R數據分析案例:邏輯回歸
邏輯回歸��,也稱之為邏輯模型�����,用于預測二分結果變量����。在邏輯模型當中����,輸出結果所占的比率就是預測變量的線性組合����。
這篇文章將要使用下面這幾個包�����,而且你們需要保證在運行我所舉的例子的時候��,你已經把這些包都裝好了�。如果你還沒裝好這些包��,那么���,運行install.packages(“R包名稱”)這個操作����,或者你可能需要更新版本����,運行update.packages()�����。
library(aod)
library(ggplot2)
library(Rcpp)
版本說明:本文基于R3.2.3進行測試的��,一下是包的版本:
Rcpp:0.12.3 ggplot2:2.0.0 knitr:1.12.3
記?。罕疚囊庠谝阒廊绾斡孟嚓P的指令進行邏輯回歸分析���,而并沒有涵蓋所有研究人員可能會做的事情���,尤其是數據是沒有進行清洗和查閱的�����,而且假設并非最嚴謹��,其它方面也不會相當的標準�����。
案例
案例1: 假如我們對這些因素感興趣�����,它們表示政治候選人是否贏得選舉的因子��,其中��,我們把結果變量表示為0或1�����,也可以表達成贏或者輸�����。而預測變量的利益可由一場運動中所投入的金額表示���,或者是選舉人所花的時間���,再或者在職人員是否獲得足夠的支持�。
案例2:一個研究者可能會對GRE(研究生入學考試成績)���、GPA(大學平均績點)�,以及研究生學院的名譽感興趣����,因為它們影響學校的招生問題�。這里��,我們用允許/不允許這個二進制結果表示其因變量����。
數據的描述
對于我們接下來要進行的數據分析來說�����,我們要對案例2的入學問題進行深入的探討�����。我們有了通常情況下假設所產生的數據�����,而它們可從R的相關網站得到�����。記住����,當我們要調用相關函數導入數據的時候�,如果我們要具體表示一個硬盤驅動器的文件���,我們需要打上斜杠(/)��,而不是反斜杠(\)��。
-
mydata<-read.csv("http://www.ats.ucla.edu/stat/data/binary.csv")##view the first few rows of the datahead(mydata)
-
##admit gre gpa rank
-
-
## 1 0 380 3.61 3
-
## 2 1 660 3.67 3
-
## 3 1 800 4.00 1
-
## 4 1 640 3.19 4
-
## 5 0 520 2.93 4
-
## 6 1 760 3.00 2
這個數據集有二進制的結果(輸出值���,依賴)�����,它表示允許�����。這里有3個預測變量:gre��、gpa以及rank��。我們把gre和gpa看作是連續變量��。rank表示有4個值為1����。這里���,為0的那所學校聲望最高�,其它的這4所高校聲望最低�����。這時��,我們可以用summary()函數來匯總一下這個數據集的情況����,而且��,如果想要計算里面的標準差���,我們可以使用sapply()函數����,并在里面寫上sd來獲取其標準差����。
-
summary(mydata)
-
## admit gre gpa rank
-
## Min. :0.000 Min. :220 Min. :2.26 Min. :1.00
-
## 1st Qu.:0.000 1st Qu.:520 1st Qu.:3.13 1st Qu.:2.00
-
## Median :0.000 Median :580 Median :3.40 Median :2.00
-
## Mean :0.318 Mean :588 Mean :3.39 Mean :2.48
-
## 3rd Qu.:1.000 3rd Qu.:660 3rd Qu.:3.67 3rd Qu.:3.00
-
## Max. :1.000 Max. :800 Max. :4.00 Max. :4.00
-
sapply(mydata,sd)
-
## admit gre gpa rank
-
## 0.466 115.517 0.381 0.944
-
## two-way contingency table of categorical outcome and predictors## we want to make sure there are not 0 cellsxtabs(~ admit + rank, data = mydata)
-
## rank
-
## admit 1 2 3 4
-
## 0 28 97 93 55
-
## 1 33 54 28 12
你可能會考慮到的分析方法
接下來���,我會列舉一些你可能會用到的方法�����。這里所列舉的一些方法相對來說比較合理���,畢竟有些其他方法不能執行或者尤其局限性��。
1.邏輯回歸����,也是本文的重點
2.概率回歸�。概率分析所產生的結果類似于邏輯回歸��。我們可以依據我們的需要進行有選擇性的進行概率回歸或邏輯回歸��。
