字段的類型是變長文本類型��,而不是通常的數字類型�。當初定義該字段類型的依據��,現在已經無從考證�,但實驗表明正是這個字段的類型“異?!?���,導致了錯誤的執行路徑�����。
下面通過一個實驗重現這個問題����。
1)數據準備
兩個表的數據類型相似(只是ID字段類型不同)�����,各插入了320萬數據�,ID字段范圍為1~3200000�����。
2)模擬場景
相關代碼如下:
對于普通的采用數值類型的字段�,范圍查詢就是正常的索引范圍掃描�����,執行效率很高���。
對于文本類型字段的表�����,范圍查詢就是對應的全表掃描��,效率較低是顯而易見的��。
3)分析結論
-
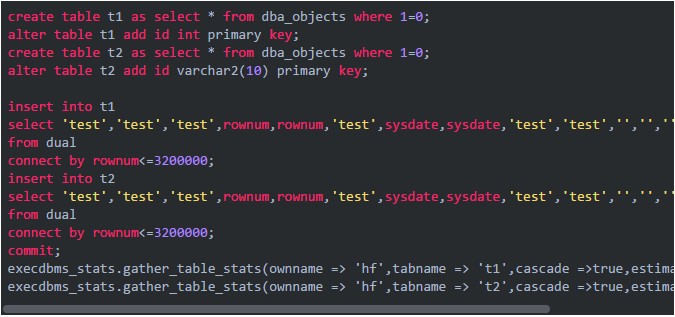
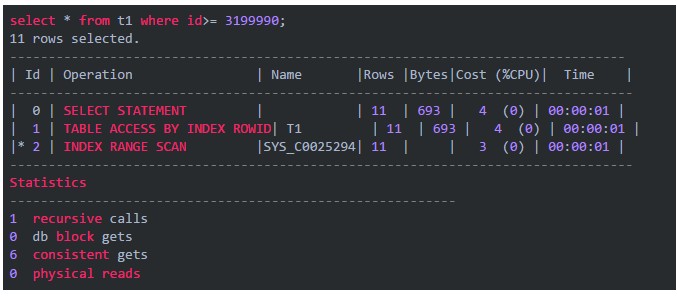
字符類型在索引中是“亂序”的��,這是因為字符類型的排序方式與我們的預期不同���。從“select * from t2 where id>= '3199990'”執行返回755 565條記錄可見����,不是直觀上的10條記錄����。這也是當初在做表設計時�����,開發人員沒有注意的問題�。
-
字符類型還導致了聚簇因子很大���,原因是插入順序與排序順序不同��。詳細點說�����,就是按照數字類型插入(1..3200000)��,按字符類型('1'...'32000000')t排序�����。
select table_name,index_name,leaf_blocks,num_rows,clustering_factor from user_indexes where table_name in ('T1','T2');
TABLE_NAME INDEX_NAME LEAF_BLOCKS NUM_ROWS CLUSTERING_FACTOR -------------- -------------- ---------------- ---------- --------------------- T1 SYS_C0025294 6275 3200000 31520
T2 SYS_C0025295 13271 3200000 632615
-
在對字符類型使用大于運算符時�,會導致優化器認為需要掃描索引大部分數據且聚簇因子很大�����,最終導致棄用索引掃描而改用全表掃描方式��。
4)解決方法
具體的解決方法如下:
select * from t2 where id between '3199990' and '3200000'; -------------------------------------------------------------------------------- | Id | Operation | Name |Rows|Bytes |Cost(%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 6| 390 | 5 (0)|00:00:01|
| 1 | TABLE ACCESS BY INDEX ROWID| T2 | 6| 390 | 5 (0)|00:00:01|
|* 2 | INDEX RANGE SCAN | SYS_C0025295 | 6| | 3 (0)|00:00:01| -------------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 13 consistent gets 0 physical reads
將SQL語句由開放區間掃描(>=)�����,修改為封閉區間(between xxx and max_value)�。使得數據在索引局部順序是“對的”�����。如果采用這種方式仍然走全表掃描����,還可以進一步細化分段或者采用“逐條提取+批綁定”的方法��。
2. 給我們的啟示
這是一個典型的由不好的數據類型帶來的執行計劃異常的例子�。它給我們帶來如下啟示:
-
糟糕的數據結構設計往往是致命的����,后期的優化只是補救措施��。只有從源頭上加以杜絕�����,才是優化的根本�����。
-
在設計初期能引入數據庫審核��,可以起到很好的作用�����。
案例03 規范SQL寫法好處多
1. 案例說明
某大型電商公司數據倉庫系統�,開發人員反映作業運行緩慢�。經檢查是一個新增業務中某條SQL語句導致�����。經分析是非標準的SQL引起優化器判斷異常�,將其修改成標準寫法后��,SQL恢復正常���。
1)具體分析
看下面的代碼:
select ... from ... where (
(
order_creation_date>= to_date(20120208,'yyyy-mm-dd') and
order_creation_date<to_date(20120209,'yyyy-mm-dd')
) or (
send_date>= to_date(20120208,'yyyy-mm-dd') and send_date<to_date(20120209, 'yyyy-mm-dd')
)
)
andnvl(a.bd_id,0) = 1 -------------------------------------------------------------------------------- | Id | Operation | Name |Cost (%CPU)| Time |Pstart | Pstop | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 2470K(100)| | | |
