數據挖掘分類技術_數據挖掘分類
1���、過分擬合問題:
造成原因有:(1)噪聲造成的過分擬合(因為它擬合了誤標記的訓練記錄��,導致了對檢驗集中記錄的誤分類)�����;(2)根據少量訓練記錄做出分類決策的模型也容易受過分擬合的影響���。(由于訓練數據缺乏具有代表性的樣本��,在沒有多少訓練記錄的情況下���,學習算法仍然繼續細化模型就會產生這樣的模型����,當決策樹的葉節點沒有足夠的代表性樣本時����,很可能做出錯誤的預測)(3)多重比較也可能會導致過分擬合(大量的候選屬性和少量的訓練記錄最后導致了模型的過分擬合)
2�����、泛化誤差的估計:
(1)樂觀估計(決策樹歸納算法簡單的選擇產生最低訓練誤差的模型作為最終的模型)(2)悲觀誤差估計(使用訓練誤差與模型復雜度罰項的和計算泛化誤差)(3)最小描述長度原則(模型編碼的開銷加上誤分類記錄編碼的開銷)(4)估計統計上界(泛化誤差可以用訓練誤差的統計修正來估計����,因為泛化誤差傾向于比訓練誤差大�,所以統計修正通常是計算訓練誤差的上界)(4)使用確認集(如2/3的訓練集來建立模型�,剩下的用來做誤差估計)
3�、處理決策樹中的過分擬合:
A):先剪枝(提前終止規則):當觀察到的不純性度量的增益(或估計的泛化誤差的改進)低于某個確定的閾值時就停止擴展葉節點�����。B):初始決策樹按照最大規模生長�����,然后進行剪枝的步驟���,按照自底向上的方式修剪完全增長的決策樹��。修剪有兩種方法:(1)用新的葉節點替換子樹�,該葉節點的類標號由子樹下記錄中的多數類確定��;(2)用子樹中常見的分支替代子樹�。當模型不能再改進時終止剪枝步驟����。與先剪枝相比�����,后剪枝技術傾向于產生更好的結果�。
4���、評估分類器的方法:
(A):保持方法(用訓練集的一部分來做訓練一部分做檢驗�����,用檢驗的準確度來評估)(B)隨機二次抽樣(第一種方法進行K次不同的迭代�����,取其平均值)(C)交叉驗證(每個記錄用于訓練的次數相同��,并且用于檢驗恰好一次)(D)自助法(有放回抽樣)
1.1����、決策樹分類
算法思想:遞歸的選擇一個屬性對對象集合的類標號進行分類�����,如果分類到某一屬性時發現剩下的對象屬于同一類���,此時就不必再選擇屬性就行分類���,而只用創建一個葉節點并用共同的類來代表�����。否則����,繼續選擇下一屬性進行分類操作�,直到某一分類結果全在同一類或者沒有屬性可供選擇為止��。根據選擇屬性的順序可以將決策樹算法分為ID3,C4.5等�。其中�,決策樹算法CART只產生二元劃分�����,它們考慮創建K個屬性的二元劃分的所有2^(k-1)-1中方法��。圖1顯示了把婚姻狀況的屬性值劃分為兩個子集的三種不同的分組方法��。對于連續屬性來說��,測試條件可以是具有二元輸出的比較測試(A<v< font=”” style=”word-wrap: break-word;”>)或(A>=v)�,也可以是具有形如vi<=A<=vi+1(i=1,21��,…�,k)輸出的范圍查詢(如圖2所示)����。

問:預測集中的每條記錄的屬性取值集合是否就和訓練集的某一個記錄的屬性取值集合相等�����?
