R中大型數據集的回歸
眾所周知�,R語言是一個依賴于內存的軟件��,就是說一般情況下����,數據集都會被整個地復制到內存之中再被處理��。對于小型或者中型的數據集���,這樣處理當然沒有什么問題���。但是對于大型的數據集�����,例如網上抓取的金融類型時間序列數據或者一些日志數據���,這樣做就有很多因為內存不足導致的問題了���。
這里是一個具體的例子���。在 R 中輸入如下代碼�,創建一個叫 x 的矩陣和叫 y 的向量��。

如果用內置的 lm 函數對 x 和 y 進行回歸分析��,就有可能出現如下錯誤(當然�����,也有可能因為內存足夠而運行成功):

本文代碼運行的電腦的配置是:
CPU: Intel Core i5-2410M @ 2.30 GHz
Memory: 2GB
OS: Windows 7 64-bit
R: 2.13.1 32-bit
在 R 中��,每一個 numeric 數 占用 8 Bytes���,所以可以估算到 x 和 y 只是占用 5000000 7 8 / 1024 ^ 2 Bytes = 267 MB���,離運行的電腦的內存 2 GB 差很遠���。問題在于�����,運行 lm() 函數會生成很多額外的變量塞滿內存���。比如說擬合值和殘差��。
如果我們只是關心回歸的系數�����,我們可以直接用矩陣運算來計算 β^ :
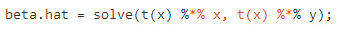
在本文運行的計算機中����,這個命令成功執行�����, 而且很快(0.6秒)(我使用了一個優化版本的 Rblas, 下載)�。然而�,如果樣本變得更加大了�,這個矩陣運算也會變得不可用�?��?梢怨浪愠?,如果樣本大小為 2GB / 7 / 8 Bytes = 38347922 ���,x 和 y 自己就會占用了全部內存�,更不要說其他計算過程中出現的臨時變量了���。
怎么破���?
一個方法就是用數據庫來避免占用大量內存�����,并且直接在數據庫中執行 SQL 語句等�����。數據庫使用硬盤來保存數據���,并且執行 SQL 語句時只是占用少量內存�����,所以基本上不用過于擔心內存占用����。不過有得有失���,要更加關注完成任務所占用的時間����。
R 支持很多數據庫���,其中 SQLite 是最輕量級和簡單的����。有一個 RSQLite 包���,允許用戶在 R 中對 SQLite 進行操作�����。這些操作包括了對 SQLite 數據庫進行讀寫����,執行 SQL 語句和在 R 中獲取執行結果���。所以����,如果我們能夠把需要的算法“翻譯”到 SQL 語句版本��,數據集的大小只受限于硬盤的大小和我們能夠接受的執行時間��。
采用上面的那個例子����,我這里說明我們會怎樣用數據庫和 SQL 語句來對數據集進行回歸���。首先我們要把數據塞到硬盤上面�。
上述代碼有很多 rm() 和 gc() ��,函數����,這些函數是用來移除沒有用的臨時變量和釋放內存��。當代碼運行完畢的時候��,你就會發現在你的工作空間中有一個 320M 左右的 regression.db 文件��。然后就是最重要的一步了:把回歸的算法轉化為 SQL���。
我們有
β^=(X′X)?1X′y
而且���,無論 n 有多大���,X′X 和 X′y 的大小總是 (p+1)?(p+1) ���。如果變量不是很多�����,R 處理矩陣逆和矩陣乘法還是很輕松的�����,所以我們的主要目標是用 SQL 來計算 X′X 和 X′y ��。
由于 X=(x0,x1,…,xp)�����,所以 X′X 可以表達為:
$$%
而每一個矩陣元素都可以用 SQL 來計算����,比如說:
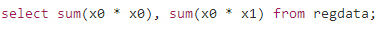
我們可以用 R 來生成 SQL 語句��,然后把語句發送到 SQLite :

我們可以檢查這個結果:
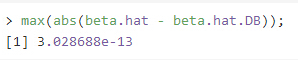
可以看出差別是舍入誤差導致的���。
以上計算用了大約 17 秒���,遠遠超出矩陣運算的時間���。不過它也幾乎沒有占用額外的內存空間��。實際上我們采用了“時間換空間”的策略���。此外��,你可能還發現��,我們可以通過多個對數據 庫的連接同步地計算 sum(x0*x0), sum(x0*x1), ..., sum(x5*x5) ���,所以如果你有一個多核的服務器(而且硬盤足夠快)��,你還可以通過適當的安排大量地減少運行時間���。數據分析培訓
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
