大數據如何創造錯覺
如果我說美國人現在開始越來越以自我為中心了�,你也許會想這個老家伙肯定又要嘟囔些“過去才是好日子”之類的����。但是���,如果我說我有著對1500億個文本詞語的分析來支持這個結論呢?在幾十年前�,這樣規模的論據簡直是天方夜譚��。而在今天�,1500億個數據已經過時了�����。大數據分析的熱潮已經卷過了生物學�����、語義學���、金融學以及其相間的各種領域�����。
盡管沒有人能夠在如何定義“大數據”上取得一致�����,但大致概念是找到足夠大的數據庫�����,這樣就可以發現傳統調查中無法發現的規律��。這些數據來源于數百萬個現實用戶的行為����,例如��,發推特或信用卡消費�����,并且這些行為需要上千臺計算機來收集�����、存儲與分析��。
而對于許多計算機研究者來說�����,這個投資是值得的���,因為數據中的規律可以解鎖從基因序列到明日股票價格的一切信息����。
但是有一個問題:我們不禁認為在如此驚人數量的數據的支持下�����,基于大數據的研究是不可能出錯的�。然而���,數據的海量特征會給結果灌注一種錯誤的確定感�。許多結果都是不真實的——而其原因會讓我們重新思考那些盲目信任大數據的研究�。
在語言和文化中���,大數據在 2011 年隆重出場����,那時谷歌發布了它的 Ngrams 工具�����。
谷歌在《Science》雜志中發表的文章大張旗鼓地宣布�, Ngrams 可以讓用戶在谷歌掃描書籍數據庫中尋找特定短語——這個數據庫囊括了幾乎 4%出版過的書籍!——并獲知這些短語的頻率如何隨著時間而變化��。
這篇論文的作者預言了“文化經濟學”的降臨����,一個基于大量數據的對文化的研究���。并且自此以后���,谷歌 Ngrams 變成了一個幾乎無限的娛樂來源——但也是語義學�、心理學和社會學的一座金礦����。
例如�,他們搜羅了數百萬書籍去展示��,是的�����,美國正在變得愈來愈個人主義����,我們正在“每一年都在加速忘記我們的過去”���,道德理想正在從我們的文化意識中消失���。
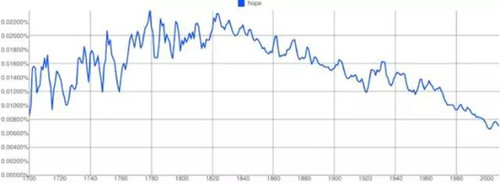
我們正在失去希望:網絡漫畫《xkcd》的作者 Randal Munroe 所創造的許多有趣的小漫畫之一是一個關于希望的 Ngrams 表格���。
如果 Ngrams 真的反射出了我們的文化��,我們也許正在前往一個黑暗的未來��。
問題開始于 Ngrams 語料庫建立的方式���。
在去年十月發表的一篇研究中���,三位來自佛蒙特大學(University of Vermont����,UVM)的研究者指出�,總體來說�����,Google Books 收納了每 一本書的復印版����。這與它的最初目標完美相符:讓這些書本的內容完全呈現于谷歌強大的檢索技術中�����。盡管從社會學研究的角度來說����,它讓語料庫有了危險的歪曲�����。
舉個例子���,一些書籍淪落到了低于它們真正文化重量的境地:《指環王》的影響力還沒有《巴伐利亞的巫術迫害》多����。
而相反的��,一些作家則開始變得十分凸顯����。從英文小說的數據來看����,你可以總結出在上世紀初期的20年里��,每個角色的兄弟都叫做 Lanny�。實際上這個數據甚至反映了一位(并不一定是受歡迎的)作家 Upton Sinclair 有多么多產:他寫出了11部有著同一個「Lanny Budd」的小說�����。
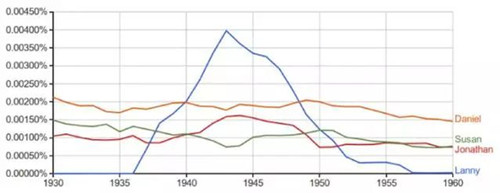
到底誰是 Lanny ?:「Lanny」與其他英文小說中常見名字相對比的谷歌 Ngrams 圖標
更加糟糕的是 �����,Ngrams 并不是已出版書籍的一種連續的�、平衡的縮影����。同一份 UVM 的研究證明�,在許多發生的創作變化之中���,值得注意的是開始于上世紀60年代的科幻小說的增多�。
所有這些都讓我們很難相信谷歌的 Ngrams 能夠準確地反映出文字文化主流隨著時間的變化���。
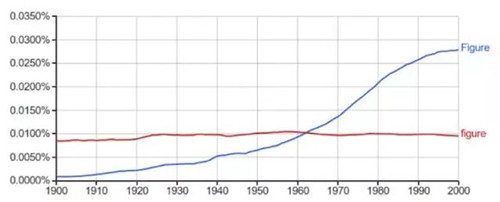
FIGURE 圖表:主要用于標題的大寫字母F開頭的“Figure”使用頻率在20世紀大幅上升����,意味著語料庫中科技文章開始增加��。這也許解釋了一些關于社會的問題��,但是并沒有更多解釋大多數社會是如何用這些詞語的���。
即使通過了數據來源的檢驗��,在理解這一關依然存在尖銳的問題����。
的確����,像“性格“和”尊嚴“這樣的用詞在過去幾十年的使用也許下降了�。但是這意味著人們對于道德的關注就減少了嗎?
