SPSS統計分析案例:多項logistic回歸分析
在實際應用中��,可能還會碰到因變量是多個分類的情況��,并且不包含排序信息����。比如視力分為輕度�、中度���、重度三個水平�����,此時如果想考察與視力評價有關聯的指標�����,常用的二項logistic回歸已經無法勝任����。
幸好�,SPSS軟件為我們提供了多項logistic回歸���。
logistic回歸對數據的要求
因變量:分類變量�,要求是(含)三個以上分類水平�;
自變量:可以是分類變量或連續變量��,建議是分類變量��;
協變量:必須是分類變量�����。
概念什么的�����,先不說��,即使說����,小兵我也說不清楚���,看了案例自然就了解了��。用SPSS學統計的好處就是這��,辣眼睛的統計原理可以通過案例實踐來逐步理解掌握�。
案例數據
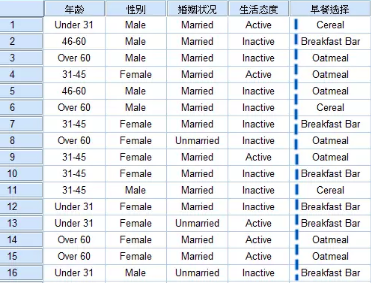
該假設數據文件涉及一份880人參于的關于早餐喜好的民意調查����,該調查記錄了參與者的年齡����、性別��、婚姻狀況以及生活方式是否積極�����,每個個案代表一個單獨的響應者�。
調查機構想搞清楚是什么影響著受訪人每天吃什么早餐����。因變量“早餐選擇”包括(1=早餐攤點��、2=燕麥類�、3=谷物類)����,自變量暫定年齡��、婚姻狀況以及生活態度����。
分步驟說明
菜單欄中依次選擇【分析】【回歸】【多項logistic】���,打開主面板��。
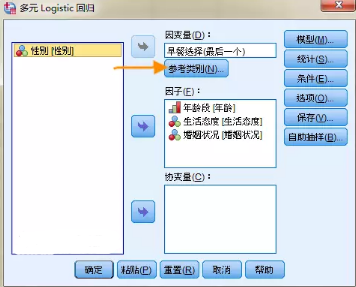
因變量�、自變量分別按照箭頭指示移入對應的變量框內��,然后最為重要的是����,點擊【參考類別】按鈕����,默認勾選【最后一個類別】�����。
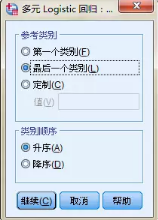
什么意思呢����?大意是指以因變量和自變量的最后一個分類水平為參照�,用其他分類依次與之對比�,考察不同水平間的傾向��。
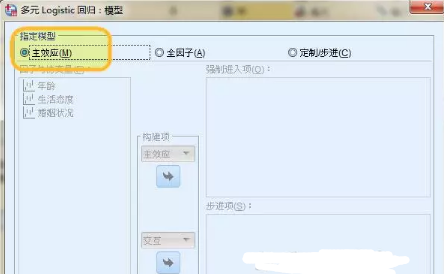
主面板中����,點擊【模型】按鈕��,打開【多項logistic回歸:模型】對話框��,勾選【主效應】���,本例主要考察自變量年齡����、性別��、婚姻狀況的主效應�,暫不考察它們之間的交互作用��,然后點擊【繼續】���。
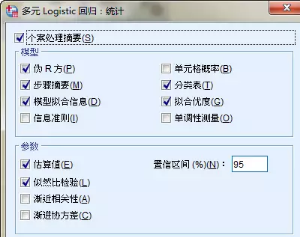
主面板中�����,點擊【統計】按鈕�����,設置模型的統計量����。主要【偽R方】【模型擬合信息】【分類表】【擬合優度】這幾項必選����,其他可以默認不勾選����。這些參數主要用于說明建模的質量�����。
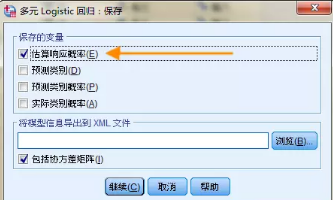
主面板中�����,點擊【保存】按鈕�����,勾選【估算響應概率】��,我們要求SPSS軟件幫我們估算每個個案三類早餐的概率�����。
其余的參數主要和逐步回歸有關系�,本例采用主效應模型���,人為指定進入模型的自變量�,在其他研究中���,可以根據情況選擇逐步回歸��。
下主面板底部點擊【確定】按鈕�,軟件開始執行此處建模���。
多項logistic回歸結果解讀
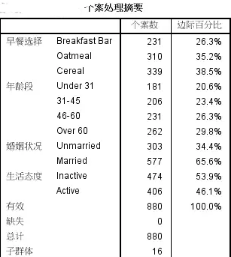