| 1 | SORT GROUP BY | | | | | |
| 2 | TABLE ACCESS BY GLOBAL INDEX ROWID | XXXX | 5 (0) | 00:00:01 | ROW L | ROW L |
| 3 | NESTED LOOPS | | 2470K (1) | 08:14:11 | | |
| 4 | VIEW |VW_NSO_1| 2470K (1) | 08:14:10 | | |
| 5 | FILTER | | | | | |
| 6 | HASH GROUP BY | | 2470K (1)| 08:14:10 | | |
| 7 | TABLE ACCESS BY GLOBAL INDEX ROWID
| XXXX | 5 (0)| 00:00:01 | ROW L | ROW L |
| 8 | NESTED LOOPS | | 2470K (1)| 08:14:10 | | |
| 9 | SORT UNIQUE | | 2340K (2)| 07:48:11 | | |
| 10 | PARTITION RANGE ALL
| | 2340K (2)| 07:48:11 | 1 | 92 |
| 11 | TABLE ACCESS FULL | XXXX | 2340K (2)| 07:48:11 | 1 | 92 |
| 12 | INDEX RANGE SCAN
| XXXX | 3 (0)| 00:00:01 | | |
| 13 | INDEX RANGE SCAN | XXXX | 3 (0)| 00:00:01 | | | --------------------------------------------------------------------------------
這個SQL中涉及的主要表是一個分區表��,從執行計劃(Pstart�、Pstop)中可見�����,掃描了所有分區�,分區裁剪特性沒有起效�����。
2)解決方法
見下面的代碼:
select ... from ... where
order_creation_date >= to_date(20120208,'yyyy-mm-dd') and
order_creation_date<to_date(20120209,'yyyy-mm-dd') union all select ... from ... where send_date>= to_date(20120208,'yyyy-mm-dd') and
send_date<to_date(20120209,'yyyy-mm-dd') and
nvl(a.bd_id,0) = 5
嘗試通過引入union all來分解查詢��,以便于優化器做出更準確的判斷��。采用這個方法后�����,確實起效了��,當然不可避免會掃描兩遍表����。
select ... from ... where (
(
order_creation_date>= to_date(20120208,'yyyymmdd') and
order_creation_date<to_date(20120209,'yyyymmdd')
) or (
send_date>= to_date(20120208,'yyyymmdd') and
send_date<to_date(20120209,'yyyymmdd')
)
); -------------------------------------------------------------------------------- | Id | Operation | Name | Cost(%CPU)|Time | Pstart | Pstop | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 42358 (1)| 00:08:29 | | |
| 1 | SORT AGGREGATE | | | | | |
| 2 | CONCATENATION | | | | | |
| 3 | PARTITION RANGE SINGLE
| | 17393 (1)| 00:03:29 | 57 | 57 |
|* 4 | TABLE ACCESS FULL | XXXX | 17393 (1)| 00:03:29 | 57 | 57 |
|* 5 | TABLE ACCESS BY GLOBAL INDEX ROWID
| XXXX | 24966 (1)| 00:05:00 | ROWID | ROWID |
|* 6 | INDEX RANGE SCAN
| XXXX | 658 (1)| 00:00:08 | | | ---------------------------------------------------------------------------------
通過調整日期FORMAT格式�����,優化器很精準地判斷了分區(Pstart=57��、Pstop=57)��,整體SQL性能得到了很大的提高��,作業運行時間從8個多小時縮減到8分鐘���。
3)分析結論
對于非標準的日期格式���,Oracle在復雜邏輯判斷的情況下分區裁剪特性無法識別�,不起作用�。這種情況下��,會走全表掃描���,結果是正確的����,但是執行效率會很低��。通過使用union all����,簡化了條件判斷��。使得Oracle在非保準日期格式下也能使用分區裁剪特性����,但最佳修改方式還是規范SQL的寫法�����。