答:不一定�,一般來說是不可能的����。但是建立的決策樹一定包含該取值集合(但是可能范圍會大些)�。因為決策樹建過程是只要當前的所有對象屬于同一個標號就不再繼續選擇屬性了�����,所以����,實際上建立的決策樹所包含的對象是比訓練集中的對象要多得多的��,這些多余的對象可能就包含當前的預測對象����。這也是決策樹能夠用來進行分類的原因���。
決策樹歸納的特點:
(1)找到最優決策樹是NP完全問題�;(2)采用避免過分擬合的方法后決策樹算法對于噪聲的干擾具有相當好的魯棒性����。
1.2�����、基于規則的分類
基于規則的分類使用一組if…then規則來分類記錄的技術��。算法思想:先從訓練集生成規則集合�����,規則是使用合取條件表示的:如規則ri:(條件i)->yi,其中r1是如下形式:r1:(胎生=否)^(飛行動物=是)->鳥類;其中左邊稱為規則前件或前提����;規則右邊稱為規則后件�。如果規則r的前件和記錄x的屬性匹配��,則稱r覆蓋x��。當r覆蓋給定的記錄時���,稱r被激發或被觸發�。建立規則集合后�,就進行分類�。對每個待分類的記錄和規則集合中的每條規則進行比較�,如果某條規則被觸發�,該記錄就被分類了����。
問:由于規則集中的規則不一定是互斥的���,所有有可能分類的時候某條記錄會屬于多個類(也就是說某條記錄會同時觸發規則集中的超過1條的過則���,而被觸發的規則的類標號也不一樣)����,這種情況如何處理:
答:有兩種辦法解決這個問題���。(1)有序規則���。將規則集中的規則按照優先級降序排列��,當一個測試記錄出現時�,由覆蓋記錄的最高秩的規則對其進行分類����,這就避免由多條分類規則來預測而產生的類沖突問題(2)
無序規則�。允許一條測試記錄觸發多條分類規則��,把每條被觸發規則的后件看作是對相應類的一次投票���,然后計票確定測試記錄的類標號�����。通常把記錄指派到得票最多的類����。
問:假設現在有一個記錄它不能觸發規則集合中的任何一個規則���,那么它該如何就行分類呢��?
答:解決辦法也有兩個:(1)窮舉規則���。如果對屬性值的任一組合��,R中都存在一條規則加以覆蓋�,則稱規則集R具有窮舉覆蓋����。這個性質確保每一條記錄都至少被R中的一條規則覆蓋����。(2)如果規則不是窮舉的�,那么必須添加一個默認規則rd:()->yd來覆蓋那些未被覆蓋的記錄�。默認規則的前件為空����,當所有其他規則失效時被觸發�。yd是默認類�����,通常被指定為沒有被現存規則覆蓋的訓練記錄的多數類�。
規則的排序方案:
(1)基于規則的排序方案:根據規則的某種度量對規則排序���。這種排序方案確保每一個測試記錄都是有=由覆蓋它的“最好的”規則來分類��。(2)基于類的排序方案�����。屬于同一類的規則在規則集R中一起出現���。然后這些規則根據它們所屬的類信息一起排序�����。同一類的規則之間的相對順序并不重要��,因為它們屬于同一類���。(大多數著名的基于規則的分類器(C4.5規則和RIPPER)都采用基于類的排序方案)���。
建立規則的分類器:
(1)順序覆蓋�����。直接從數據中提取規則�,規則基于某種評估度量以貪心的方式增長����,該算法從包含多個類的數據集中一次提取一個類的規則�。在提取規則時����,類y的所有訓練記錄被看作是正例�,而其他類的訓練記錄則被看作反例���。如果一個規則覆蓋大多數正例��,沒有或僅覆蓋極少數反例��,那么該規則是可取的�。一旦找到這樣的規則����,就刪掉它所覆蓋的訓練記錄�����,并把新規則追加到決策表R的尾部(規則增長策略:從一般到特殊或從特殊到一般)(2)RIPPER算法����。(和前面那個差不多�����,只是規則增長是從一般到特殊的���,選取最佳的合取項添加到規則前件中的評判標準是FOIL信息增益��,直到規則開始覆蓋反例時�,就停止添加合取項���。而剪枝是從最后添加的合取項開始的�,給定規則ABCD->y�����,先檢查D是否應該被刪除���,然后是CD�����,BCD等)
基于規則的分類器的特征:
(1)規則集的表達能力幾乎等價于決策樹���,因為決策樹可以用互斥和窮舉的規則集表示����。(2)被很多基于規則的分類器(如RIPPER)所采用的基于類的規則定序方法非常適合于處理不平衡的數據集����。
1.3���、最近鄰分類器
算法思想:將要測試的記錄與訓練集的每條記錄計算距離�,然后選擇距離最小的K個�����,將K個記錄中的類標號的多數賦給該測試記錄�����,如果所有的類標號一樣多�����,則隨機選擇一個類標號���。該算法的變種:先將訓練集中所有的記錄中相同類標號的記錄算出一個中心記錄���,然后將測試記錄與中心記錄算距離�,取最小的K個就行(這個方法大大的減少了計算量�����,原來的算法計算量太大了)�。
問:該算法沒有學習的過程??�?