個案處理摘要表���,列出因變量和自變量的分類水平及對應的個案百分比��。建議在此表主要讀取變量分類水平的順序���,比如自變量“年齡段”���,第一個分類是“低于31歲”����,第二個分類是“31-45”����,第三個分類是“45-60”�,第四個分類是“60歲以上”�����,尤其是看清楚最后一個分類����,因為我們前面參數設置時要求是以最后一個分類最為對比參照組的�����。誰和誰對比����,一定要搞清楚�����。
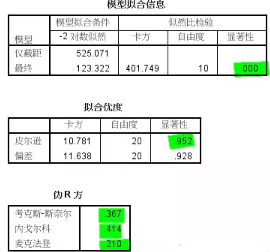
模型擬合信息表����,讀取最后一列�,顯著性值小于0.05�,說明模型有統計意義��,模型通過檢驗�����。
擬合優度表�,原假設模型能很好地擬合原始數據�,最后一列皮爾遜卡方顯著性值0.952���,概率較大����,說明原假設成立����,模型對原始數據的擬合效果良好�����。
偽R方表����,依次列出的3個偽R方值(類似于決定系數)均偏低��,最高0.4���,說明模型對原始變量變異的解釋程度一般�,還有一部分信息無法解釋�,結果不算好���。
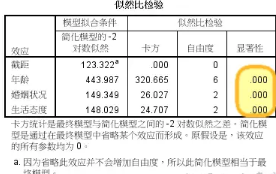
模型似然比檢驗表�,我們能看到最終進入模型的效應包括截距�����、年齡�、婚姻狀況��、生活態度��,而且最后一列顯著性值表明�,三個自變量(影響因素)對模型構成均有顯著貢獻�����,研究它們是有意義的����。
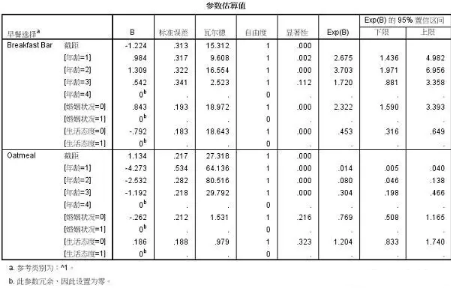
參數估計表����,列出自變量不同分類水平對早餐選擇的影響檢驗�����,是多項logistic回歸非常重要的結果�。
第二列B值�����,即各自變量不同分類水平在模型中的系數�����,正負符號表明它們與早餐選擇是正比還是反比關系��。第六列是瓦爾德檢驗顯著性值�����,此值小于0.05說明對應自變量的系數具有統計意義�����,對因變量不同分類水平的變化有顯著影響��。
比如�����,早餐攤點和谷物類早餐相比�����,31-45歲的年輕人更偏向于選擇在早餐攤點吃早餐���,這種可能性是60歲以上人的3.7倍��;燕麥類和谷物類早餐相比��,結婚與否對早餐的選擇沒有差別����。
除此之外����,我們前面還要求軟件保存了每個個案早餐選擇的概率�����,返回數據編輯器窗口�����,具體來看結果����。
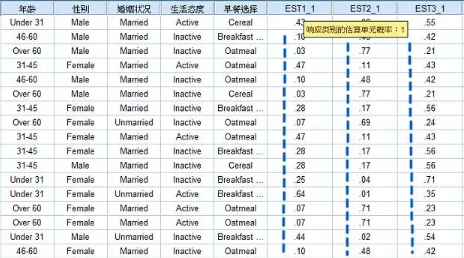
原始數據最右側新增3個變量��,依次為EST1_1�、EST2_1��、EST3_1�����,分別對應因變量“早餐選擇”的三個分類水平(早餐攤�����、燕麥類���、谷物類)的響應概率�����。比如第一個個案��,他選擇谷物類早餐的概率為0.55����,在三種選擇中數值最大�,因此�����,模型會判定他選擇谷物類早餐��,這和原始記錄的真值一致���,說明模型判斷準確����。
當然��,SPSS軟件也輸出了模型預測分類表����,如下所示����。
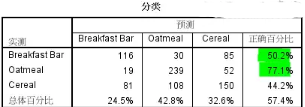
模型在預測燕麥類早餐選擇傾向上準確率最高�����,達到77%�,其他兩個早餐選擇的預測略低��,模型總體預測準確率為57.4%�,表現一般���。前面偽R方數據顯示���,模型對總體變異的解釋能力不足���,這和總體預測準確率結論也一致�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
