[從產品角度學EXCEL 02]-EXCEL里的樹形結構
前言請看:
0 為什么要關注Excel的本質
1 excel是怎樣運作的
本文僅由尾巴本人發布于特定網站�。不接受任何無授權轉載���,如需轉載�,請先聯系我���,非常感謝�。
2 Excel里的樹形結構
這段時間��,上海街邊的樹上陸陸續續長出了嫩芽����,放眼望去有各種層次的綠色����,格外好看��。我們今天的話題�,恰好也與樹有關�。只不過��,樹都是往天空伸展枝葉的�����,而我們這里討論的‘樹’���,卻是由根部出發�,逐行逐行往下延展�、伸展�����。
還記得上一個章節里�����,我們對一個excel文件解壓縮后�,發現了若干個xml文件嗎�?
xml本質上是一種使用樹形結構存儲信息的文檔��。它由一個根節點root開始���,逐層逐層長枝節���,并給每一層都打了個標簽�����,讓xml解析器可以快速定位信息的內容��。而每一層以及每一個底部的節點����,都是這些信息的一個分類屬性����。我們了解了它們的屬性和層級��,也就了解這顆結構樹長成什么樣子���。
正因為xml的結構與層級是如此重要���,在進一步講單元格之前�����,我們很有必要先剖析看看excel xml樹的結構��,從大體上再來理解一下excel儲存文件的方式��。
需要注意的是�,這一章節大概是整個系列里涉及最多編程的章節了�����。如果各位對編程不是特別感興趣����,可以先跳過這一節�����,去看后面的內容����。不過按照我個人的經驗來說�����,不管你是用excel做一些簡單的數據處理��,還是想要在數據分析行業里走得穩妥一些�,了解了解編程�,只會有好處而沒有壞處�����。尤其是編程的一些思想����,如妥善地設計接口�����,分隔各個功能塊等���,即使你用excel處理數據��,這些也對你十分有好處���。
言歸正傳吧����。我們回過頭來再看看excel解壓縮以后的xml文件�����。
讓我們隨意打開一個xml文件�����,一串串密密麻麻的字符就這樣跳了出來����。
對于不熟悉xml架構的人來說��,我們只會看到眼花繚亂的括號�����,等號��,引號��。但是如果你對xml有點理解����,你就會知道�,這一系列的標點符號框起了一個個xml的數據結構����。
對于xml來說���,每一個層級都是由<標簽 屬性=ABC>內容信息</標簽>構成的���。有的內容信息里又會再次嵌套一層標簽層級����,重重相疊�����,從根部開始向下延展出了無數枝葉��,構成了一棵看似錯綜復雜����,卻是層次分明的xml樹����。人們只要定位到某一個枝葉���,就可以迅速把這個枝葉下的特定信息取出來����。而要搞懂這棵xml樹長什么樣子�����,首先就要搞懂說這棵樹是有哪些層級����,各個層級叫什么����,有什么內容���。
但是各位再回顧看看上面的截圖��,一長串一長串的代碼��,你當然可以一個個去判斷說�����,啊����,根標簽從worksheet開始�,下面有selection層級���,有f層級等等��,但是這樣子做�����,不僅低效��,而且會有遺漏�����。
請各位在學習excel時�,隨時記住一個原則���,那就是可以不要手工去做的事情��,就不要手工去做����。寧愿自己腦子廢點腦力構思最優方法���,也不要直接就開始機械的作業�。
那么��,在這里�����,面臨這個要人工一個個看標簽的艱巨任務時�����,我們該如何是好呢�?