答:是的����。所以這個算法稱為消極學習方法��,而之前的那些算法稱為積極學習方法����。
最近鄰分類器的特征
最近鄰分類器基于局部信息進行預測��,而決策樹和基于規則的分類器則試圖找到一個擬合整個輸入空間的全局模型��。正因為這樣的局部分類決策����,最近鄰分類器(K很小時)對噪聲非常敏感���。
1.3���、貝葉斯分類器
貝葉斯定理是一種對屬性集合類變量的概率關系建模的方法�����,是一種把類的先驗知識和從數據集中收集的新證據相結合的統計原理���。貝葉斯分類器的兩種實現:樸素貝葉斯和貝葉斯信念網絡��。貝葉斯定理(如下)(樸素貝葉斯分類的前提假設是屬性之間條件獨立):
P(Y | X) = P(X | Y)P(Y) / P(X)(1-1)
樸素貝葉斯分類分類思想
假設(1-1)中的X為要分類的記錄�����,而Y是訓練集中的類標號集合��,要將X準確分類就必須使對特定的X和所有的分類標號yi���,讓P(yi|X)最大的yi即為測試記錄的類標號�。由(1-1)知道要讓左邊最大就是讓后邊最大�,而因為X是特定的所以就是使P(X | Y)P(Y)(1-2)最大���。此時的yi即為測試記錄的類標號�。而要計算(1-2)因為各個屬性是獨立的���,所以直接乘即可(具體見hanjiawei的書P203例6-4)���。
問:在計算(1-2)時假設出現某項是零了怎么辦�����?
答:有兩種方法:(1)拉普拉斯校準或拉普拉斯估計法���。假定訓練數據庫D很大�,使得需要的每個技術加1造成的估計概率的變化可以忽略不計�����,但可以方便的避免概率值為零的情況��。(如果對q個計數都加上1���,則我們必須在用于計算概率的對應分母上加上q)�����。(2)條件概率的m估計�����。P(Xi | Yi) = (nc + mp) / (n + m)其中���,n是類yi中的實例總數�,nc是類yi的訓練樣例中取值xi的樣例數��,m是稱為等價樣本大小的參數��,而p是用戶指定的參數���。如果沒有訓練集(即n=0)則P(xi|yi)=p�。因此p可以看作是在yi的記錄中觀察屬性值xi的先驗概率���。等價樣本大小決定先驗概率p和觀測概率nc/n之間的平衡���。
樸素貝葉斯分類器的特征
(1)面對孤立的噪聲點����,樸素貝葉斯分類器是健壯的�。因為在從數據中估計條件概率時��,這些點被平均�。通過在建模和分類時忽略樣例�����,樸素貝葉斯分類器也可以處理屬性值遺漏問題�����。(2)面對無關屬性�����,該分類器是健壯的���。如果xi是無關屬性�����,那么P(Xi|Y)幾乎變成了均勻分布�。Xi的條件概率不會對總的后驗概率產生影響��。(3)相關屬性可能會降低樸素貝葉斯分類器的性能�����,因為對這些屬性�����,條件獨立假設已不成立�。
貝葉斯信念網絡(該方法不要求給定類的所有屬性都條件獨立�����,而是允許指定哪些屬性條件獨立):
貝葉斯信念網絡(BBN)
這個方法不要求給定類的所有屬性都條件獨立�����,而是允許指定哪些屬性條件獨立�。貝葉斯信念網絡(用圖形表示一組隨機變量之間的概率關系)建立后主要有兩個主要成分:(1)一個有向無環圖�����,表示變量之間的依賴關系(2)一個概率表(每個節點都有)�,把各節點和它的直接父節點關聯起來���。一個貝葉斯信念網路的大體樣子如下(左邊):其中表右表只是LungCancer節點的概率表
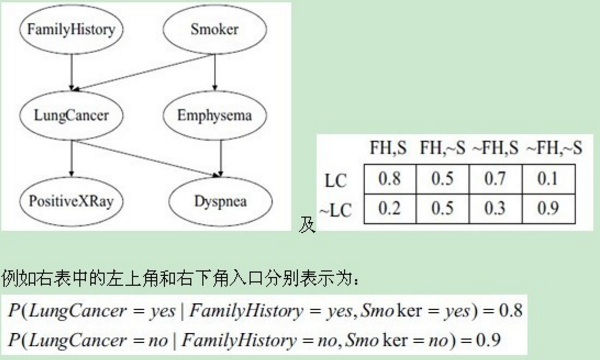
貝葉斯信念網絡主要思想
