變量選擇之SCAD算法
本文提出了一種用于同時達到選擇變量和預測模型系數的目的的方法——SCAD�����。這種方法的罰函數是對稱且非凹的�����,并且可處理奇異陣以產生稀疏解���。此外���,本文提出了一種算法用于優化對應的帶懲罰項的似然函數�����。這種方法具有廣泛的適用性����,可以應用于廣義線性模型���,強健的回歸模型��。借助于波和樣條�����,還可用于非參數模型��。更進一步地����,本文證明該方法具有Oracle性質����。模擬的結果顯示該方法相比主流的變量選擇模型具有優勢���。并且���,模型的預測誤差公式顯示����,該方法實用性較強�����。
SCAD的理論理解
在總結了現有模型的一些缺點之后���,本文提出構造罰函數的一些目標:
罰函數是奇異的(singular)
連續地壓縮系數
對較大的系數產生無偏的估計
SCAD模型的Oracle性質��,使得它的預測效果跟真實模型別無二致�。
并且���,這種方法可以應用于高維非參數建模�����。
SCAD的目標函數如下:
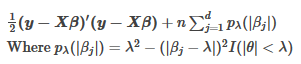
SCAD的罰函數與$theta$的(近似)關系如下圖所示��。

可見�����,罰函數可以用二階泰勒展開逼近�。
Hard Penality,lasso,SCAD的系數壓縮情況VS系數真實值的情況如下圖所示�。

可以看到�����,lasso壓縮系數是始終有偏的���,Hard penality是無偏的����,但壓縮系數不連續��。而SCAD既能連續的壓縮系數��,也能在較大的系數取得漸近無偏的估計�。
這使得SCAD具有Oracle性質��。
SCAD的缺點
模型形式過于復雜
迭代算法運行速度較慢
在low noise level的情況下表現較優���,但在high noise level的情況下表現較差�。
SCAD的實現
SCAD迭代公式
SCAD的目標函數如下:
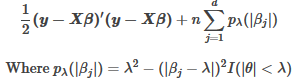
時�����,罰函數可以用二階泰勒展開逼近����。
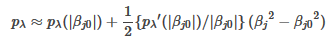
從而����,有如下迭代公式:
根據以上公式����,代入迭代步驟�����,即可實現算法��。
SCAD的R實現
##------數據模擬--------
library(MASS)
##mvrnorm()
##定義一個產生多元正態分布的隨機向量協方差矩陣
Simu_Multi_Norm<-function(x_len, sd = 1, pho = 0.5){
#初始化協方差矩陣
V <- matrix(data = NA, nrow = x_len, ncol = x_len)
#mean及sd分別為隨機向量x的均值和方差
#對協方差矩陣進行賦值pho(i,j) = pho^|i-j|
for(i in 1:x_len){ ##遍歷每一行
for(j in 1:x_len){ ##遍歷每一列
V[i,j] <- pho^abs(i-j)
}
}
V<-(sd^2) * V
return(V)
}
##產生模擬數值自變量X
set.seed(123)
X<-mvrnorm(n = 200, mu = rep(0,10), Simu_Multi_Norm(x_len = 10,sd = 1, pho = 0.5))
##產生模擬數值:響應變量y
beta<-c(1,2,0,0,3,0,0,0,-2,0)
#alpha<-0
#prob<-exp(alpha + X %*% beta)/(1+exp(alpha + X %*% beta))
prob<-exp( X %*% beta)/(1+exp( X %*% beta))
y<-rbinom(n = 200, size = 1,p = prob)
##產生model matrix
mydata<-data.frame(X = X, y = y)
#X<-model.matrix(y~., data = mydata)
##包含截矩項的系數
#b_real<-c(alpha,beta)
b_real<-beta
########----定義懲罰項相關的函數-----------------
##定義懲罰項
####運行發現�,若lambda設置為2�,則系數全被壓縮為0.
####本程序根據rcvreg用CV選出來的lambda設置一個較為合理的lambda��。
p_lambda<-function(theta,lambda = 0.025){
p_lambda<-sapply(theta, function(x){
if(abs(x)< lambda){
return(lambda^2 - (abs(x) - lambda)^2)
}else{
return(lambda^2)
}
}
)
return(p_lambda)
}
##定義懲罰項導數
p_lambda_d<-function(theta,a = 3.7,lambda = 0.025){
if(abs(theta) > lambda){
if(a * lambda > theta){
return((a * lambda - theta)/(a - 1))
}else{
return(0)
}
}else{
return(lambda)
}
}
# ##當beta_j0不等于0���,定義懲罰項導數近似
# p_lambda_d_apro<-function(beta_j0,beta_j,a = 3.7, lambda = 2){
# return(beta_j * p_lambda_d(beta = beta_j0,a = a, lambda = lambda)/abs(beta_j0))
# }
#
#
# ##當beta_j0 不等于0�,指定近似懲罰項,使用泰勒展開逼近
# p_lambda_apro<-function(beta_j0,beta_j,a = 3.7, lambda = 2){
# if(abs(beta_j0)< 1e-16){
# return(0)
# }else{
# p_lambda<-p_lambda(theta = beta_j0, lambda = lambda) +
# 0.5 * (beta_j^2 - beta_j0^2) * p_lambda_d(theta = beta_j0, a = a, lambda = lambda)/abs(beta_j0)
# }
# }
#define the log-likelihood function
loglikelihood_SCAD<-function(X, y, b){
linear_comb<-as.vector(X %*% b)
ll<-sum(y*linear_comb) + sum(log(1/(1+exp(linear_comb)))) - nrow(X)*sum(p_lambda(theta = b))