伊利諾伊斯大學香檳分校的英文學教授 Ted Underwood 警告說����,不要這么快下定義��。他指出�����,我們現在關于道德的理解也許與在 19�、20世紀之交時的概念有著巨大出入��,并且“尊嚴”也許因為非道德的原因變得逐漸普及化���。因此任何我們從將眼下的關聯投射到過去所總結的結論都是可疑的�����。
當然了����,這些對于統計學和語義學來說都不是新鮮事�����。數據與表征是他們的面包與黃油���。而谷歌 Ngrams 不同的是�����,它有著讓純粹的數據遮蔽了我們的雙眼并導致人們誤入歧途的危險�����。
這種傾向不僅僅出現在對于 Ngrams 的研究中���。相似的錯誤也損害著各種大數據項目�。
例如�,谷歌的 Google Flu Trends(GFT)項目�����。誕生于 2008 年的 GFT 項目會計算數百萬的谷歌檢索中“發燒”與“咳嗽”等詞語出現的數量�,利用它們去“預測”多少人得了流感����。有了這些估測���,公眾健康機構就能夠在疾疫控制中心從醫生報告中得出真正數量的兩周前就采取行動���。
當大數據不再被看成一個萬金油的時候���,它才會真正有顛覆性���。
最初����,GFT 宣稱自己有 97% 的準確度�。但是根據西北大學文檔的研究�����,這種準確度僅僅是一個僥幸��。首先����,GFT 完全忽視了 2009 年春天和夏天“豬流感”的蔓延(最后證實 GFT 大部分預測的是冬天)���。接著����,系統開始去過度預測流感��。實際上��,它在 2013 年的峰值預測是真實的140%�����。最終����,谷歌直接停了整個項目�。
那么�,到底是哪里錯了呢?
有了 Ngrams����,人們會不再仔細考慮他們手中數據的來源和詮釋�。
谷歌檢索中的數據資源并不是一個靜止的野獸����。當谷歌開始自動補充檢索內容時���,用戶們開始習慣于接受提供的關鍵詞�����,扭曲 GFT 所看到的搜索�。在理解方面����,GFT 的工程師在最開始讓 GFT 采用面值數據;幾乎每一個檢索術語都被當成潛在的流感指示�����。有了數百萬個檢索術語后�,GFT 毫無疑問的開始過度詮釋一些季節性的詞語���,例如把“雪”來當做流感的證據����。
但是�����,當大數據不再被看做是萬金油時���,它才真正具有了顛覆性����。哥倫比亞大學的研究者 Jeffrey Shaman 和其他許多團隊在流感預測上利用 CDC 去補償 GFT 的誤差��,其結果比 CDC 和 GFT 兩者都要好��。根據 CDC 來看�����,Shaman 的團隊測試了這個季節已經出現的實際流感的模型�����。
通過將過去的短時間情況納入到考慮當中��,Shaman 和他的團隊精確調整了他們的數學模型�,去更好地預測未來���。團隊所需要的就是去嚴格地評估關于數據的假設����。
為了不讓我自己聽起來像一個反谷歌斗士���,我不得不再說下�,谷歌絕對不是唯一的一個犯錯者��。
我的妻子�����,一位經濟學家���,曾在一家統計整個互聯網的職位發布�,并收集整合成為國家勞動部門的統計數據的公司工作����。公司的經理曾經夸口他們分析了整個國家 80% 的職位�����,數據的數量致使他們盲目走向了誤解的方向���。
舉例來說����,一家當地的沃爾瑪也許會發布一個銷售助理職位�����,而它實際上想要招十個�,或者它也許會讓這個發布一直在掛在那里幾周��,直至人滿為止��。
因此����,相比于屈服在“大數據廢墟”下����,我們最好在心里保持我們的質疑——即使在有人提到海量文字支持的時候����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
