離群值的判斷與處理
我們在數據分析的時候�����,經常會碰到某些數據遠遠大于或小于其他數據���,這些明顯偏離的數據就是離群值���,也叫奇異值��、極端值����。
離群值產生的原因大致有兩點:
1.總體固有變異的極端表現���,這是真實而正常的數據��,只是在這次實驗中表現的有些極端�,這類離群值與其余觀測值屬于同一總體���。
2.由于試驗條件和實驗方法的偶然性�,或觀測��、記錄�����、計算時的失誤所產生的結果��,是一種非正常的�����、錯誤的數據����,這些數據與其余觀測值不屬于同一總體���。
由于數據的分布不同���,判斷離群值的方法也有所差別��,在此只介紹國標GB/T4883-2008對于正態分布情況下的離群值判斷方法��,其他分布情況下����,我還沒有找到相關資料�。
對于離群值���,國標也有一些概念定義:
1.檢出水平
為檢驗出離群值而指定的統計檢驗的顯著性水平��,和大多數檢驗一樣���,α一般為0.05
2.剔除水平
為檢驗出離群值是否為高度離群值而指定的統計檢驗的顯著性水平���,剔除水平α*不應超過檢出水平α����,通常為0.01����,個人認為這個剔除水平就是判斷該離群值是否需要實際剔除��,也就是說該離群值有可能是第二類原因產生的非正常樣本數據�。
3.統計離群值
在剔除水平下統計檢驗為顯著的離群值
4.歧離值
在檢出水平下顯著�,而在剔除水平下不顯著的離群值�����。
================================================
正態分布情況下的離群值判斷方法��,大致可分為兩類:可以檢驗剔除水平和不可檢驗剔除水平
一�����、可檢驗剔除水平
1.總體標準差已知時�����,奈爾檢驗法
對樣本數據按從小到大順序排序��,
如懷疑最大值X(n)為最大值��,則計算統計量Rn

確定檢出水平α��,查奈爾系數表(見國標GB/T4883-2008)����,得出臨界值
當Rn>R1-α(n)時��,判定X(n)為離群值�,否則不能判定
確定剔除水平α*����,查奈爾系數表(見國標GB/T4883-2008)�,得出臨界值
當Rn>R1-α*(n)時���,判定X(n)為統計離群值��,否則不能判定
如懷疑最小值X(1)為最大值��,則計算統計量Rn'
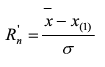
確定檢出水平α����,查奈爾系數表(見國標GB/T4883-2008)��,得出臨界值
當Rn'>R1-α(n)時����,判定X(1)為離群值��,否則不能判定
確定剔除水平α*�,查奈爾系數表(見國標GB/T4883-2008)���,得出臨界值
當Rn'>R1-α*(n)時����,判定X(1)為統計離群值�,否則不能判定
2.總體標準差未知時�����,格拉布斯檢驗法
對樣本數據按從小到大順序排序��,然后計算樣本均值和樣本標準差s
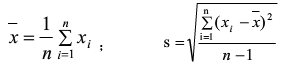
如懷疑最大值X(n)為最大值�����,計算統計量Gn
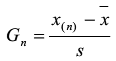
確定檢出水平α�����,查出格拉布斯系數表(見國標GB/T4883-2008)�,得出臨界值
當Gn>G1-α(n)時����,判定X(n)為離群值�����,否則不能判定
確定剔除水平α*�,查出格拉布斯系數表(見國標GB/T4883-2008)��,得出臨界值
當Gn>G1-α*(n)時����,判定X(n)為統計離群值����,否則不能判定
如懷疑最小值X(1)為最大值�����,則計算統計量Gn'
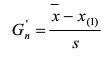
確定檢出水平α����,查出格拉布斯系數表(見國標GB/T4883-2008)���,得出臨界值
當Gn'>G1-α(n)時�����,判定X(1)為離群值��,否則不能判定
確定剔除水平α*�����,查出格拉布斯系數表(見國標GB/T4883-2008)����,得出臨界值
當Gn'>G1-α*(n)時�,判定X(1)為統計離群值�����,否則不能判定
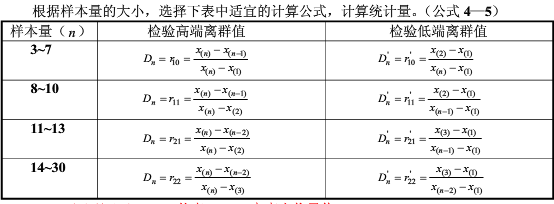
3.總體標準差未知時����,狄克遜(Dixon)檢驗法
對樣本數據按從小到大順序排序
樣本量n在3-30時
計算統計量
樣本量n在30-100時
計算統計量