3.最小二乘法�����。當你使用二進制輸出變量的時候�����,這種模型就是常用于線性回歸分析的�,而且也可以用它來進行條件概率的運算����。然而�,這里的誤差(例如殘差)來自于線性概率模型��,而且會影響到異方差性最小二乘法回歸的正態誤差檢驗����,它也影響無效標準誤差和假設性分析��。想要了解更多關于線性概率模型的相關問題���,可以查閱Long(1997��,p.38-40)��。
4.雙組判別函數分析���。這是一個多元的方法處理輸出變量�。
5.Hotelling 的T2����。0/1的輸出結果轉換到分組變量中�����,而前一個預測值則成為輸出變量�����。這樣可以進行一個顯著性測試�,然而并沒有給沒個變量分別給一個系數��,而且這對于某個變量根據影響情況調整到其它變量的程度是不清楚的���。
使用邏輯模型
接下來的代碼�,通過使用glm()函數(廣義線性模型)進行相關評估�。首先�,我們要把rank(秩)轉換成因子���,并預示著rank在這里被視為分類變量��。
-
mydata$rank<-factor(mydata$rank)mylogit<-glm(admit~gre+gpa+rank,data=mydata,family="binomial")
由于我們得到了模型的名字(mylogit)�,而R并不會從我們的回歸中產生任何輸出結果��。為了得到結果���,我們使用summary()函數進行提?�。?
-
summary(mylogit)
-
##
-
## Call:
-
## glm(formula = admit ~ gre + gpa + rank, family = "binomial",
-
## data = mydata)
-
##
-
## Deviance Residuals:
-
## Min 1Q Median 3Q Max
-
## -1.627 -0.866 -0.639 1.149 2.079
-
##
-
## Coefficients:
-
## Estimate Std. Error z value Pr(>|z|)
-
## (Intercept) -3.98998 1.13995 -3.50 0.00047 ***
-
## gre 0.00226 0.00109 2.07 0.03847 *
-
## gpa 0.80404 0.33182 2.42 0.01539 *
-
## rank2 -0.67544 0.31649 -2.13 0.03283 *
-
## rank3 -1.34020 0.34531 -3.88 0.00010 ***
-
## rank4 -1.55146 0.41783 -3.71 0.00020 ***
-
## ---
-
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
-
##
-
## (Dispersion parameter for binomial family taken to be 1)
-
##
-
## Null deviance: 499.98 on 399 degrees of freedom
-
## Residual deviance: 458.52 on 394 degrees of freedom
-
## AIC: 470.5
-
##
-
## Number of Fisher Scoring iterations: 4
1.在上面的結果中�����,我們首先看到的就是call�����,這提示我們這時的R在運行什么東西�,我們設定了什么選項���,等等�。
2.接下來�����,我們看到了偏差殘差��,用于測量模型的擬合度���。這部分的結果顯示了這個分布的偏差殘差�,而針對每個使用在模型里的個案����。接下來����,我們討論一下如何匯總偏差估計��,從而知道模型的擬合結果����。
3.下一部分的結果顯示了相關系數����,標準誤差�,z統計量(有時也叫Wald Z統計量)��,以及它的相關結果���。gre和gpa都是同等重要的統計量�����,并作為rank的3個變量�。邏輯回歸系數給改變了在預測變量中增加一個單位的輸出結果誤差���。
對于gre����,每改變一個單位�,輸出結果的允許誤差(相對于不允許來說)增加0.002��。
對于gpa��,每改變一個單位�����,入學的研究生的允許誤差增加0.804���。
ranK的指示變量的觀察方法就有點不同了�����。例如��,層在本科學習過的在rank的值是2��,其它為1��,使之允許誤差變為-0.675����。
-
4.下面的圖表里的系數表示不錯的擬合效果����,包含了空值�、偏差殘差以及AIC��。后面�,我們就會學習如何用這些信息來判斷這個模型是否擬合�。
我們可以使用confint()函數來獲取相關的區間的預測信息��。對于邏輯回歸模型來說���,其置信區間時基于異形對數似然函數求出來的��。同樣����,我們得到的CL是基于默認方法求出的標準差算的�。
