在機器學習中�,相對于欠擬合�����,過擬合出現的頻次更高���。這是因為�����,假設某一數據集其對應的模型為‘真’模型��,我們通常是采用提高模型的復雜度的方法����,來避免欠擬合現象的產生�����,但與此同時�����,我們又很難把網絡設計成和‘真’模型一樣����,所以最終網絡模型會因為復雜度太高而產生過擬合�����。今天小編就給大家整理了過擬合產生的原因及一些相應的解決方法�����,希望對大家機器學習中解決過擬合問題有所幫助�����。
一��、什么是過擬合
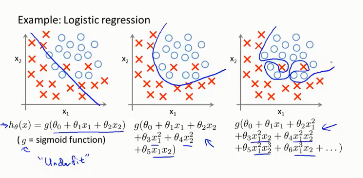
過擬合定義:給定一個假設空間H�,一個假設h屬于H���,如果存在其他的假設h’屬于H,使得在訓練樣例上h的錯誤率比h’小��,但在整個實例分布上h’比h的錯誤率小��,那么就說假設h過度擬合訓練數據����。
過擬合(overfiting / high variance)表現為:模型在訓練集上表現很好��,但是在測試集上表現較差����。也就是說模型的泛化能力弱�。
簡單理解過擬合�,就是模型對訓練數據的信息提取過多���,不僅學習到了數據背后的規律��,連數據噪聲都當做規律學習了�����。
對比欠擬合理解起來會更容易:

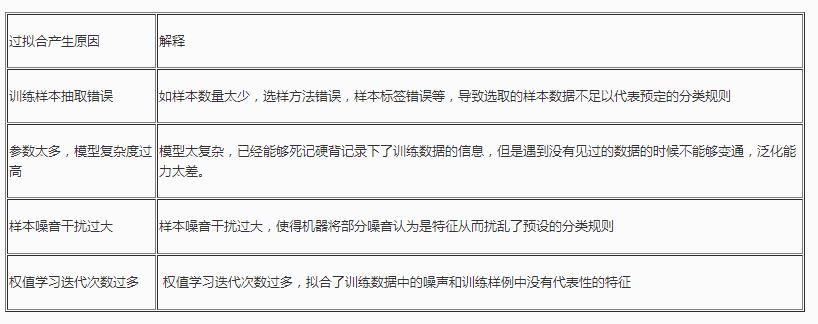
二��、過擬合產生原因
三���、過擬合處理辦法
1����、重新清洗數據�,過擬合出現也有可能是數據不純����,這種情況下我們需要重新清洗數據����。
2����、數據增強���,也就是獲取和使用更多的數據集�����。給與模型足夠多的數據集����,讓它在盡可能多的數據上進行“觀察”和擬合��,從而進行不斷修正����。但是需要注意的是�����,我們是不可能收集無限多的數據集的��,所以通常的方法��,就是對已有的數據進行���,添加大量的“噪音”����,或者對圖像進行銳化����、對旋轉�、明暗度進行調整等��。
3���、采用正則化方法���。加入正則化項就是在原來目標函數的基礎上加入了約束����。常用的正則化項有L1.L2.當目標函數的等高線和L1.L2正則化損失函數第一次相交時����,得到最優解��。
L1正則化項約束后的解空間為多邊形���,這些多邊形的角和目標函數的接觸機會遠大于其他部分�。就會造成最優值出現在坐標軸上�,因此就會導致某一維的權重為0 �����,產生稀疏權重矩陣�,進而防止過擬合�����。
L2正則化項約束后的解空間為圓形�����,圖像上的棱角圓滑了很多����。一般最優值不會在坐標軸上出現����。在最小化正則項時����,參數不斷趨向于0.最后得到的就是很小的參數�����。
4���、采用dropout方法���。
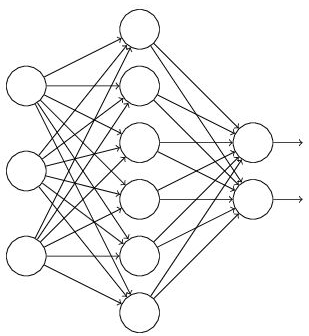
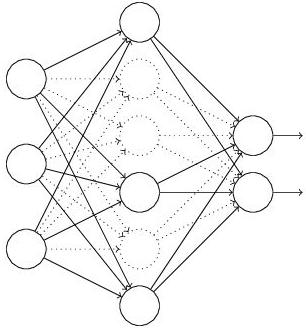
運用了dropout方法��,就相當于訓練了非常多的�����,僅僅只有部分隱層單元的神經網絡�����,每一個這種半數網絡�,都能夠給出一個分類結果��,這些結果中��,有正確的�,也有錯誤的���。隨著訓練的進行����,大多數半數網絡都能給出正確的分類結果��。這樣一來��,那些少數的錯誤分類結果對于最終結果就不會哦造成大的影響�。而且dropout通過減少神經元之間復雜的共適應關系���,從而也提高了模型的泛化能力���。
5�����、提前結束訓練
也就是early stopping�����,在模型迭代訓練時��,對訓練精度(損失)和驗證精度(損失)進行記錄�,如果模型訓練的效果不能夠再提高��,例如訓練誤差一直降低�����,但是驗證誤差卻不再降低甚至上升的情況���,我們可以采用結束模型訓練的方法��。
6����、集成學習
集成學習算法也可以有效的減輕過擬合�。Bagging通過平均多個模型的結果��,來降低模型的方差�。Boosting不僅能夠減小偏差�����,還能減小方差���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
