對于機器學習或者是深度學習模型來說�,我們既希望這個模型能在訓練數據中表現良好(訓練誤差)��,又希望這個模型在測試集中也能有良好的表現(泛化誤差)�。而過擬合和欠擬合就是用來描述泛化誤差的����。欠擬合問題與過擬合問題�����,一直是模型訓練中的難題����,我們常常需要對這二者進行權衡���,今天小編給大家整理�����、分享的就是欠擬合問題產生的原因以及解決辦法�,希望對大家有所幫助����。
一���、什么是欠擬合
欠擬合underfiting / high bias�,就是指模型不能在訓練集上獲得足夠低的誤差���,在訓練集���、驗證集以及測試集上均表現不佳的情況�。用偏差和方差來解釋就是��,欠擬合的時候為高偏差(偏差描述的是模型的期望輸出與真實輸出之間的差異)�����。
出現欠擬合的原因是模型尚未學習到數據的真實結構��。因此欠擬合可以簡單理解為:模型對訓練數據的信息提取不充分���,并沒有學習到數據背后的規律���,導致模型應用在測試集上時���,無法做出正確的判斷����。
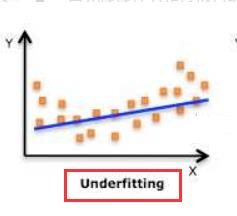
欠擬合�,模型擬合程度不高�����,數據距離擬合曲線較遠��,不能夠很好地擬合數據���。
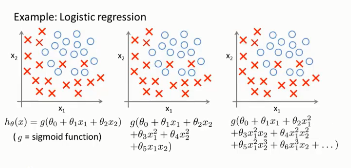
圖中第一個模型欠擬合��,無法學習到數據的有效特征
二��、欠擬合解決辦法
1��、做特征工程���,添加其他特征項���,有時候欠擬合出現的原因是:特征項不夠����,沒有足夠的信息支持模型做判斷�����。這時候我們可以通過添加其他特征項來解決���。例如�����,“組合”����、“泛化”�、“相關性”�����、“上下文特征”��、“平臺特征”等等��,都能夠作為特征添加的首選項��。
2���、添加多項式特征����,這種做法在機器學習算法里面很常用�����,舉個例子�,比如將線性模型通過添加二次項或者三次項使模型泛化能力更強���。
3��、減少正則化參數��,正則化的目標是:防止過擬合的����,現在模型是欠擬合�����,就需要減少正則化參數��。
4����、增加模型復雜度���。模型如果太簡單���,就不能應對復雜的任務��。我們可以通過使用更加復雜的模型����,來減小正則化系數��。比如可以使用核函數����,集成學習方法(集成學習方法boosting(如GBDT)能有效解決high bias)�,深度學習等���。
以上就是小編今天跟大家分享的一些欠擬合的相關知識�,希望對大家處理和解決欠擬合問題有所幫助�。其他機器學習和深度學習的知識�����,小編也會繼續整理��,希望大家多多關注�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