根據已經建立好的貝葉斯信念網絡和每個節點的概率表來預測未知記錄的分類���。主要是按照已建立好的網絡根據節點的概率計算先驗概率或后驗概率�����。計算概率的方法和前面的樸素貝葉斯計算過程相差無多���。
貝葉斯信念網絡的建立
網路拓撲結構可以通過主觀的領域專家知識編碼獲得�,由于要尋找最佳的拓撲網路有d��!種方案計算量較大�����,一種替代的方法是把變量分為原因變量和結果變量�����,然后從各原因變量向其對應的結果變量畫弧�����。
BBN的特點:
(1)貝葉斯網路很適合處理不完整的數據���。對屬性遺漏的實例可以通過對該屬性的所有可能取值的概率求或求積分來加以處理��。(2)因為數據和先驗知識以概率的方式結合起來了��,所以該方法對模型的過分擬合問題是非常魯棒的���。
問:樸素貝葉斯沒有學習的過程�,那么是否可以說樸素貝葉斯是消極學習法分類��?
答:(1)樸素貝葉斯只是貝葉斯分類的一種實現形式�����,而實現形式還有貝葉斯網絡但是貝葉斯網絡是有學習過程的��。所以不能說貝葉斯分類時消極學習法�。(2)其實樸素貝葉斯是消極學習方法
1.4�����、人工神經網絡(ANN)
ANN是有相互連接的結點和有項鏈構成��。
(1)感知器����。感知器的一般模型如下所示:
分類思想:Ij = Sum(Wi*Oi) + a���,其中Ij為特定的類標號,Wi為輸入向量的權重,Oi為輸入屬性的值�����,a為偏置因子�。用這個模型就可以對未知的記錄分類���。圖中的激活函數的用處是:將某個Ij的計算值映射到相應的類標號中��。在訓練一個感知器時���,最初將所有的權重隨機取值���,而訓練一個感知器模型就相當于不斷的調整鏈的權值��,直到能擬合訓練數據的輸入輸出關系為止����。其中權值更新公式如下:Wj(k+1) = Wjk + r(yi – yik)Xij�。其中Wk是第k次循環后第i個輸入鏈上的權值����,參數r稱為學習率����,Xij是訓練樣例的Xi的第j個屬性值���。學習率值在0到1之間���,可以用來控制每次循環時的調整量�。自適應r值:r在前幾次循環時值相對較大�����,而在接下來的循環中逐漸減少�。
(2)多層人工神經網絡
一個多層人工神經網絡的示意圖如下兩圖所示:其中左邊是多類標號情況���,右邊是一類情況����。
ANN學習中的設計問題:(1)確定輸入層的結點數目(2)確定輸出層的結點數目(3)選擇網絡拓撲結構(4)初始化權值和偏置(隨機值)(5)去掉有遺漏的訓練樣例��,或者用最合理的值來代替�����。
ANN的特點:
(1)至少含有一個隱藏層的多層神經網絡是一種普適近似�����,即可以用來近似任何目標函數����。(2)ANN可以處理冗余特征�����,因為權值在訓練過程中自動學習�����。冗余特征的權值非常小�����。(3)神經網絡對訓練數據中的噪聲非常敏感����。噪聲問題的一種方法是使用確認集來確定模型的泛化誤差����;另一種方法是每次迭代把權值減少一個因子�����。(4)ANN權值學習使用的梯度下降方法經常會收斂到局部最小值�。避免方法是在權值更新公式中加上一個自動量���。
1.5���、支持向量機(SVM)
它可以很好的應用于高維數據����,避免了維災難問題��,它使用訓練實例的一個子集來表示決策邊界���,該子集稱作支持向量�。SVM尋找具有最大邊緣的超平面(比那些較小的決策邊界具有更好的泛化誤差)�����,因此也經常稱為最大邊緣分類器�����。最大邊緣的決策邊界如韓佳偉書P220圖6-21所示:分類思想(1)在線性可分的情況下就是要學習(找)到這個最大邊緣的決策邊界(通過線性規劃或拉格朗日乘子來求得)�����,當然也允許有一定的誤差(可以有少量的結點分在了它不該在的類�����,但只要在能夠容忍的范圍就行)��,然后利用這個最大邊緣的決策邊界來分類�,結果落在一邊的為一類�,在另一邊的為另一類(2)在線性不可分的情況下��,將原來的數據從原先的坐標空間X轉換到一個新的坐標空間中��,從而可以在變換后的坐標空間中使用一個線性的決策邊界來劃分樣本的類標號(主要技術包括:非線性變換����、核技術和Mercer定理)���。
