《Python數據分析極簡入門》 第2節 8-1 Pandas 數據重塑 - 數據變形 數據重塑(Reshaping) 數據重塑����,顧名思義就是給數據做各種變形���,主要有以下幾種:
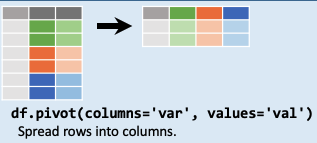
df.pivot( ) 數據變形
根據索引 (index)�����、列(column)(values)值)��, 對原有DataFrame (數據框)進行變形重塑,俗稱長表轉寬表
import pandas as pdimport numpy as npdf = pd.DataFrame ('姓名' : ['張三' , '張三' , '張三' , '李四' , '李四' , '李四' ],'科目' : ['語文' , '數學' , '英語' , '語文' , '數學' , '英語' ],'成績' : [91 , 80 , 100 , 80 , 100 , 96 ]})
姓名
科目
成績
0
張三
語文
91
1
張三
數學
80
2
張三
英語
100
3
李四
語文
80
4
李四
數學
100
5
李四
英語
96
長轉寬:使用 df.pivot 以姓名為index,以各科目為columns����,來統計各科成績:
df = pd.DataFrame ('姓名' : ['張三' , '張三' , '張三' , '李四' , '李四' , '李四' ],'科目' : ['語文' , '數學' , '英語' , '語文' , '數學' , '英語' ],'成績' : [91 , 80 , 100 , 80 , 100 , 96 ]})
姓名
科目
成績
0
張三
語文
91
1
張三
數學
80
2
張三
英語
100
3
李四
語文
80
4
李四
數學
100
5
李四
英語
96
df.pivot(index='姓名' , columns='科目' , values='成績' )
科目
數學
英語
語文
姓名
張三
80
100
91
李四
100
96
80
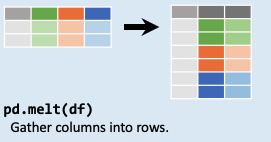
pd.melt() 數據融合 df = pd.DataFrame ('姓名' : ['張三' , '張三' , '張三' , '李四' , '李四' , '李四' ],'科目' : ['語文' , '數學' , '英語' , '語文' , '數學' , '英語' ],'成績' : [91 , 80 , 100 , 80 , 100 , 96 ]})'姓名' , columns='科目' , values='成績' ).reset_index()
科目
姓名
數學
英語
語文
0
張三
80
100
91
1
李四
100
96
80
寬表變長表:使用 pd.melt 以姓名為標識變量的列id_vars,以各科目為value_vars��,來統計各科成績:
df1.melt(id_vars=['姓名' ], value_vars=['數學' , '英語' , '語文' ])
姓名
科目
value
0
張三
數學
80
1
李四
數學
100
2
張三
英語
100
3
李四
英語
96
4
張三
語文
91
5
李四
語文
80
pd.pivot_table() 數據透視 random.seed(1024 )DataFrame ('專業' : np.repeat(['數學與應用數學' , '計算機' , '統計學' ], 4 ),'班級' : ['1班' ,'1班' ,'2班' ,'2班' ]*3 ,'科目' : ['高數' , '線代' ] * 6 ,'平均分' : [random.randint(60 ,100 ) for i in range(12 )],'及格人數' : [random.randint(30 ,50 ) for i in range(12 )]})
專業
班級
科目
平均分
及格人數
0
數學與應用數學
1班
高數
61
34
1
數學與應用數學
1班
線代
90
42
2
數學與應用數學
2班
高數
84
33
3
數學與應用數學
2班
線代
80
43
4
計算機
1班
高數
93
34
5
計算機
1班
線代
66
43
6
計算機
2班
高數
88
45
7
計算機
2班
線代
92
44
8
統計學
1班
高數
83
46
9
統計學
1班
線代
83
41
10
統計學
2班
高數
84
49
11
統計學
2班
線代
66
49
各個專業對應科目的及格人數和平均分
pd.pivot_table(df, index=['專業' ,'科目' ],'及格人數' ,'平均分' ],'及格人數' :np.sum,"平均分" :np.mean})
及格人數
平均分
專業
科目
數學與應用數學
線代
85
85.0
高數
67
72.5
統計學
線代
90
74.5
高數
95
83.5
計算機
線代
87
79.0
高數
79
90.5
補充說明:
df.pivot_table()和df.pivot()都是Pandas中用于將長表轉換為寬表的方法�����,但它們在使用方式和功能上有一些區別�。
使用方式:
df.pivot()方法接受三個參數:index�����、columns和values����,分別指定新表的索引 ���、列和值�����。df.pivot_table()方法接受多個參數�,其中最重要的是index��、columns和values���,用于指定新表的索引 ���、列和值����。此外���,還可以使用aggfunc參數指定對重復值 進行聚合操作的函數�����,默認為均值����。
處理重復值 :
df.pivot()方法在長表中存在重復值 時會引發錯誤�����。因此��,如果長表中存在重復值 ���,就需要先進行去重操作�,或者使用其他方法來處理重復值 ��。df.pivot_table()方法可以在長表中存在重復值 的情況下進行透視操作�,并可以使用aggfunc參數指定對重復值 進行聚合操作的函數�,默認為均值�。
聚合操作:
df.pivot()方法不支持對重復值 進行聚合操作�����,它只是簡單地將長表中的數據轉換 為寬表���。df.pivot_table()方法支持對重復值 進行聚合操作����?���?梢允褂?code style="font-size: 14px; word-wrap: break-word; padding: 2px 4px; border-radius: 4px; margin: 0 2px; color: #1e6bb8; background-color: rgba(27,31,35,.05); font-family: Operator Mono, Consolas, Monaco, Menlo, monospace; word-break: break-all;">aggfunc參數來指定聚合函數����,例如求均值����、求和��、計數等�。
總的來說����,df.pivot()方法適用于長表中不存在重復值 的情況����,而df.pivot_table()方法適用于長表中存在重復值 的情況�,并且可以對重復值 進行聚合操作�����。根據具體的數據結構 和分析需求�����,選擇合適的方法來進行轉換操作�����。











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
