概括地說���,泛化能力(generalization ability)是指機器學習算法對新鮮樣本的適應能力����。學習的目的是學到隱含在數據對背后的規律��,對具有同一規律的學習集以外的數據���,經過訓練的網絡也能給出合適的輸出�����,該能力稱為泛化能力��。
在機器學習方法中����,泛化能力通俗來講就是指學習到的模型對未知數據的預測能力���。在實際情況中�����,我們通常通過測試誤差來評價學習方法的泛化能力���。如果在不考慮數據量不足的情況下出現模型的泛化能力差�,那么其原因基本為對損失函數的優化沒有達到全局最優��。
1.泛化能力
在機器學習方法中���,泛化能力通俗來講就是指學習到的模型對未知數據的預測能力�����。在實際情況中�,我們通常通過測試誤差來評價學習方法的泛化能力��。如果在不考慮數據量不足的情況下出現模型的泛化能力差�,那么其原因基本為對損失函數的優化沒有達到全局最優��。
2.泛化誤差
首先給出泛化誤差的定義����, 如果學到的模型是 f^ ���, 那么用這個模型對未知數據預測的誤差即為泛化誤差
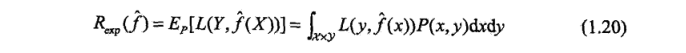
泛化誤差反映了學習方法的泛化能力���,如果一種方法學習的模型比另一種方法學習的模型具有更小的泛化誤差�,那么這種方法就更有效��, 事實上��,泛化誤差就是所學到的模型的期望誤差����。
3.提高泛化能力
提高泛化能力的方式大致有三種:1.增加數據量��。2.正則化�����。3.凸優化�。
4.L1正則化��,L2正則化
L1正則化的幾何解釋如圖:

L1正則化給出的最優解w?是使解更加靠近某些軸���,而其它的軸則為0.所以L1正則化能使得到的參數稀疏化�����。
L1正則化的參數先驗是服從拉布拉斯分布的���,拉布拉斯的概率密度分布函數為:

L2正則化的解釋如圖:

L2 正則化給出的最優解w?是使解更加靠近原點����,也就是說L2正則化能降低參數范數的總和����。
L2正則化的參數先驗服從高斯分布��,高斯分布的概率密度分布函數為:

CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
