R語言解讀多元線性回歸模型
在許多生活和工作的實際問題中����,影響因變量的因素可能不止一個�����,比如對于知識水平越高的人����,收入水平也越高���,這樣的一個結論���。這其中可能包括了因為更好的家庭條件�����,所以有了更好的教育;因為在一線城市發展�,所以有了更好的工作機會;所處的行業趕上了大的經濟上行周期等��。要想解讀這些規律����,是復雜的�、多維度的��,多元回歸分析方法更適合解讀生活的規律��。
由于本文為非統計的專業文章��,所以當出現與教課書不符的描述�����,請以教課書為準�。本文力求用簡化的語言����,來介紹多元線性回歸的知識��,同時配合R語言的實現��。
對比一元線性回歸����,多元線性回歸是用來確定2個或2個以上變量間關系的統計分析方法����。多元線性回歸的基本的分析方法與一元線性回歸方法是類似的��,我們首先需要對選取多元數據集并定義數學模型����,然后進行參數估計�����,對估計出來的參數進行顯著性檢驗���,殘差分析��,異常點檢測���,最后確定回歸方程進行模型預測�����。
由于多元回歸方程有多個自變量�,區別于一元回歸方程��,有一項很重要的操作就是自變量的優化�����,挑選出相關性最顯著的自變量�,同時去除不顯著的自變量�����。在R語言中���,有很方便地用于優化函數��,可以很好的幫助我們來改進回歸模型����。
下面就開始多元線性回歸的建模過程�����。
做過商品期貨研究的人���,都知道黑色系品種是具有產業鏈上下游的關系�����。鐵礦石是煉鋼的原材料�����,焦煤和焦炭是煉鋼的能源資源�����,熱卷即熱軋卷板是以板坯為原料經加熱后制成的鋼板���,螺紋鋼是表面帶肋的鋼筋��。
由于有產業鏈的關系�����,假設我們想要預測螺紋鋼的價格��,那么影響螺紋鋼價格的因素可以會涉及到原材料�����,能源資源和同類材料等�。比如����,鐵礦石價格如果上漲����,螺紋鋼就應該要漲價了����。
2.1 數據集和數學模型
先從數據開始介紹�,這次的數據集��,我選擇的期貨黑色系的品種的商品期貨�����,包括了大連期貨交易所的 焦煤(JM)��,焦炭(J)��,鐵礦石(I)���,上海期貨交易所的 螺紋鋼(RU) 和 熱卷(HC)���。
數據集為2016年3月15日��,當日白天開盤的交易數據�����,為黑色系的5個期貨合約的分鐘線的價格數據�����。

數據集包括有6列:索引, 為時間
x1, 為焦炭(j1605)合約的1分鐘線的報價數據
x2, 為焦煤(jm1605)合約的1分鐘線的報價數據
x3, 為鐵礦石(i1605)合約的1分鐘線的報價數
x4, 為熱卷(hc1605)合約的1分鐘線的報價數據
y, 為螺紋鋼(rb1605)合約的1分鐘線的報價數據
假設螺紋鋼的價格與其他4個商品的價格有線性關系�,那么我們建立以螺紋鋼為因變量��,以焦煤����、焦炭�����、鐵礦石和熱卷的為自變量的多元線性回歸模型�。用公式表示為:

y�,為因變量���,螺紋鋼
x1����,為自變量�����,焦煤
x2��,為自變量���,焦炭x3��,為自變量��,鐵礦石
x4�����,為自變量�,熱卷
a���,為截距
b,c,d,e���,為自變量系數
ε, 為殘差�,是其他一切不確定因素影響的總和��,其值不可觀測�。假定ε服從正態分布N(0,σ^2)�����。
通過對多元線性回歸模型的數學定義�,接下來讓我們利用數據集做多元回歸模型的參數估計����。
2.2. 回歸參數估計
上面公式中��,回歸參數 a, b, c, d,e都是我們不知道的����,參數估計就是通過數據來估計出這些參數���,從而確定自變量和因變量之前的關系����。我們的目標是要計算出一條直線��,使直線上每個點的Y值和實際數據的Y值之差的平方和最小����,即(Y1實際-Y1預測)^2+(Y2實際-Y2預測)^2+ …… +(Yn實際-Yn預測)^2 的值最小��。參數估計時��,我們只考慮Y隨X自變量的線性變化的部分�����,而殘差ε是不可觀測的��,參數估計法并不需要考慮殘差��。
類似于一元線性回歸�,我們用R語言來實現對數據的回歸模型的參數估計���,用lm()函數來實現多元線性回歸的建模過程���。

