久經考場的你肯定對于很多概念類題目里問到的 “區別和聯系” 不陌生���,與之類似�����,在統計領域要研究的是數據之間的區別和聯系 �,也就是差異性分析 和相關性分析 ����。本節我們重點關注數據的差異性分析 ���。
我們知道�����,比較兩個數之間的大小����,要么前后兩者求差���,要么求比��。差值大于零說明前者大于后者�����。比值大于1說明分子大于分母����。
那么如何比較兩組數據的差異性呢�����?大道至簡����,其實和上面原理類似
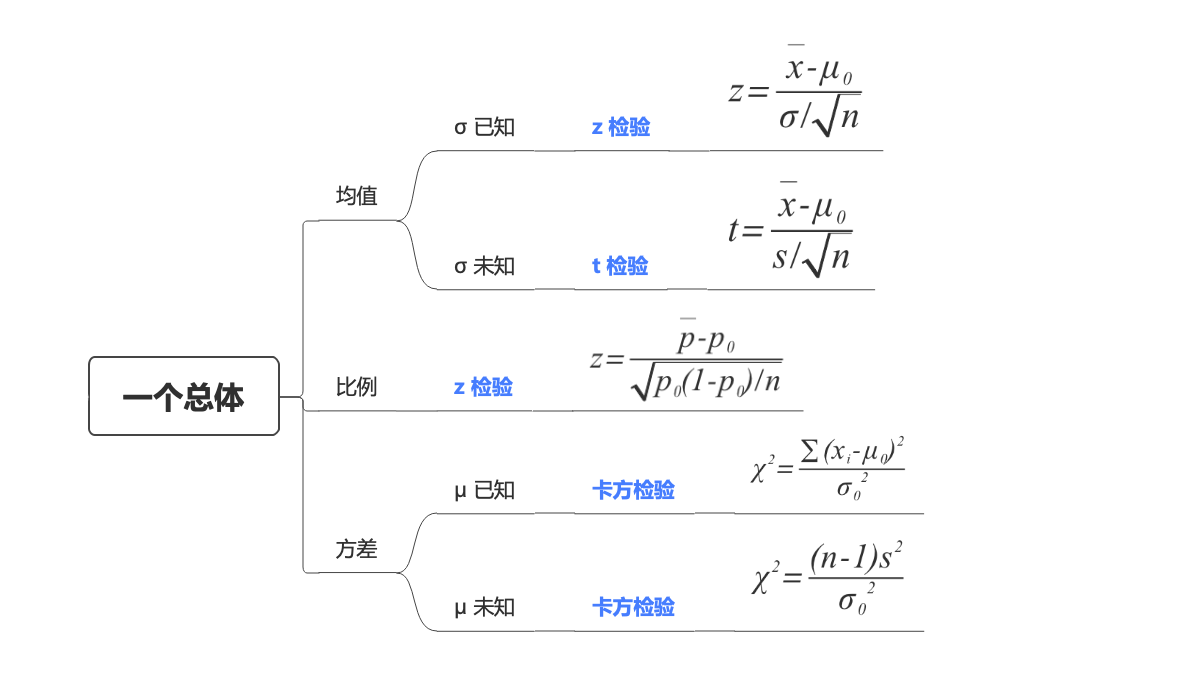
我們先從簡單的看起�,先比較一組數和一個給定數的差異��,即�,單個總體的差異性分析:
常見的單個總體差異性的假設檢驗 分為3個類型:均值����、比例��、方差
一個總體均值的假設檢驗 (指定值和樣本均值) 顧名思義�����,就是檢驗指定值與樣本均值的差異��,按
① 接下來我們用代碼舉例實現一下你就明白怎么用了:
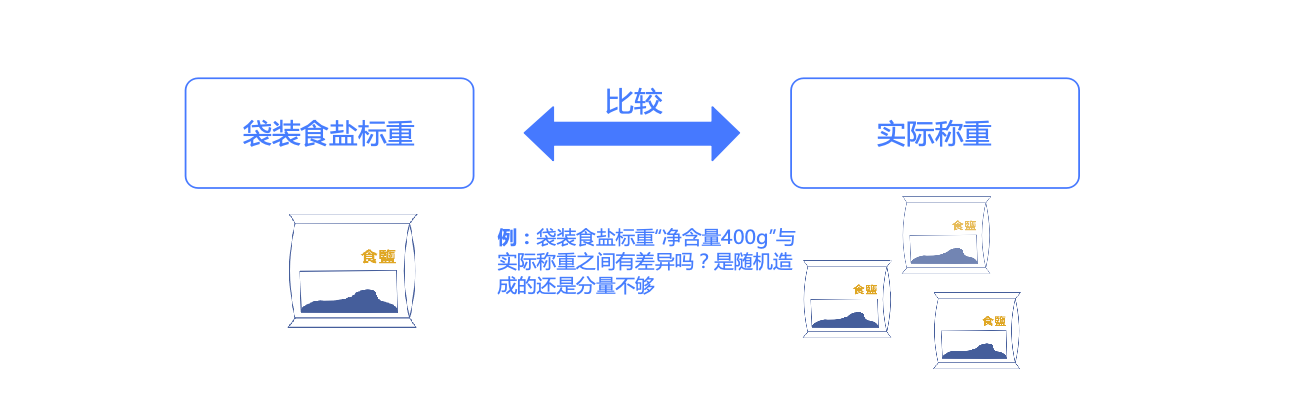
例5.1 檢驗一批廠家生產的紅糖是否夠標重
監督部門稱了50包標重500g的紅糖����,均值是498.35g���,少于所標的500g��。對于廠家生產的這批紅糖平均起來是否夠份量���,需要統計檢驗��。
分析過程:
由于廠家聲稱每袋500g,因此原假設為總體均值等于500g(被懷疑對象總是放在零假設)����。而且由于樣本均值少于500g(這是懷疑的根據)����,把備擇假設設定為總體均值少于500g (上面這種備選假設為單向不等式的檢驗稱為單側檢驗,而備選假設為不等號“
于是我們有了原假設和備擇假設
:
引入相關庫����、讀取數據如下