SVM的特點:
(1)SVM學習問題可以表示為凸優化問題���,因此可以利用已知的有效算法發現目標函數的全局最小值(2)通過對數據中每個分類屬性值引入一個啞變量���,SVM可以應用于分類數據
1.6��、組合方法
該方法聚集多個分類器的預測來提高分類的準確率����,這些技術稱為組合或分類器組合方法��。組合方法由訓練數據構建一組基分類器��,然后通過對每個分類器的預測進行投票來進行分類�。預測過程如下所示:
由上面的分類過程可以看出當誤差率大于0.5時�����,組合分類器的性能比基分類器更差���。組合分類器的性能優于單個分類器必須滿足兩個必要條件:(1)基分類器之間應該是相互獨立的(輕微相關也行)�����;(2)基分類器應當好于隨機猜測分類器����。
構建組合分類器的方法
(1)通過處理訓練數據集�����。根據某種抽樣分布�,通過對原始數據進行再抽樣來得到多個訓練集(如有放回隨機抽樣)��。一般得到的訓練集和原始數據集一樣大�。然后使用特定的學習算法為每個訓練集建立一個分類器(裝袋和提升是兩種處理訓練集的組合方法)��。(2)通過處理輸入特征���。通過選擇輸入特征的子集來形成每個訓練集�����。對那些含有大量冗余特征的數據集�,這種方法的性能非常好(隨機深林就是一種處理輸入特征的組合方法�����,它使用決策樹作為基分類器)����。(3)通過處理類標號��。這種方法適用于類數足夠多的情況�。這種方法先將所有的類劃分為兩個大類�����,然后將兩個大類的每個大類劃分為兩個次大類……�,預測時按照前面的分類遇到一個分類結點得一票�,最后得票數最多的那個就是最終的類����。(4)通過處理學習算法�。如果在同一個訓練集上用同一個學習算法得到的分類器模型不一樣�����,就可以多做幾次以建立多個基分類器��。
組合方法對于不穩定的分類器效果很好���。不穩定分類器是對訓練數據集微小的變化都很面干的基分類器���。不穩定分類器的例子包括決策樹����、基于規則的分類器和人工神經網絡����。
(1)裝袋��。裝袋又稱自助聚集����,是一種根據均勻分布從數據集中重復抽樣的(有放回的)技術�。每個自助樣本集都和原始數據一樣大���。然后對每個樣本集訓練一個基分類器�����,訓練k個分類器后�����,測試樣本被指派到得票最高的類����。用于噪聲數據��,裝袋不太受過分擬合的影響���。
(2)提升��。是一個迭代過程����,用來自適應地改變樣本的分布�����,使得基分類器聚焦在那些很難分的樣本上����。例如開始時所有的樣本都賦予相同的權值1/N, 然后按這個概率抽取樣本集�,然后得到一個分類器���,并用它對原始數據集中的所有樣本進行分類�。每一輪結束時更新樣本的權值��。增加錯誤分類的樣本的權值��,減少被正確分類的樣本的權值�,這迫使分類器在隨后的迭代中關注那些很難分類的樣本�����。通過聚集每一輪得到的分類器��,就得到最終的分類器�����。目前有幾個提升算法的實現����,它們的差別在于:(1)每輪提升結束時如何更新訓練樣本的權值���;(2)如何組合每個分類器的預測���。