這樣我們就得到了y和x關系的方程�。

2.3. 回歸方程的顯著性檢驗
參考一元線性回歸的顯著性檢驗�����,多元線性回歸的顯著性檢驗��,同樣是需要經過 T檢驗�����,F檢驗����,和R^2(R平方)相關系統檢驗�。在R語言中這三種檢驗的方法都已被實現�����,我們只需要把結果解讀��,我們可以summary()函數來提取模型的計算結果��。

T檢驗:所自變量都是非常顯著***
F檢驗:同樣是非常顯著�,p-value < 2.2e-16
調整后的R^2:相關性非常強為0.972
最后�����,我們通過的回歸參數的檢驗與回歸方程的檢驗���,得到最后多元線性回歸方程為:

2.4 殘差分析和異常點檢測
在得到的回歸模型進行顯著性檢驗后���,還要在做殘差分析(預測值和實際值之間的差)���,檢驗模型的正確性��,殘差必須服從正態分布N(0,σ^2)�。直接用plot()函數生成4種用于模型診斷的圖形����,進行直觀地分析�。
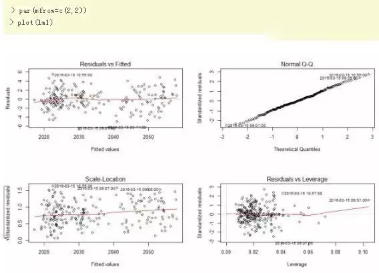
殘差和擬合值(左上)����,殘差和擬合值之間數據點均勻分布在y=0兩側�����,呈現出隨機的分布�����,紅色線呈現出一條平穩的曲線并沒有明顯的形狀特征���。
殘差QQ圖(右上)�,數據點按對角直線排列�,趨于一條直線�,并被對角直接穿過���,直觀上符合正態分布�����。
標準化殘差平方根和擬合值(左下)����,數據點均勻分布在y=0兩側���,呈現出隨機的分布����,紅色線呈現出一條平穩的曲線并沒有明顯的形狀特征�。
標準化殘差和杠桿值(右下)�,沒有出現紅色的等高線��,則說明數據中沒有特別影響回歸結果的異常點��。
結論��,沒有明顯的異常點�����,殘差符合假設條件�����。
2.5. 模型預測
我們得到了多元線性回歸方程的公式����,就可以對數據進行預測了�。我們可以用R語言的predict()函數來計算預測值y0和相應的預測區間�,并把實際值和預測值一起可視化化展示���。
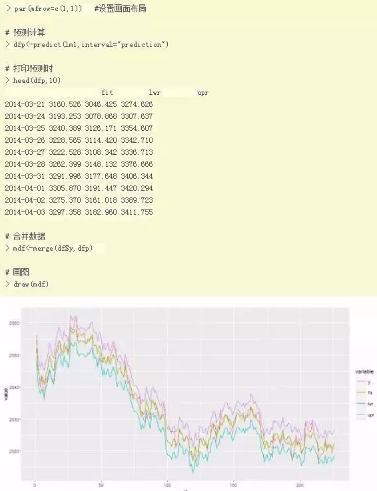
圖例說明:
y, 實際價格�����,紅色線
fit, 預測價格�����,綠色線
lwr���,預測最低價�����,藍色線
upr�,預測最高價��,紫色線
從圖中看出����,實際價格y和預測價格fit����,在大多數的時候都是很貼近的����。我們的一個模型就訓練好了!
3. 模型優化
上文中��,我們已經很順利的發現了一個非常不錯的模型�����。如果要進行模型優化�,可以用R語言中update()函數進行模型的調整�。我們首先檢查一下每個自變量x1,x2,x3,x4和因變量y之間的關系��。
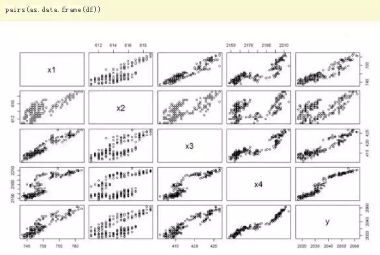
從圖中��,我們可以發現x2與Y的關系����,可能是最偏離線性的�。那么���,我們嘗試對多元線性回歸模型進行調整�,從原模型中去掉x2變量�。