2. 給我們的啟示
-
規范的SQL寫法���,不但利于提高代碼可讀性�����,還有利于優化器生成更優的執行計劃�����。
-
分區功能是Oracle應對大數據的利器�����,但在使用中要注意是否真正會用到分區特性���;否則���,可能適得其反�,使用分區會導致效率更差���。
案例04 “月底難過”
1. 案例說明
某大型電商公司數據倉庫系統經常出現在月底運行緩慢的情況�����,但在平時系統運行卻非常正常�。這是因為月底往往有月報等大批量作業運行��,而就在這個時間點上�,常常會出現緩慢情況���,所以業務人員一到月底就非常緊張��。這也成了一個老大難問題����,困擾了很長時間����。
DBA介入處理��,發現一個很奇怪的現象:某條主要SQL是造成執行緩慢的主因��,其執行計劃是不確定的��,也就是說因為執行計劃的改變�����,導致其運行效率不同�。而往往較差的執行計劃發生在月底幾天���,且由于月底大批作業的影響�,整體性能比較飽和����,更突顯了這個問題�����。
針對某個出現問題的時間段做了進一步分析���,結果表明是由于統計信息的缺失導致了優化器產生了較差的執行計劃���,并據此指定了人工策略��,徹底解決了這個問題���。
1)具體分析
先來看下面的代碼:
select... from xxx a join xxx b on a.order_id = b.lyywzdid left join xxx c on b.gysid = c.gysid
whereb.cdate>= to_date('2012-03-31', 'yyyy-mm-dd') – 3 and ...
a.send_date>= to_date('2012-03-31', 'yyyy-mm-dd') - 1 and
a.send_date<to_date('2012-03-31', 'yyyy-mm-dd'); -------------------------------------------------------------------------------- |Id | Operation |Name | Rows | Bytes | Cost (%CPU) |Pstart|Pstop| -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 104 | 9743(1)| | |
| 1 | HASH JOIN OUTER | | 1 | 104 | 9743(1)| | |
| 2 | TABLE ACCESS BY LOCAL INDEX ROWID | XXXX | 1 | 22 | 0(0)| 1189 | 1189|
| 3 | NESTED LOOPS | | 1 | 94 | 9739(1)| | |
| 4 | PARTITION RANGE ITERATOR
| | 1032 | 74304 | 9739(1)| 123 | 518 |
| 5 | TABLE ACCESS FULL
| XXXX | 1032 | 74304 | 9739(1)| 123 | 518 |
| 6 | PARTITION RANGE SINGLE
| | 1 | | 0(0)| 1189 | 1189 |
| 7 | INDEX RANGE SCAN
| XXXX | 1 | | 0(0)| 1189 | 1189 |
| 8 | TABLE ACCESS FULL | XXXX | 183 | 1830 | 3(0)| | | --------------------------------------------------------------------------------
執行計劃中��,多表關聯使用了嵌套循環����,這點對于OLAP系統來說是比較少見的���。一般優化器更傾向于使用SM和HJ���。進一步檢查發現其成本竟然是0��,怪不得優化器使用了嵌套循環�。
2)深入分析
檢查發現索引數據統計信息異常���,這是分區索引��,僅兩天的分區統計信息都是0��。導致優化器認為嵌套循環的執行效率更高����,而不是使用哈希連接�。結合業務發現�����,月底是業務高峰期��,對于系統統計信息的作業收集����,在指定的時間窗口內無法完成���。最后導致統計信息不完整�,優化器采用了錯誤的執行計劃���。
3)解決方法
解決的代碼如下:
exec dbms_stats.gather_index_stats(
ownname=>'xxx',
indname=>'xxx',
partname=>'PART_xxx',
estimate_percent => 10);
分析完對象的統計信息即恢復正常�����。
2. 給我們的啟示
-
統計信息是優化器優化的重要參考依據����,一個完整�����、準確的統計信息是必要條件����。往往在優化過程中��,第一步就是查看相關對象的統計信息��。
-
分區機制是Oracle針對大數據的重要解決手段�,但也很容易造成所謂“放大效應”����。即對于普通表而言���,統計信息更新不及時可能不會導致執行計劃偏差過大�;但對于分區表����、索引來說����,很容易出現因更新不及時出現0的情況���,進而導致執行計劃產生嚴重偏差��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;












 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