from scipy import statsimport scipy.statsimport numpy as npimport pandas as pdimport statsmodels.stats.weightstats493.01 ,498.83 ,494.16 ,500.39 ,497.63 ,499.72 ,493.41 ,498.97 ,501.94 ,503.45 ,497.47 ,494.19 ,500.99 ,495.81 ,499.63 ,494.91 ,498.90 ,502.43 ,491.34 ,497.50 ,505.95 ,496.56 ,501.66 ,492.02 ,497.68 ,493.48 ,505.40 ,499.21 ,505.84 ,499.41 ,505.65 ,500.51 ,489.53 ,496.55 ,492.26 ,498.91 ,496.65 ,496.38 ,497.16 ,498.91 ,490.98 ,499.97 ,501.21 ,502.85 ,494.35 ,502.96 ,506.21 ,497.66 ,504.66 ,492.11 ]進行z檢驗:
z, pval = statsmodels.stats.weightstats.ztest(data, value=500,alternative = 'smaller' )print (z,pval)結論: 選擇顯著性水平 0.05 的話�����,P=0.0035 < 0.05, 故應該拒絕原假設�����。具體來說就是該結果傾向于支持平均重量小于500g的備則假設�����。
② 例5.2 檢驗汽車實際排放是否低于其聲稱的排放標準
汽車廠商聲稱其發動機排放標準的一個指標平均低于20個單位�。在抽查了10臺發動機之后,得到下面的排放數據:
17.0 21.7 17.9 22.9 20.7 22.4 17.3 21.8 24.2 25.4
該樣本均值為21.13.究竟能否由此認為該指標均值超過20?