Android:在該算法中�,基分類器Ci的重要性依賴于它的錯誤率���。算法思想:首先初始化N個樣本的權值(w = 1/N)��,然后對于第i次(總共k次����,產生k個基分類器)提升(其他次一樣)��,根據w通過對D進行有放回抽樣得到訓練集Di,然后根據Di得到一個基分類器Ci,用Ci對訓練集D中的樣本進行分類���。然后計算分類的加權誤差���,如果加權誤差大于0.5�����,就將所有樣本的權值重設為為1/N�,否則用ai更新每個樣本的權值��。得到k個基分類器后�����,然后合并k個基分類器得到預測結果��。Android 算法將每一個分類器Cj的預測值根據 aj進行加權����,而不是使用多數表決的方案����。這種機制允許Android 懲罰那些準確率很差的模型���,如那些在較早的提升輪產生的模型�。另外��,如果任何中間輪產生高于50%的誤差����,則權值將被恢復為開始的一致值wi = 1/N�����,并重新進行抽樣���。Android 算法傾向于那些被錯誤分類的樣本����,提升技術很容易受過分擬合的影響���。
(3)隨機森林���。它是一類專門為決策樹分類器設計的組合方法����。它結合多顆決策樹做出預測���。與Android算法使用的自適應方法不同��,Android中概率分布是變化的�,以關注難分類的樣本�,而隨機森林則采用一個固定的概率分布來產生隨機向量�����。隨機森林與裝袋不同之處在于(1)裝袋可以用任何分類算法產生基分類器而隨機森林只能用決策樹產生基分類器�。(2)裝袋最后組合基分類器時用的投票方法二隨機森林不一定用投票���。(3)隨機森林的每個基分類器是一個樣本集的隨機向量而裝袋是用的有放回抽樣來產生樣本���。隨機森林的的決策樹在選擇分類屬性時��,隨機選擇F個輸入特征(而不是考察所有可用的特征)來對決策樹的節點進行分裂����,然后樹完全增長而不進行任何剪枝�,最后用多數表決的方法來組合預測(這種方法叫Forest-RI�����,其中RI是指隨機輸入選擇)����。注意此時如果F太小��,樹之間的相關度就減弱了�����,F太大樹分類器的強度增加��,折中通常F取log2d + 1�,其中d是輸入特征數���。如果d太小����,可以創建輸入特征的線性組合����,在每個節點����,產生F個這種隨機組合的新特征�����,并從中選擇最好的來分裂節點���,這種方法稱為Forest-RC�����。隨機森林的分類準確率和Android差不多����,但是隨機森林對噪聲更加魯棒��,運行速度也快得多�。
1.6��、不平衡類問題
有時候需要準確分類訓練集中的少數類而對多數類不是太關心�����。如不合格產品對合格產品���。但是這樣建立的模型同時也容易受訓練數據中噪聲的影響�。
新定的指標(過去的指標不頂用如:準確率不頂用):真正率(靈敏度)��、真負率(特指度)����、假正率���、假負率���、召回率�、精度����。
(1)接受者操作特征(ROC)曲線�����。該曲線是顯示分類器真正率和假正率之間的折中的一種圖形化方法�����。在一個ROC曲線中�,真正率沿y軸繪制��,而假正率沿x軸繪制�����。一個好的分類模型應該盡可能靠近圖的左上角���。隨機預測分類器的ROC曲線總是位于主對角線上��。
