4. 區間估計
還以為你被上節課的內容唬住了~終于等到你�,還好沒放棄�!
本節我們將說明兩個問題:總體均值 的區間估計和總體比例 的區間估計����。
區間估計經常用于質量控制領域來檢測生產過程是否正常運行或者在“控制之中” �����,也可以用來監控互聯網領域各類數據指標是否在正常區間��。
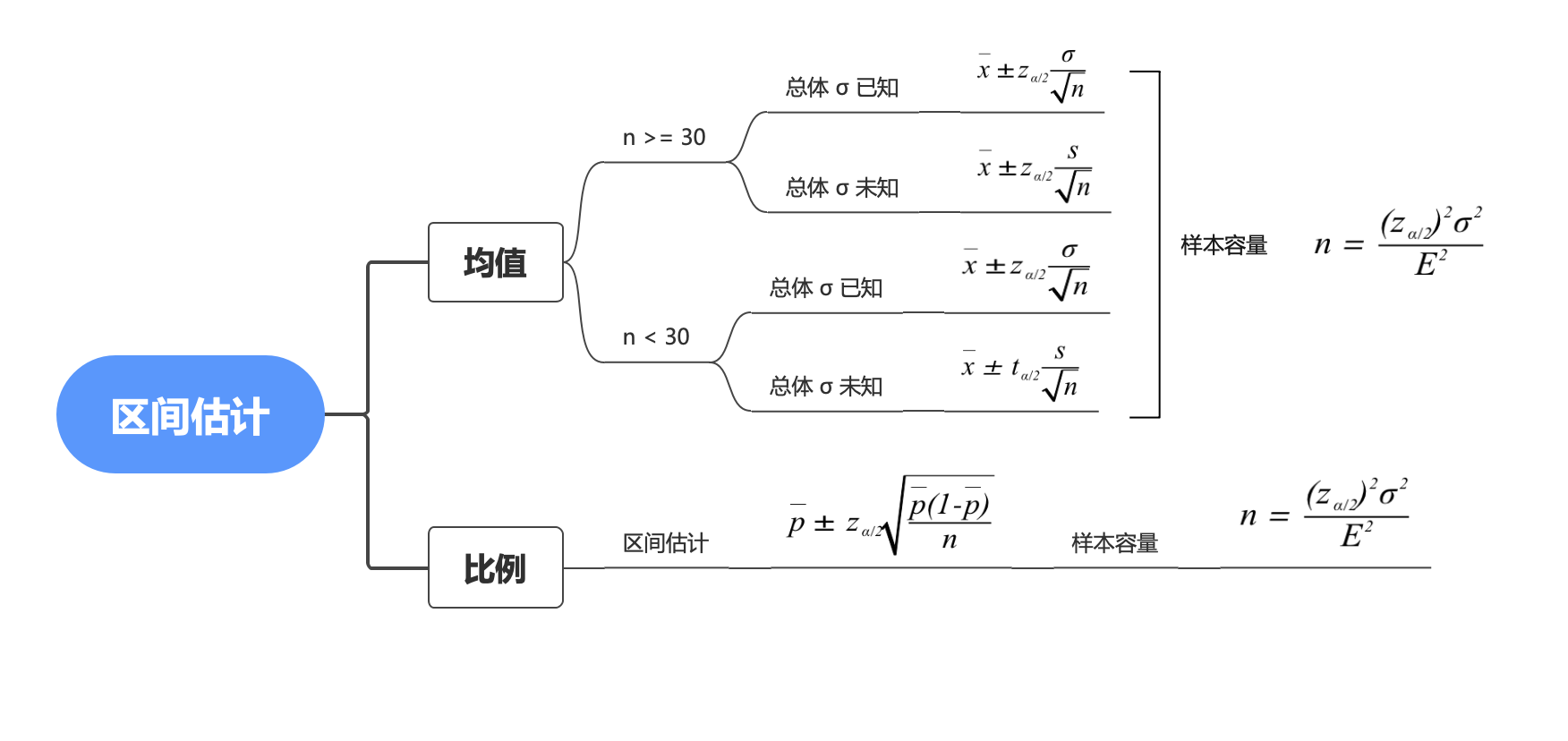
一個總體均值的區間估計
另外補充一個公式��,樣本量 這個了解就好�,大部分情況下是不缺數據的�,盡可能選數據量稍大些的數據�����。
把以上過程編寫成Python的自定義函數:
import numpy as np
import scipy.stats
from scipy import stats as sts
def mean_interval(mean=None, sigma=None,std=None,n=None,confidence_coef=0.95):
"""
mean:樣本均值
sigma: 總體標準差
std: 樣本標準差
n: 樣本量
confidence_coefficient:置信系數
confidence_level:置信水平 置信度
alpha:顯著性水平
功能:構建總體均值的置信區間
"""
alpha = 1 - confidence_coef
z_score = scipy.stats.norm.isf(alpha / 2)
t_score = scipy.stats.t.isf(alpha / 2, df = (n-1) )
if n >= 30:
if sigma != None:
me = z_score * sigma / np.sqrt(n)
print("大樣本���,總體 sigma 已知:z_score:",z_score)
elif sigma == None:
me = z_score * std / np.sqrt(n)
print("大樣本��,總體 sigma 未知 z_score",z_score)
lower_limit = mean - me
upper_limit = mean + me
if n < 30 :
if sigma != None:
me = z_score * sigma / np.sqrt(n)
print("小樣本�����,總體 sigma 已知 z_score * sigma / np.sqrt(n) n z_score = ",z_score)
elif sigma == None:
me = t_score * std / np.sqrt(n)
print("小樣本��,總體 sigma 未知 t_score * std / np.sqrt(n) n t_score = ",t_score)
print("t_score:",t_score)
lower_limit = mean - me
upper_limit = mean + me
return (round(lower_limit, 1), round(upper_limit, 1))