-
## CIs using profiled log-likelihoodconfint(mylogit)
-
## Waiting for profiling to be done...
-
## 2.5 % 97.5 %
-
## (Intercept) -6.271620 -1.79255
-
## gre 0.000138 0.00444
-
## gpa 0.160296 1.46414
-
## rank2 -1.300889 -0.05675
-
## rank3 -2.027671 -0.67037
-
## rank4 -2.400027 -0.75354
-
## CIs using standard errorsconfint.default(mylogit)
-
## 2.5 % 97.5 %
-
## (Intercept) -6.22424 -1.75572
-
## gre 0.00012 0.00441
-
## gpa 0.15368 1.45439
-
## rank2 -1.29575 -0.05513
-
## rank3 -2.01699 -0.66342
-
## rank4 -2.37040 -0.73253
我們可以調用aod包里的wald.test()函數來測試rank的所有影響��。圖表里的系數的順序和模型里的項順序是一樣的�。這樣很重要��,因為wald.test()函數就是基于這些模型的項順序進行測試的��。b提供了系數�����,而Sigma提供了誤差項的方差協方差矩陣�����,而且最終����,這些項告訴R哪些項用來進行測試�����,而在這種情況下��,第4���、5�、6這三項作為rank的層次進行測試�����。
-
wald.test(b=coef(mylogit),Sigma=vcov(mylogit),Terms=4:6)
-
## Wald test:
-
## ----------
-
##
-
## Chi-squared test:
-
## X2 = 20.9, df = 3, P(> X2) = 0.00011
卡方檢驗算出來的值是20.9�,這里涉及到3個自由度��,p值算出來是0.00011���,這預示著我們所假設的這些項之間具有顯著的影響效果���。
我們也可以測試而外的假設�,這些假設包含rank里不同層次的差異���。下面�,我們通過測試得知rank=2的測試結果和rank=3的時候一樣����。下面的第一行代碼創造的向量是1�����,這定義了測試里我們要執行的內容����。在這種情況下�����,我們想要測試rank=2和rank=3(即模型的第4項����、第5項)這兩個不同的項所產生的差異(減)��。為了對比這2項��,我們對其中一項乘以1�,另一項乘以-1����。其它項不包含在測試里����,所以它們統一都乘上0�。第二行代碼寫上L=1��,這告訴R基于向量為1時執行這次測試(并不是我們之前所選擇的進行測試)�����。
-
l<-cbind=""0=""0=""0=""1=""-1=""0=""wald=""test=""b="coef(mylogit),"sigma="vcov(mylogit),"l="l)"wald=""test:=""----------=""chi-squared=""test:=""x2="5.5,"df="1,"p="">X2)=0.019
卡方檢驗所在自由度為1的情況下算出來的結果為5.5���,并得出相關的p值為0.019�,這預示著rank=2和rank=3之間存在著顯著的差異��。
你一可以把系數指數化��,并從誤差率進行解讀����,而R會自動幫你算出來�����。為了要得到指數化系數���,你可以告訴R你想要指數化(exp)����,而R也會按照你的要求把它們指數化����,它屬于mylogit(coef(mylogit))的一部分�����。我們可以使用相同的誤差率以及它們的置信區間�,并可先前就把置信區間指數化��。把它們都放到其中一個圖表����,我們可以使用cbind系數和系數置信區間這些列整合起來����。