ROC曲線下方的面積(AUC)提供了評價模型的平均性能的另一種方法�����。如果模型是完美的���,則它在ROC曲線下方的面積等于1���,如果模型僅僅是簡單地隨機猜測���,則ROC曲線下方的面積等于0.5���。如果一個模型好于另一個���,則它的ROC曲線下方的面積較大�����。為了繪制ROC曲線��,分類器應當能夠產生可以用來評價它的預測的連續值輸出�,從最有可能分為正類的記錄到最不可能的記錄��。這些輸出可能對應于貝葉斯分類器產生的后驗概率或人工神經網絡產生的數值輸出��。(繪制ROC曲線從左下角開始到右上角結束���,繪制過程見hanjiawei P243)����。
(2)代價敏感學習�����。代價矩陣對將一個類的記錄分類到另一個類的懲罰進行編碼����。代價矩陣中的一個負項表示對正確分類的獎勵��。算法思想:將稀有的類標號預測錯誤的代價權值設為很大�,則在計算總代價時��,它的權值較高�����,所以如果分類錯誤的話���,代價就較高了�。代價敏感度技術在構建模型的過程中考慮代價矩陣���,并產生代價最低的模型���。例如:如果假負錯誤代價最高����,則學習算法通過向父類擴展它的決策邊界來減少這些錯誤��。
(2)代價敏感學習. 主要思想:改變實例的分布�����,而使得稀有類在訓練數據集得到很好的表示����。有兩種抽樣方法:第一種選擇正類樣本的數目和稀有樣本的數目一樣多�����,來進行訓練(可以進行多次�,每次選擇不同的正類樣本)����。第二種復制稀有樣本(或者在已有的稀有樣本的鄰域中產生新的樣本)使得和正類樣本一樣多�����。注意�����,第二種方法對于噪聲數據可能導致模型過分擬合�����。
1.6�、多類問題(結果類標號不止兩個
解決方法:(1)將多類問題分解成K個二類問題��。為每一個類yi Y(所有的類標號集合)創建一個二類問題���,其中所有屬于yi的樣本都被看做正類��,而其他樣本都被看做負類���。然后構建一個二元分類器�����,將屬于yi的樣本從其他的類中分離出來�。(稱為一對其他(1-r)方法)�。(2)構建K(K-1)/2個二類分類器���,每一個分類器用來區分一對類(yi�,yj)��。當為類(yi����,yj)構建二類分類器時��,不屬于yi或yj的樣本被忽略掉(稱為一對一(1-1)方法)�。這兩種方法都是通過組合所有的二元分類器的預測對檢驗實例分類����。組合預測的典型做法是使用投票表決�����,將驗證樣本指派到得票最多的類�。
糾錯輸出編碼(ECOC):前面介紹的兩種處理多類問題的方法對二元分類的錯誤太敏感�����。ECOC提供了一種處理多類問題更魯棒的方法�。該方法受信息理論中通過噪聲信道發送信息的啟發�?����;舅枷胧墙柚诖a字向傳輸信息中增加一些冗余�,從而使得接收方能發現接受信息中的一些錯誤��,而且如果錯誤量很少�,還可能恢復原始信息���。具體:對于多類學習����,每個類yi用一個長度為n的唯一位串來表示���,稱為它的代碼字��。然后訓練n個二元分類器����,預測代碼子串的每個二進制位�����。檢驗實例的預測類由這樣的代碼字給出�����。該代碼字到二元分類器產生的代碼字海明距離最近(兩個位串之間的海明距離是它們的不同的二進制位的數目)���。糾錯碼的一個有趣的性質是��,如果任意代碼字對之間的最小海明距離為d��,則輸出代碼任意 (d-1) / 2個錯誤可以使用離它最近的代碼字糾正��。注意:為通信任務設計的糾正碼明顯不同于多類學習的糾正嗎���。對通信任務��,代碼字應該最大化各行之間的海明距離���,使得糾錯可以進行����。然而���,多類學習要求將代碼字列向和行向的距離很好的分開�����。較大的列向距離可以確保二元分類器是相互獨立的����,而這正是組合學習算法的一個重要要求��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