分析過程: 由于廠家聲稱指標平均低于20個單位,因此原假設為總體均值等于20個單位(被懷疑對象總是放在零假設)���。而且由于樣本均值大于20(這是懷疑的根據)��,把備擇假設設定為總體均值大于20個單位
于是我們有了原假設和備擇假設
:
讀取數據如下
data = [17.0 , 21.7 , 17.9 , 22.9 , 20.7 , 22.4 , 17.3 , 21.8 , 24.2 , 25.4 ]進行t檢驗如下:
import scipy.stats'greater' )print (t, pval)結論: 選擇顯著性水平 0.01 的話���,P=0.1243 > 0.05, 故無法拒絕原假設�����。具體來說就是該結果無法支持指標均值超過20的備則假設�����。
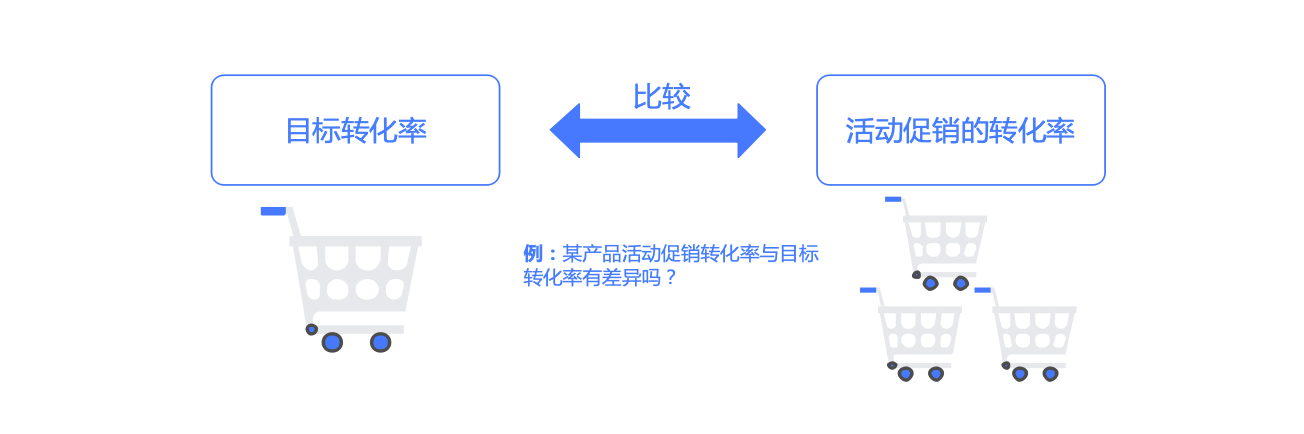
一個總體比例的假設檢驗 (指定比例和樣本比例) 例5.3 檢驗高爾夫球場女性球員比例是否因促銷活動而升高
某高爾夫球場去年打球?????????的人當中有20%是女性��,為了增加女性球員的比例��,該球場推出了一項促銷活動來吸引更多的女性參加高爾夫運動���,在活動實施了1個月后��,球場的研究者想通過統計分析 研究確定高爾夫球場的女性球員比例是否上升�����,收集到了400個隨機樣本�,其中有100是女性
分析過程: 由于研究的是女性球員所占的比例是否上升�����,因此選擇上側檢驗比較合適,備擇假設是比例大于20%
:
方法1:用statsmodels.stats.proportion里面的proportions_ztest函數計算(推薦) import numpy as npfrom statsmodels.stats.proportion import proportions_ztest100 400 0.2 0.2 400 'larger' ,prop_var = value)"z統計量:" , z_statistic)"p值:" , p_value)方法2 用手動方式計算 count = 100 400 0.2 0.2 400 def calc_z_score (p_bar, p_0, n) :1 - p_0) / n)**0.5 return z"z統計量:" , z)"p值:" , p)結論: 選擇顯著性水平 0.05 的話����,P=0.0062 < 0.05, 拒絕原假設����。具體來說就是該結果支持特定的促銷活動能夠提升該球場女性運動員比例的備則假設�。
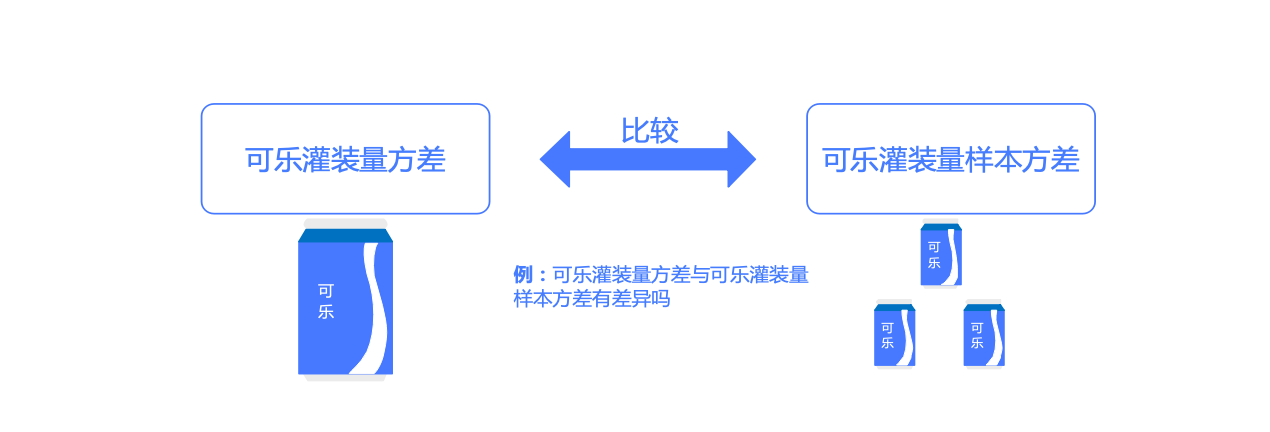
import numpy as np'' '方差 方差 '' if side == 'two-sided' :elif side == 'less' :elif side == 'greater' :return chi_square,p_value例5.4 檢驗公交車到站時間的方差 是否比規定標準大
某市中心車站為規范化提升市民對于公交車到站時間的滿意度���,對于公交車的到站時間管理做了規定����,標準是到站時間的方差 不超過4����。為了檢驗時間的到站時間的方差 是否過大���,隨機抽取了24輛公交車的到站時間組成一個樣本����,得到的樣本方差 是 正態分布 ����,請分析總體方差 是否過大��。