-
## odds ratios onlyexp(coef(mylogit))
-
## (Intercept) gre gpa rank2 rank3 rank4
-
## 0.0185 1.0023 2.2345 0.5089 0.2618 0.2119
-
## odds ratios and 95% CIexp(cbind(OR = coef(mylogit), confint(mylogit)))
-
## Waiting for profiling to be done...
-
## OR 2.5 % 97.5 %
-
## (Intercept) 0.0185 0.00189 0.167
-
## gre 1.0023 1.00014 1.004
-
## gpa 2.2345 1.17386 4.324
-
## rank2 0.5089 0.27229 0.945
-
## rank3 0.2618 0.13164 0.512
-
## rank4 0.2119 0.09072 0.471
現在���,我們可以說gpa增加了一個單位��,而研究生入學(反之就是沒有入學的)的誤差則在因子上增加2.23����。對于更多關于誤差率信息的解讀���,查看我們的FAQ頁 How do I interpret odds ratios in logistic regression? ����。注意���,當R產生了這個結果時����,關于誤差率的攔截一般都不被解讀��。
你也可以使用預測概率來幫助你解讀這個模型�����。預測概率可以均可由分類預測變量或連續預測變量計算出來����。為了算出預測概率�,我們首先要創建含有我們需要的獨立變量來創建新的數據框�。
我們將要開始計算每個rank值的預測概率的允許值����,并計算gre和gpa的平均值�����。首先�����,我們要創建新的數據框:
-
newdata1<-with(mydata,
-
data.frame(gre=mean(gre),gpa=mean(gpa),rank=factor(1:4)))
-
## view data framenewdata1
-
## gre gpa rank
-
## 1 588 3.39 1
-
## 2 588 3.39 2
-
## 3 588 3.39 3
-
## 4 588 3.39 4
這些值必須含有和你之前所創建的邏輯回歸分析相同的名字(例如�����,在這個例子中�����,gre的就必須命名為gre)��。既然���,我們現在已經創建好了我們需要進行運算的數據框���,那么我們可以告訴R根據這個來創建預測概率����。第一行代碼經過了壓縮�����,我們現在就把它分開來��,討論這些值是怎樣執行的�����。Newdata$rankP告訴R我們要根據數據集(數據框)的newdata1里的rankP創建一個新的變量剩余的指令告訴R這些rankP值應當使用prediction()函數進行預測�����。圓括號里的選項告訴R這些預測值應該基于分析mylogit進行預測��,mylogit的值源自newdata1以及它的預測值類型就是預測概率(type=”response”)���。第二行代碼列舉了數據框newdata1的值���,盡管它不是十分理想�����,而這就是圖表的預測概率�����。
-
newdata1$rankP<-predict(mylogit,newdata=newdata1,type="response")newdata1
-
## gre gpa rank rankP
-
## 1 588 3.39 1 0.517
-
## 2 588 3.39 2 0.352
-
## 3 588 3.39 3 0.219
-
## 4 588 3.39 4 0.185
在上面的預測結果中����,我們看到來自最好的名校(rank=1)并被接收到研究生的本科生預測概率是0.52�,而0.18的學生來自最低檔次的學校(rank=4)�,以gre和gpa作為平均值�。我們可以做相似的事情來創建一個針對不斷變化的變量gre和gpa的預測概率圖表�����。我們可以基于此作圖�����,所以我們可以在200到800之間創建100個gre值��,基于它的rank(1,2,3,4)�。
newdata2 <- with(mydata,
data.frame(gre = rep(seq(from = 200, to = 800, length.out = 100), 4),