確定檢出水平α���,查狄克遜系數表(見國標GB/T4883-2008)�,得出臨界值
當Dn>D1-α(n)時�,判定高端值X(n)為離群值��,否則不能判定
當Dn'>D1-α*(n)時����,判定低端值X(1)為離群值����,否則不能判定
4.總體標準差未知時�,偏度-峰度檢驗法
我們知道峰度和偏度是判斷數據是否為正態分布的指標���,而離群值則明顯偏離樣本主體�����,因此我們也可以使用偏度-峰度檢驗法來判斷離群值
單側情形——偏度檢驗法
當離群值處于高端或低端一側時���,可使用偏度檢驗法判斷���,首先構造偏度統計量bs
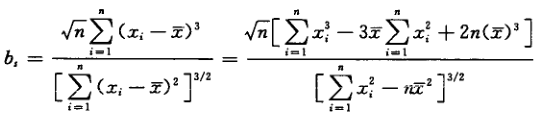
確定檢出水平α����,查偏度檢驗系數表(見國標GB/T4883-2008)��,得出臨界值
當bs>b1-α(n)時�,判定高端值X(n)為離群值��,否則不能判定
當bs'>b1-α(n)時���,判定低端值X(1)為離群值��,否則不能判定
確定剔除水平α*����,查偏度系數表(見國標GB/T4883-2008)����,得出臨界值
當bs>b1-α*(n)時��,判定高端值X(n)為統計離群值����,否則不能判定
當bs'>b1-α*(n)時�,判定低端值X(1)為統計離群值���,否則不能判定
雙側情形——峰度檢驗法
當高端�、低端兩側都可能出現離群值時�����,可使用峰度檢驗法判斷�,首先構造峰度統計量bk

確定檢出水平α����,查峰度檢驗系數表(見國標GB/T4883-2008)���,得出臨界值
當bk>b'1-α(n)時����,判定離均值最遠的觀測值為離群值�����,否則判定未發現離群值
確定剔除水平α*��,查峰度系數表(見國標GB/T4883-2008)�,得出臨界值
當bk>b'1-α*(n)時�,判定離均值最遠的觀測值為統計離群值����,否則未發現統計離群值����。
二���、不可檢驗剔除水平
1.觀察法
根據直方圖或四分位圖進行判斷����,現在很多統計軟件在繪制這兩種圖時���,都會將離群值特殊標記�����,一般認為在均值±3倍標準差以外都屬于離群值���,高出四分位距兩倍以上也屬于離群值�����。
2.萊伊達法
又稱為3σ準則��,在已知總體標準差的情況下使用σ進行判斷�����,但是實際上總體標準差往往未知�,因此常使用樣本標準差s替代σ����,以樣本均值替代真值�,具體為
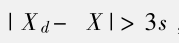
Xd是疑似離群值�����,X為均值
如果疑似離群值與均值的差值大于三倍標準差���,則可認為該值為離群值���。
3.肖維特法
統計量
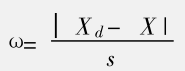
如果計算出的ω值大于肖維特系數表中相應測定次數n時的值��,則可認為該值為異常值
3.羅曼諾夫斯基檢驗法
又稱t檢驗���,首先將疑似離群值剔除�����,然后計算剔除后的均值和標準差

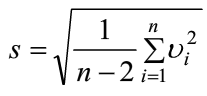
根據測量次數n和顯著性水平α���,進行t檢驗�,得出系數k���,如果

則認為xj為離群值
4.4d檢驗法



5.中位數與算數平均值比較判斷法
我們知道中位數居于一組數據中間的數�����,而均值則可認為是一組數字的“重心”或“平衡點”�,當二者相等的時候�����,可認為這組數字是絕對平衡�、沒有離群值的����,我們可以據此進行判斷�,當二者相差較大時���,表面該組數據可能存在離群值�����,將疑似離群值剔除之后�����,再計算均值和中位數����,如果二者相差變小����,則可認為被剔除值是離群值�����。
======================================
數據分析師們:判斷離群值方法的選擇與應注意的問題
1.合理選擇離群值的判斷方法
離群值的判斷方法很多��,實際中到底選用哪一個����,需根據對測量要求的精準度和測量次數多少來綜合確定�,一般情況下��,測量次數多于30�,或大于10次且只做粗略判斷時�,使用萊伊達法即可�;判斷精度要求不高���,但要求快捷方便時�����,可以選用4d和中位數與算數平均數比較法��。實際上�,對于不用查表的方法大都比較便捷����,但是代價是精度不夠�,且無法檢驗剔除水平���,相反一些需要借助查表的方法精度較高但是計算復雜�,各有利弊�����。
2.準確找出離群值
一般情況下����,測量列中殘差較大者就是疑似離群值�,它也就是樣本數據中的最大值或最小值
3.查找產生離群值的原因
已經判斷為離群值的�,即使是統計離群值��,也不要簡單剔除了之��,應進一步分析產生離群值的原因�。
推薦學習書籍
《CDA一級教材》適合CDA一級考生備考���,也適合業務及數據分析崗位的從業者提升自我���。完整電子版已上線CDA網校�,累計已有10萬+在讀~

免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