當把自變量x2去掉后�,自變量x3的T檢驗反而變大了���,同時Adjusted R-squared變小了�,所以我們這次調整是有問題的���。
如果通過生產和原材料的內在邏輯分析��,焦煤與焦炭屬于上下游關系����。焦煤是生產焦炭的一種原材料����,焦炭是焦煤與其他煉焦煤經過配煤焦化形成的產品�,一般生產 1 噸焦炭需要1.33 噸煉焦煤�����,其中焦煤至少占 30% �����。
我們把焦煤 和 焦炭的關系改變一下���,增加x1*x2的關系匹配到模型���,看看效果�。
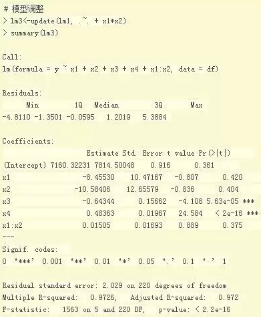
從結果中發現��,增加了x1*x2列后�����,原來的x1,x2和Intercept的T檢驗都不顯著�����。繼續調整模型���,從模型中去掉x1,x2兩個自變量�����。

從調整后的結果來看�,效果還不錯�。不過��,也并沒有比最初的模型有所提高��。
對于模型調整的過程�,如果我們手動調整測試時�,一般都會基于業務知識來操作���。如果是按照數據指標來計算�,我們可以用R語言中提供的逐步回歸的優化方法����,通過AIC指標來判斷是否需要參數優化���。

通過計算AIC指標��,lm1的模型AIC最小時為324.51���,每次去掉一個自變量都會讓AIC的值變大���,所以我們還是不調整比較好��。
對剛才的lm3模型做逐步回歸的模型調整�����。

通過AIC的判斷�����,去掉X1*X2項后AIC最小���,最后的檢驗結果告訴我們����,還是原初的模型是最好的���。
4. 案例:黑色系期貨日K線數據驗證
最后�����,我們用上面5個期貨合約的日K線數據測試一下���,找到多元回歸關系�。

數據集的基本統計信息��。
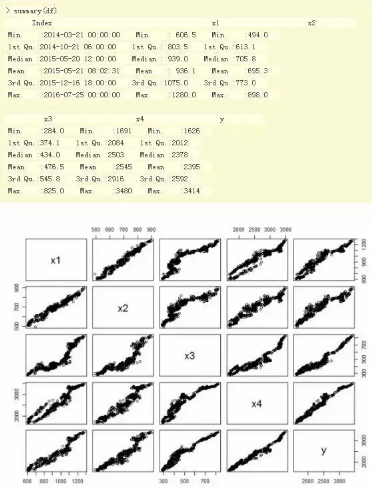
對于日K線數據����,黑色系的5個品種����,同樣具有非常強的相關關系���,那么我們就可以把這個結論應用到實際的交易中了�����。
本文通過多元回歸的統計分析方法��,介紹多元回歸在金融市場的基本應用�。我們通過建立因變量和多個自變量的模型�,從而發現生活中更復雜的規律�,并建立有效的驗證指標�。讓我們的技術優勢��,去金融市場搶錢吧�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