分析過程: 由于研究的是方差 是否過大���,因此選擇上側檢驗比較合適,備擇假設是方差 大于4
于是我們有了原假設和備擇假設
:
chi_square,p_value = chi2test(sample_var = 4.9, sample_num = 24, sigma_square = 4,side='greater' )print ("p值:" , p_value)結論: 選擇顯著性水平 0.05 的話����,P=0.2092 > 0.05, 無法拒絕原假設����。具體來說就是該結果不支持方差 變大的備則假設��。
例5.5 檢驗某考試中心升級題庫后考生分數的方差 是否有顯著變化
某數據分析師認證考試機構CDA考試中心��,歷史上的持證人考試分數的方差 為 方差 保持在原有水平上����,為了研究該問題��,收集到了30份新考題的考分組成的樣本�,樣本方差 是假設檢驗 �。
分析過程:由于目標是希望考試分數的方差 保持原有水平�,因此選擇雙側檢驗
于是我們有了原假設和備擇假設
:
p_value = chi2test(sample_var = 162, sample_num = 30, sigma_square = 100,side='two-sided' )print ("p值:" , p_value)結論: 選擇顯著性水平 0.05 的話���,P=0.0721 > 0.05, 故無法拒絕原假設�。具體來說就是不支持方差 發生了變化的備則假設���。
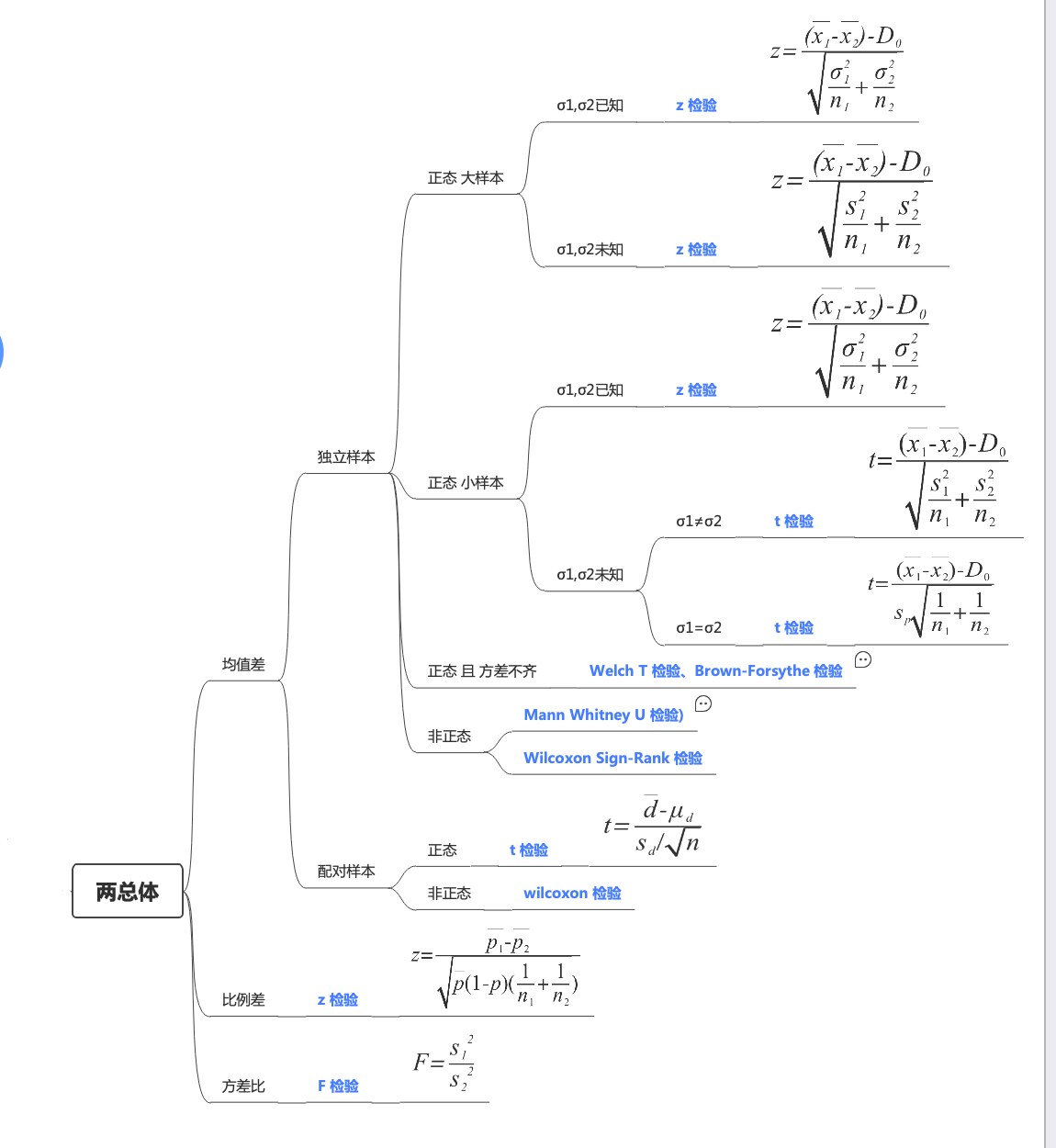
常見的兩總體差異性的假設檢驗 也分3個類型:均值����、比例�、方差
兩總體均值之差的假設檢驗 (獨立樣本) 例5.6(數據:drug.txt) 檢驗某藥物在實驗組的指標是否低于對照組
為檢測某種藥物對情緒的影響�,對實驗組的100名服藥者和對照組的150名非服藥者進行心理測試��,得到相應的某指標���。需要檢驗實驗組指標的總體均值正態分布 �。相應的假設檢驗 問題為:
分析過程:由于目標是檢驗實驗組指標的總體均值
于是我們有了原假設和備擇假設
:
data = pd.read_table("./t-data/drug.txt" ,sep = ' ' )5 )
ah
id
4.4
2
6.8
2
9.6
2
4.8
2
13.2
1
a = data[data['id' ]==1 ]['ah' ]'id' ]==2 ]['ah' ]''' 'greater' )結論: 選擇顯著性水平 0.05 的話���,p = 0.1816 > 0.05,無法拒絕H0��,具體來說就是該結果無法支持實驗組均值大于對照組的備則假設���。
兩總體均值之差的假設檢驗 (配對樣本) 例5.7(數據: diet.txt) 檢驗減肥前后的重量是否有顯著性差異(是否有減肥效果)
這里有兩列50對減肥數據��。其中一列數據(變量名before)是減肥前的重量�,另一列(變量名after)是減肥后的重量(單位: 公斤)����,人們希望比較50個人在減肥前和減肥后的重量����。