return (ll)
}
##初始化系數
#b0<-rep(0,length(b_real))
#b0<- b_real+rnorm(length(b_real), mean = 0, sd = 0.1)
##將無懲罰時的優化結果作為初始值
b.best_GS<-b.best
b0<-b.best_GS
##b1用于記錄更新系數
b1<-b0
##b.best用于存放歷史最大似然值對應系數
b.best_SCAD<-b0
# the initial value of loglikelihood
ll.old<-loglikelihood_SCAD(X = X,y = y, b = b0)
# initialize the difference between the two steps of theta
diff<-1
#record the number of iterations
iter<-0
#set the threshold to stop iterations
epsi<-1e-10
#the maximum iterations
max_iter<-100000
#初始化一個列表用于存放每一次迭代的系數結果
b_history<-list(data.frame(b0))
#初始化列表用于存放似然值
ll_list<-list(ll.old)
#######-------SCAD迭代---------
while(diff > epsi & iter < max_iter){
for(j in 1:length(b_real)){
if(abs(b0[j]) < 1e-06){
next()
}else{
#線性部分
linear_comb<-as.vector(X %*% b0)
#分子
nominator<-sum(y*X[,j] - X[,j] * exp(linear_comb)/(1+exp(linear_comb))) +
nrow(X)*b0[j]*p_lambda_d(theta = b0[j])/abs(b0[j])
#分母,即二階導部分
denominator<- -sum(X[,j]^2 * exp(linear_comb)/(1+exp(linear_comb))^2) +
nrow(X)*p_lambda_d(theta = b0[j])/abs(b0[j])
#2-(3) :更新b0[j]
b0[j]<-b0[j] - nominator/denominator
#2-(4)
if(abs(b0[j]) < 1e-06){
b0[j] <- 0
}
# #更新似然值
# ll.new<- loglikelihood_SCAD(X = X, y = y, b = b0)
#
#
#
# #若似然值有所增加���,則將當前系數保存
# if(ll.new > ll.old){
# #更新系數
# b.best_SCAD[j]<-b0[j]
# }
#
# #求差異
# diff<- abs((ll.new - ll.old)/ll.old)
# ll.old <- ll.new
# iter<- iter+1
# b_history[[iter]]<-data.frame(b0)
# ll_list[[iter]]<-ll.old
# ##當達到停止條件時����,跳出循環
# if(diff < epsi){
# break
# }
#
}
}
#更新似然值
ll.new<- loglikelihood_SCAD(X = X, y = y, b = b0)
#若似然值有所增加����,則將當前系數保存
if(ll.new > ll.old){
#更新系數
b.best_SCAD<-b0
}
#求差異
diff<- abs((ll.new - ll.old)/ll.old)
ll.old <- ll.new
iter<- iter+1
b_history[[iter]]<-data.frame(b0)
ll_list[[iter]]<-ll.old
}
b_hist<-do.call(rbind,b_history)
#b_hist
ll_hist<-do.call(rbind,ll_list)
#ll_hist
#
iter
##
ll.best<-max(ll_hist)
ll.best
##
b.best_SCAD
##對比
cbind(coeff_glm,b.best,b.best_SCAD,b_real)
##----------ncvreg驗證-----------
library(ncvreg)
my_ncvreg<-ncvreg(X,y,family = c("binomial"),penalty = c("SCAD"),lambda = 2)
my_ncvreg$beta
my_ncvreg<-ncvreg(X,y,family = c("binomial"),penalty = c("SCAD"))
summary(my_ncvreg)
my_ncvreg$beta
###用cv找最優的lambda
scad_cv<-cv.ncvreg(X,y,family = c("binomial"),penalty='SCAD')
scad_cv$lambda.min
mySCAD=ncvreg(X,y,family = c("binomial"),penalty='SCAD',lambda=scad_cv$lambda.min)
summary(mySCAD)
ncv_SCAD<-mySCAD$beta[-1]
##對比
myFinalResults<-cbind(無懲罰項回歸=coeff_glm, GS迭代 = b.best,
GS_SCAD迭代 = b.best_SCAD, ncvreg = ncv_SCAD,真實值 = b_real)
save(myFinalResults,file = "myFinalResults.rda")
想深入學習統計學知識��,為數據分析筑牢根基��?那快來看看統計學極簡入門課程����!

學習入口:https://edu.cda.cn/goods/show/3386?targetId=5647&preview=0
課程由專業數據分析師打造��,完全免費�,60 天有效期且隨到隨學�。它用獨特思路講重點�,從數據種類到統計學體系���,內容通俗易懂��。學完它�,能讓你輕松入門統計學��,還能提升數據分析能力��。趕緊點擊鏈接開啟學習���,讓自己在數據領域更上一層樓��!
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情��;

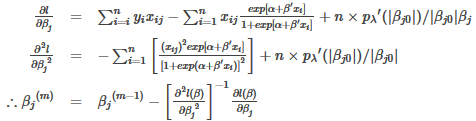










 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