應用:網站流量UV區間估計:
某網站流量UV數據如下[52,44,55,44,45,59,50,54,62,46,54,42,60,62,43,42,48,55,57,56]���,我們研究一下該網站的總體流量uv均值���,我們先把數據放進來
import numpy as np
data = np.array([52,44,55,44,45,59,50,54,62,46,54,42,60,62,43,42,48,55,57,56])
計算一下均值為:
x_bar = data.mean()
x_bar
樣本標準差為:
x_std = sts.tstd(data,ddof = 1)
x_std
進行區間估計:
mean_interval(mean=x_bar, sigma=None,std= x_std, n=n, confidence_coef=0.95)
輸出結果:
小樣本���,總體 sigma 未知 t_score * std / np.sqrt(n)
t_score = 2.093024054408263
(48.3, 54.7)
于是我們有95%的把握�����,該網站的流量uv介于 [48, 55]之間�����。
值得一提的是���,上面這個案例的數據是實際上是公眾號山有木兮水有魚 的按天統計閱讀量……有人可能要說了����,你這數據也太慘了�,而且舉個案例都是小樣本�����。我想說����,小樣本的原因是這新號一共發了也沒幾天��,至于數量低�����,你幫忙動動小手轉發轉發�����,這數據也就高了~希望下次舉例的時候這個能變成大樣本��,均值怎么著也得個千兒八百的���,感謝感謝���!
一個總體比例的區間估計
其中樣本量
def proportion_interval(p=None, n=None, confidence_coef =0.95):
"""
p: 樣本比例
n: 樣本量
confidence_coef: 置信系數
功能:構建總體比例的置信區間
"""
alpha = 1 - confidence_coef
z_score = scipy.stats.norm.isf(alpha / 2)
me = z_score * np.sqrt((p * (1 - p)) / n)
lower_limit = p - me
upper_limit = p + me
return (round(lower_limit, 3), round(upper_limit, 3))
下期將為大家帶來《Python統計學極簡入門》之假設檢驗
這里分享一個你一定用得到的小程序——CDA數據分析師考試小程序���。
它是專為CDA數據分析認證考試報考打造的一款小程序��??梢詭湍憧焖賵竺荚?���、查成績�����、查證書�����、查積分���,通過該小程序����,考生可以享受更便捷的服務�。
掃碼加入CDA小程序����,與圈內考生一同學習����、交流���、進步��!












 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