分析過程:這里不能用前面的獨立樣本均值差的檢驗�,這是因為兩個樣本并不獨立���。每一個人減肥后的重量都和自己減肥前的重量有關��,但不同人之間卻是獨立的���,所以應該用配對樣本檢驗����。同時�,由于研究的是減肥前后的重量變化�,期望減肥前的重量大于減肥后的重量���,所以備擇假設是期望減肥前的重量大于減肥后的重量
于是我們有了原假設和備擇假設:
:
data = pd.read_table("./t-data/diet.txt" ,sep = ' ' )5 )
before
after
58
50
76
71
69
65
68
76
81
75
a = data['before' ]'after' ]'greater' )結論 選擇顯著性水平 0.05 的話�,p = 0.0007 < 0.05,故應該拒絕原假設��。具體來說就是該結果傾向支持減肥前后的重量之差大于零(即減肥前重量大于減肥后�����,也就是有減肥效果)的備則假設�����。
import numpy as np'two-sided' ):"" "假設檢驗 的方向��,可選'two-sided'(雙側檢驗���,默認), 'greater'(右側檢驗), 'less'(左側檢驗) "" if side == 'two-sided' :elif side == 'greater' :elif side == 'less' :else :"Invalid side value. Must be 'two-sided', 'greater', or 'less'." )return z_value, p_value例5.8 檢驗不同保險客戶的索賠率是否存在差異
某保險公司抽取了單身與已婚客戶的樣本�����,記錄了他們在一段數據內的索賠次數��,計算了索賠率���,現在需要檢驗兩種保險客戶的索賠率是否存在差異
分析過程:由于目標比例是否有差異�����,因此選擇比例之差的雙側檢驗
于是我們有了原假設和備擇假設
:
p1 = 0.14 0.09 250 300 'two-sided' )"Z_value:" , z_value)"p_value:" , p_value)結論 選擇顯著性水平 0.05 的話�,p = 0.0648 > 0.05,故應該拒絕原假設�。具體來說就是該結果傾向支持兩種保險客戶的索賠率存在差異的備則假設����。
import numpy as np'two-sided' ):"" "方差 �;s2_square:樣本2的方差 "" if side=='two-sided' :print ("two-sided" )return F_value,p_valueelif side=='greater' :print ("greater" )return F_value,p_value例5.9 檢驗不同公交公司的校車到達時間的方差 是否有差異
某學校的校車合同到期��,先需要在A�����、B兩個校車供應公司中選擇一個��,才有到達時間的方差 作為衡量服務質量的標準�����,較低方差 說明服務質量穩定且水平較高����,如果方差 相等�����,則會選擇價格更低的公司�����,�����,如果方差 不等���,則優先考慮方差 更低的公司����。
現收集到了A公司的26次到達時間組成一個樣本�����,方差 68��,B公司16次到達時間組成一個樣本�,方差 是30��,請檢驗AB兩個公司的到達時間方差 ���。