gpa = mean(gpa), rank = factor(rep(1:4, each = 100))))
這些代碼所產生的預測概率(下面第一行)和之前算的一樣�����,除非我們還想要對標準差進行要求����,否則我們可以對置信區間作圖�����。我們可以對關聯規模進行預測��,同時反向變換預測值和置信區間的臨近值到概率中����。
-
newdata3<-cbind(newdata2,predict(mylogit,newdata=newdata2,type="link",se=TRUE))newdata3<-within(newdata3,{
-
PredictedProb<-plogis(fit)
-
LL<-plogis(fit-(1.96*se.fit))
-
UL<-plogis(fit+(1.96*se.fit))})
-
## view first few rows of final datasethead(newdata3)
-
## gre gpa rank fit se.fit residual.scale UL LL PredictedProb
-
## 1 200 3.39 1 -0.811 0.515 1 0.549 0.139 0.308
-
## 2 206 3.39 1 -0.798 0.509 1 0.550 0.142 0.311
-
## 3 212 3.39 1 -0.784 0.503 1 0.551 0.145 0.313
-
## 4 218 3.39 1 -0.770 0.498 1 0.551 0.149 0.316
-
## 5 224 3.39 1 -0.757 0.492 1 0.552 0.152 0.319
-
## 6 230 3.39 1 -0.743 0.487 1 0.553 0.155 0.322
當然�,使用圖像描繪預測概率來解讀和展示模型也是相當有用的��。我們會使用ggplot2包來作圖����。下面我們作圖描繪預測概率��,和95%置信區間���。
-
ggplot(newdata3,aes(x=gre,y=PredictedProb))+
-
geom_ribbon(aes(ymin=LL,ymax=UL,fill=rank),alpha=.2)+
-
geom_line(aes(colour=rank),size=1)
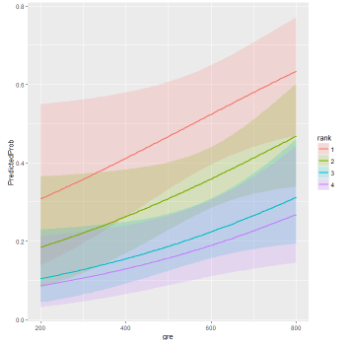
我們也許很想看到這個模型的擬合效果怎么樣�,而剛剛那樣做是非常有用的�,尤其是對比這些競爭的模型����。Summary(mylogit)所產生的結果包含了擬合系數(下面展示了其系數)�����,包含了空值���、偏差殘差和AIC��。模型擬合度的一個衡量標準就是整個模型的顯著程度�����。這個測試問了我們使用了預測值的模型是否比僅僅含有截距的模型(即��,空模型)更加顯著�,而這個測試里的統計量是含有預測值的預測擬合指數和空模型的差���,而且這個模型的統計量也是含有其自由度等于現有的模型(即���,模型里的預測變量個數)和空模型的自由度之差的卡方分布�����。為了要找到這兩個模型的偏差(即���,這個測試的統計量)�,我們可以使用下面的指令:文章來源cda數據分析培訓
-
with(mylogit,null.deviance-deviance)
-
## [1] 41.5
這兩個模型的自由度之差等于這個模型里預測變量的個數����,而且我們可以按照下面的方法獲取它:
-
with(mylogit,df.null-df.residual)
-
## [1] 5
最后����,我們提取一下p值:
-
with(mylogit,pchisq(null.deviance-deviance,df.null-df.residual,lower.tail=FALSE))
-
## [1] 7.58e-08
在自由度為5的情況下算出來的卡方是41.46�,而相關的p值則小于0.001�����。這告訴我們��,此模型的擬合效果比一個空模型所產生的擬合效果更加顯著�。這個��,我們有時稱它為似然比測試(偏差殘差為-2*log似然值)����。要看到它的對數似然�,我們可以這樣寫:
-
logLik(mylogit)
-
-
## 'log Lik.' -229 (df=6)
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