在這里跟大家再普及一個概念的是�,xml嘛����,除了微軟在用于office系列文檔儲存格式以外��,它還廣泛應用于各種網頁設計領域��。而在網頁獲取信息這一塊�,我們天然有很多工具可以通過讀取html或者xml源代碼�����,解析它們的結構����,進行數據提取工作(高級點叫法即網絡爬蟲)
所以對于這里的excel xml源文件����,我們自然可以應用各種爬蟲工具�,把xml的框架給找出來��。
我 用的比較熟的應該是R語言的rvest包爬蟲了�����,查了一下它的文檔�,有一個叫xml_structure的�,可以直接把xml文件的標簽層次給讀出來��,而 xml_nodes/xml_attr等�,又可以把里面特定的標簽內容給分層讀出來���。那么寫一段代碼�����,幫我把excel的xml源文件里的層級與內容弄出 來����,那就省了我很大的心力啦^^
因為R語言代碼并不是我們的重點�����,所以我把源代碼放在文章末尾的擴展閱讀里了��,有需要的可以去看看�����,也可以用其他語言寫寫����。有的時候只要學會一點點的編程��,就能大大的改善各位的工作效率��。要用好工具而不是被工具玩�,是我希望在這系列excel教程里告訴大家的一個點�����。
那么言歸正傳����。請各位看看下面這個用R語言跑出來的csv文件截圖�����。
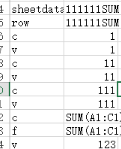
左列是我們的標簽名����,右列是我們標簽里面包含的文本�����。通過這個文件�����,我們就可以很容易知道各個標簽里存放了什么文本信息�����。我們會發現row下面是一串串的c/v/f����。而c與v的信息幾乎完全一樣��。
另外���,在r里�����,我們可以通過xml_structure輸出xml文件的結構����。這兩個結合起來�����,我為各位繪制了一張sheet1.xml的樹形結構圖:
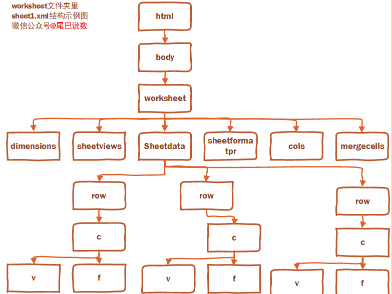
各位可以看到�,在worksheet文件夾里的sheet1.xml��,是在sheetdata里按照row為標簽層級�����,存放了若干行的數據����。而行又以 c(cell)為導向�,存放了單元格的v (value)和f(函數)�。有多少行����,在sheet1.xml里就有多少row��,一個row有若干個有效單元格�����,就會有若干個c����。
從這個角度看excel����,會不會對excel的產品設計層次有了進一步的理解呢���?
另外����,上面的截圖沒有出示的一點是����,在worksheet這個文件夾里��,數字是直接存在各個sheetxxx.xml里的��,而字符類文本����,卻是單獨存放在外面的SharedString.xml里��。
嘿嘿�,數字和文本的存放格式不一樣��,各位想到了什么�?有沒有虎軀一震���,想到了excel里因為數字和文本的不同��,帶來的各種不便����?
在前面啰嗦完為什么要寫這個系列��,以及excel是怎么工作以后�����,我們終于把拼圖最重要的一塊——解讀xml補上了��。
R語言解析XML源代碼:
setwd("~/excel/")
library(rvest)
#代碼用于《從產品角度學EXCEL》系列文章,XML解析
# read xml in zip files
get_xmllist<-function(access){
list<-list.files(access,full.names=TRUE,pattern = "xml$",recursive = TRUE)
list_name<-gsub(as.character(access),"",list)
list_name<-gsub("\\/|\\.|\\[|\\]","-",list_name)
list_name<-gsub("\\-\\-","-",list_name)
list<-data.frame(list,list_name,stringsAsFactors = FALSE)
list
}
# read xml structure
get_structure<-function(xmlfile){
data<-xml(xmlfile,encoding="UTF-8")
data<-data %>% html_nodes("*")
output<-cbind(node_names=data %>% html_tag(),
node_text=data %>% html_text())
output<-data.frame(output)
output
}
write_result<-function(dataframe,name){
write.csv(dataframe,paste0("./Output/",name,".csv"),row.names=FALSE)
}
#use these three function
xml_list<-get_xmllist("./sample u.xlsx/")
for (i in 1:nrow(xml_list)){
data<-get_structure(xml_list$list[i])
write_result(data,xml_list$list_name[i])
}
#write the structure
xml_structure(html(xml_list$list[8]))
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