分析過程:由于目標是希望的方差 保持原有水平����,因此選擇雙側檢驗����。兩總體方差 之比用F檢驗,將方差 較大的A視為總體1
于是我們有了原假設和備擇假設
:
f_statistic , p_value= f_test_by_s_square(n1=26 , n2=16 ,s1_square=78 ,s2_square=20 ,side='two-sided' )"F statistic:" , f_statistic)"p-value:" , p_value)結論 選擇顯著性水平 0.05 的話�,p = 0.0083 < 0.05,故拒絕原假設��。結果傾向支持AB兩個公司的到達時間方差 存在差異的備則假設�。
例5.10 檢驗修完Python課程的學生是否比修完數據庫課程的學生考CDA的成績方差 更大
某高校數據科學專業的學生���,修完一門數據庫課程的41名學生考CDA的方差 方差 是方差 更大����?
分析過程:由于目標是希望修完Python的學生CDA成績的方差 更大��,因此選擇上側檢驗�����。兩總體方差 之比用F檢驗,將方差 較大的數據庫課程的考試成績視為總體1,另一個視為總體2�,于是我們有了原假設和備擇假設
:
f_statistic , p_value= f_test_by_s_square(n1=41, n2=31,s1_square=120,s2_square=80,side='greater' )print ("F statistic:" , f_statistic)print ("p-value:" , p_value)結論 選擇顯著性水平 0.05 的話��,p = 0.1256 > 0.05��,故無法原假設��。結果無法支持修完數據庫的學生要比修完Python的學生CDA成績的方差 更大的備則假設�����。
關于知識的學習��,你會發現有很多相似的邏輯���,抓住問題的本質去理解的話就沒那么復雜了�����,比如概念題里面的 區別和聯系 延伸到數據分析里的差異性和相關性 ���;再比如計算機數據結構 里的 樹��、森林��、網絡 到機器學習 里面的決策樹 �����、隨機森林 ����、神經網絡 互聯網���、區塊鏈到元宇宙 ���,都是想通過技術的手段去刻畫客觀世界��;算法應用里面的圖像識別 ���、語音識別��,替代人的眼耳鼻舌身意 中的前二者去感知世界�����。抓住了問題的本質不僅可以幫助我們理解知識�,還可以將一個領域的知識或模型遷移到另一個領域加以創新和應用���。
假設檢驗 背后的故事:統計學史上最著名的女士品茶
下期將為大家帶來《統計學極簡入門》之 方差 分析
這里分享一個你一定用得到的小程序——CDA數據分析師考試小程序�����。
它是專為CDA數據分析認證考試報考打造的一款小程序����?��?梢詭湍憧焖賵竺荚?��、查成績����、查證書��、查積分����,通過該小程序�����,考生可以享受更便捷的服務��。
掃碼加入CDA小程序�,與圈內考生一同學習���、交流�����、進步��!













 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
